







前言
本文是在讲述什么样的数据结构适合作为索引,以及其适合作为索引的原因。而阅读本文需要对B树和B+树结构有稍微的理解。以及需要对磁盘操作知识有稍微的了解。
什么是索引
索引(Index)是帮助数据库高效获取数据的数据结构。索引是在基于数据库表创建的,它包含一个表中某些列的值以及记录对应的地址,并且把这些值存储在一个数据结构中。最常见的就是使用哈希表、B+树作为索引。
为什么要使用索引
我们知道,数据库查询是数据库最主要的功能之一。而查询速度当然是越快越好。而当数据量越来越大的时候,查询花费的时间会随之增长。而索引,可以加速数据的查询。因为索引是有序排列的。
数据库中使用什么数据结构作为索引
我们知道,数组+二分查找的效率是O(lgn),但是数组的插入元素以及删除元素的效率很低,因此使用数组做为索引结构并不合适。
另外,在选择数据库索引的结构的时候,要考虑到另一个问题。索引是存在于磁盘中,当索引非常大的时候,达到几个G的时候,无法一次加载到内存中。
考虑到上面两个因素,数据库中索引使用的是树形结构。
各种树的名字
有这么几种树:
B-Tree
B+-Tree
B*-Tree
首先要明白三种树名中的“-”起到的是分隔的作用,并不是“减”的意思。
因此正确的翻译应该是B树,B+树,B*树。而不是B-树,B+树,B*树。因此,当你听到别人说“B减树”的时候,要明白它指的是B-Tree。即B树和B-树是同一种树。
二叉树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
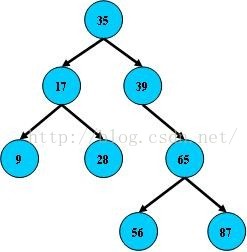
二叉树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果二叉树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么二叉树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变二叉树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
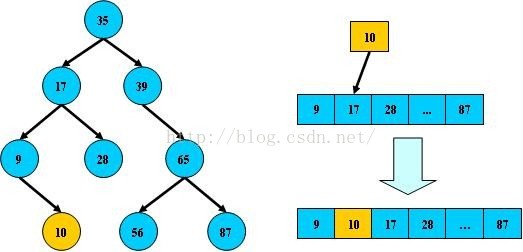
但二叉树在经过多次插入与删除后,有可能导致不同的结构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









