







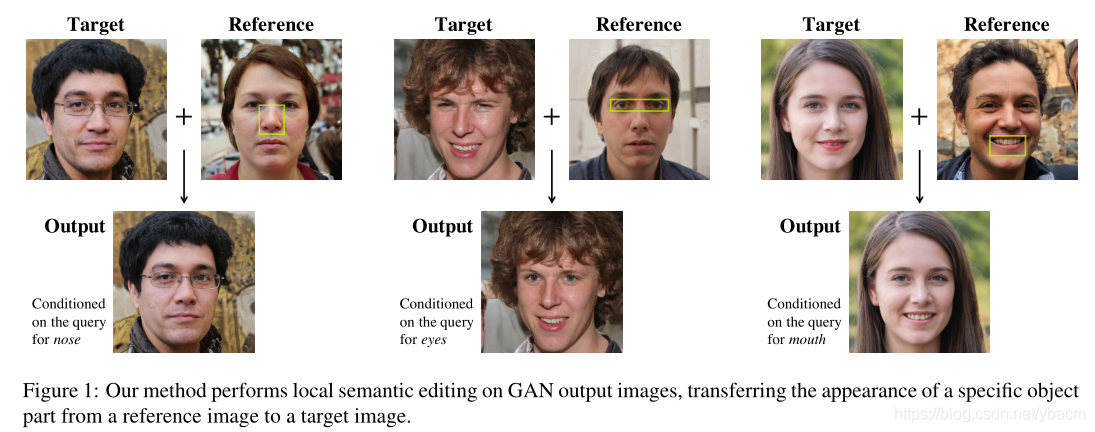
Editing in Style: Uncovering the Local Semantics of GANs
作者:Edo Collins, Sabine Süsstrunk{School of Computer and Communication Sciences, EPFL, Switzerland}, Raja Bala, Bob Price{Interactive and Analytics Lab, Palo Alto Research Center, Palo Alto, CA}
会议:CVPR 2020
论文:https://openaccess.thecvf.com/content_CVPR_2020/papers/Collins_Editing_in_Style_Uncovering_the_Local_Semantics_of_GANs_CVPR_2020_paper.pdf
代码:https://github.com/IVRL/GANLocalEditing
Abstract
虽然近几年来GAN图像合成的质量有了巨大的提高,但我们控制和调节输出的能力仍然有限。聚焦于StyleGAN,我们介绍了一种简单有效的方法,用于对目标输出图像(target output image)进行局部的、语义感知的编辑。这是从源图像(也是一个GAN输出)中借用elements,然后使用一种新颖的风格向量操作来完成的。我们的方法既不需要外部模型的监督,也不涉及复杂的空间变形操作。相反,它依赖于语义对象的解纠缠程度,这是StyleGAN在训练过程中学习到的。语义编辑可以应用在生成人脸、室内场景、猫和汽车的GANs上。由我们的方法进行语义编辑可以达到图像的局部性(比如只改变眼睛的语义)和逼真性。
1. Introduction
解纠缠的意思就是不让每个语义的特征交叠纠缠,最好能获得每个语义的完整且不交叠的特征。
在本文中,我们展示了深度生成模型,如PG-GAN、StyleGAN和最近的StyleGAN2 [17]学习的对象(objects)和对象部分(object-parts)的表征,即各种语义部分(例如,人的嘴或卧室中的枕头)具有独立于场景其余部分的显著变化能力。
基于这一观察,我们提出了一种算法,该算法对GANs(主要是StyleGAN)的输出执行 空间定位语义编辑(spatially-localized semantic editing)。编辑是通过将语义化的局部样式从参考图像转移到目标图像来执行的,两者都是GAN的输出。我们的方法简单而有效,只需要一个离线的预训练好的GAN。我们的方法是特殊的,因为它通过一个全局的操作,类似于风格迁移,实现了局部化的改变。因此,不同于其他使用额外数据集和训练网络的GAN编辑方法,或者需要复杂空间操作的传统图像变形方法,我们的方法依赖于GAN本身学习的丰富语义表征并从中受益。通过将我们的方法与最近将自然图像嵌入StyleGAN的潜空间的工作相结合,可以设想扩展到真实图像的语义编辑[1,17]。
我们做出以下贡献:
- 我们提供了对StyleGAN生成器的隐藏激活值(特征图)结构的洞察,表明学习到的表征在很大程度上与合成图像中的语义对象是解纠缠的(disentangled)。
- 我们利用这种结构来开发一种新颖的图像编辑器,它可以从参考图像到目标合成图像的语义部分转移。基础公式简单而优雅,无需复杂的空间处理或额外训练数据和模型的监督,即可实现自然的语义转移。
