







正则表达式介绍
又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
正则表达式简单使用
假设你使用爬虫在网站上爬到此内容,该如何快速的获取到这段内容中的英文字母或者是数字?这个时候就用到了正则表达式
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆 于1990 年代初设计,作为一门叫做ABC语言的替代品。 [1] Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言, [2] 随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。 [3] Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型。 [4] Python 也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码。 [4] 2021年10月,语言流行指数的编译器Tiobe将Python加冕为最受欢迎的编程语言,20年来首次将其置于Java、C和JavaScript之上。
package regularexpression;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularExpression {
public static void main(String[] args) {
//假定使用爬虫爬取到了此内容
String context = "Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆 于1990 年代初设计," +
"作为一门叫做ABC语言的替代品。 [1] Python提供了高效的高级数据结构,还能简单有效地面" +
"向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速" +
"开发应用的编程语言, [2] 随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目" +
"的开发。 [3] "+"Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)" +
"扩展新的功能和数据类" +
"型。 [4] Python 也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于" +
"个主要系统平台的源码或机器码。 [4] " +
"2021年10月,语言流行指数的编译器Tiobe将Python加冕为最受欢迎的编程语言,20年来首次将其置" +
"于Java、C和JavaScript之上。 [16] ";
//提取文章中所有的英文单词
//先创建一个Pattern对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");
//创建一个匹配对象
//就是matcher 匹配器按照pattern模式理赔,到context文本中去匹配
//找到就返回true 没有找到就返回false
Matcher matcher = pattern.matcher(context);
//开始匹配
while (matcher.find()){
//匹配到的内容会在matcher.group(0)中
System.out.println("找到 " + matcher.group(0));
}
}
}
运行结果为

当我们需要获取文本中的数字时,只需要把这个语句
Pattern pattern = Pattern.compile("[a-zA-Z]+");
替换为
Pattern pattern = Pattern.compile("[0-9]+");
运行结果为

如果要抓取年份相关的则将
Pattern pattern = Pattern.compile("[0-9]+");
替换为
\ \d表示任意的数字
Pattern pattern = Pattern.compile(""\\d\\d\\d\\d"");
运行结果为
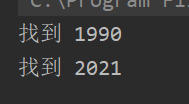
分析
martch.find()完成的任务
- 根据规则,定位到满足规则的子字符串
- 找到后,将紫子非常的开始的索引记录到
matcher对象属性int[] groups;groups[0] = 31,把该字字符串的借宿的索引+1的值记录到groups[1] = 35
在此进行断点调试,发现确实有一个groups

当我们在往前走一步时候发现groups数组中 groups[0] = 31 groups[1] = 35
正好是1990在文本中的索引位置。

- 同时会记录
oldLast的值,为子字符串结束的索引+1 的值即为35 ,即下次执行find时候,就从35这个位置开始匹配。

march.group(0) 分析
我们通过group的源码
public String group(int group) {
if (this.first < 0) {
throw new IllegalStateException("No match found");
} else if (group >= 0 && group <= this.groupCount()) {
return this.groups[group * 2] != -1 && this.groups[group * 2 + 1] != -1 ? this.getSubSequence(this.groups[group * 2], this.groups[group * 2 + 1]).toString() : null;
} else {
throw new IndexOutOfBoundsException("No group " + group);
}
}
- 根据
groups[0] = 31和groups[1] = 35记录的位置,从content开始截取字符串放回 。即返回的是[31,35)区间中的索引的位置。 - 如果继执行
find方法 仍然按照上面的规则执行。
当将
Pattern pattern = Pattern.compile(""\\d\\d\\d\\d"");
改为分组的时候,有第一个一个括号就是第一组,第二个括号就是第二组。
Pattern pattern = Pattern.compile("(\\d\\d)(\\d\\d)");
-
根据规则,定位到满足规则的子字符串
-
找到后,将紫子非常的开始的索引记录到 matcher对象属性 int[] groups; groups[0] = 31 ,把该字符串的索引+1的值记录到
groups[1] = 35。 -
记录第一组()匹配到的字符串
groups[2] = 31groups[3] = 33因为匹配到的字符串为 1980 所以19为第一组所在的位置,又因为1所在的索引为 31,9 所在的索引为32所以groups[2] = 31 groups[3] = 33
-
记录第二组()匹配到的字符串
groups[3] = 33groups[4] = 35 -
如果有更多的分组以此类推
如图

将while中的代码修改为
while (matcher.find()){
//匹配到的内容会在matcher.group(0)中
System.out.println("找到 " + matcher.group(0));
System.out.println("第一组()匹配的是 " + matcher.group(1));
System.out.println("第二组()匹配的是 " + matcher.group(2));
}
运行结果为
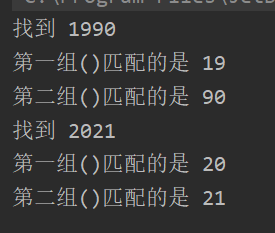
小结:如果正则表达式有()即分组,取出的字符串规则为 group(0) 表示匹配到的字符串,group(1) 表示匹配到的子字符串中的第一组字符,group(2) 表示匹配到的子字符串中的第二组字符。注意!!分组的数不能越界。
















 6596
6596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