论文结构如下。在第2节中,我们回顾了与GAN编辑和可解释性相关的工作。在第三节中,我们详细介绍了我们对GAN潜空间中空间解纠缠的观察,并介绍了我们的局部编辑方法。在第4节中,展示了验证我们想法的实验结果,在第5节中,我们以对结果和未来工作的讨论结束。
2. Related Work
2.1. GAN-based Image Editing
有一些工作探索了生成模型在语义图像编辑中的应用。我们将其分为两种类型:用于全局属性编辑的基于潜代码的方法和用于局部编辑的基于激活值的方法。
基于潜编码的技术是在GAN的潜编码空间中学习自然图像流形,并通过沿着该流形遍历路径来执行语义编辑[23,32]。该框架的一个变体采用自动编码器将图像分解为语义子空间并重建图像,从而促进沿单个子空间进行语义编辑[2,25]。这些技术完成的编辑示例包括颜色、照明、姿势、面部表情、性别、年龄、头发外观、眼镜和头饰的全局变化[2,19,25,30,31]。AttGAN[10]使用带有外部属性分类器的监督学习来完成属性编辑。
基于激活值的局部编辑技术是直接操纵生成器特定卷积层上激活张量上的特定空间位置。通过这种方式,GAN Dissection[3]控制给定位置上物体的存在或不存在,由一个独立的语义分割模型监督。类似地,feature blending[26]通过从参考图像“复制粘贴(copy-pasting)”激活值到目标GAN输出上来实现传输对象。我们将该技术与传统的Poisson blending[24]以及图5中我们的方法进行了比较。
与所有这些工作不同,我们的方法是一种基于潜编码的局部编辑方法。最重要的是,它既不依赖图像分割模型的外部监督,也不涉及复杂的空间混合操作。相反,我们在生成器的嵌入空间中发现本来就可以进行空间局部编辑,并利用了此解纠缠结构。
2.2 Face Swapping
3. Local Semantics in Generative Models
3.1. Feature factorization
深度特征分解(Deep feature factorization, DFF)[6]是一种最近的方法,它解释了卷积神经网络(CNN)通过一组显著性映射(saliency maps)学习表征,通过分解一个隐含层激活值矩阵提取。有了这样的分解,证明针对ImageNet训练分类的CNNs可以学习语义对象(semantic object)和对象部分(object-part)检测器的特征。
受此启发,我们对生成模型如PGGAN、StyleGAN和StyleGAN2的激活值情况进行了类似的分析。具体来说,我们将球形k-means聚类[5]应用于在生成器给定层中构成激活值张量 A ∈ R N × C × H × W A∈\R^{N×C×H×W} A∈RN×C×H×W的C维激活值向量,其中N为图像数,C为通道数,H, W为空间维数。聚类生成一个聚类隶属度张量(a tensor of cluster membership) U ∈ { 0 , 1 } N × K × H × W U∈\{0,1\}^{N×K×H×W} U∈{0,1}N×K×H×W,其中K是用户定义的,每个K维向量是一个one-hot向量,表示激活张量中的某个空间位置属于K个簇中的哪个。
这种分析的主要结果是,在生成器的某些层上,聚类可以与语义对象和对象部分很好地对应。图2显示了在FlickrFaces-HQ (FFHQ)[16]和LSUN-Bedrooms[29]上训练的32 × 32层StyleGAN生成器网络产生的簇。heatmap中的每个像素都用颜色编码,以表示其簇。可以看出,聚类在空间上跨越了连贯的语义对象和对象部分(clusters spatially span coherent semantic objects and object-parts),如眼睛、鼻子和嘴代表的是脸,床、枕头和窗户代表的是卧室。

以U编码的聚类关系可以让我们计算通道c对每个语义聚类k的贡献 M k , c M_{k,c} Mk,c,如下:
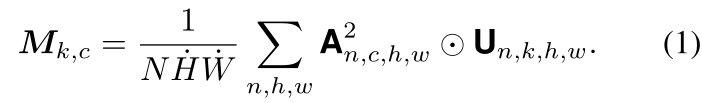
假设 A l A_l Al的特征图有零均值和单位方差,每个通道的贡献在0到1之间,即 M ∈ [ 0 , 1 ] K × C M∈[0,1]^{K×C} M∈[0,1]K×C。
此外,通过双线性的向上或向下采样张量U的空间维度到适当的大小,我们能够找到一个对应于生成器所有层相同语义簇的矩阵M。
使用这种方法,我们为每个GAN生成了一个语义目录。在定性评价聚类隶属度图的指导下,我们选择在哪个层和用哪个K来应用球形K均值。这个过程只需要几分钟的人工监督。
3.2. Local editing
3.2.1 StyleGAN overview
这种基于样式的控制机制是受风格迁移[8]、[20]所启发的,其显示了操作每个通道的平均值和方差足以控制图像[14]的样式。通过将StyleGAN生成器的输入固定为不变的编码,StyleGAN的作者表明,这种机制可以确定(控制)生成图像的所有方面:一层的样式决定下一层的内容。

3.2.2 Conditioned interpolation
给定一个目标图像S和参考图像R,都为GAN的输出,我们想从R到S迁移指定的外观局部对象或部分,从而创建编辑后的图像G。让 σ S σ^S σS和 σ R σ^R σR为对应两张图片的相同层的两个风格的缩放系数。
对于全局迁移,由于StyleGAN的潜空间表现出的线性和可分性,由 σ S σ^S σS和 σ R σ^R σR之间的线性插值产生的混合样式 σ G σ^G σG在两个图像之间会产生合理的流体变形:
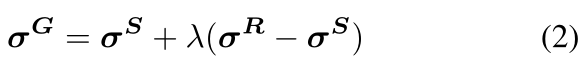
其中 0 ≤ λ ≤ 1 0\leq \lambda \leq 1 0≤λ≤1。这样做可以迁移 σ R σ^R σR中的所有属性到 σ G σ^G σG中,甚至不让 σ S σ^S σS留下任何痕迹。
为了启用可选择性的局部编辑,我们用矩阵变换控制样式插值:
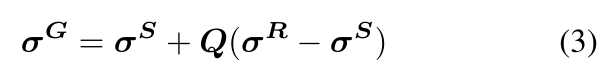
其中矩阵Q是正的半正定矩阵,用其来影响 σ S σ^S σS到 σ R σ^R σR的局部风格迁移。在实践中,我们选择Q为一个对角矩阵,其元素形式为 q ∈ [ 0 , 1 ] C q∈[0,1]^C q∈[0,1]C,我们称之为查询向量。
3.2.3 Choosing the query
对于局部编辑,查询q的适当选择应是倾向于影响感兴趣区域(region of interest, ROI)的通道,而忽略对ROI之外有影响的通道。
当使用3.1节中计算的语义簇所指定的ROI时,假设k ', 向量 M k ′ , c M_{k',c} Mk′,c可以准确地编码该信息。
一种简单的方法是使用 M k ′ , c M_{k',c} Mk′,c,对给定的图像类型和数据集从等式(1)中脱机计算,从而控制插值的斜率,在1处剪切:
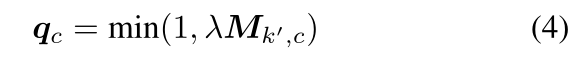
其中 q c q_c qc是q和λ的第c个通道元素,如公式(2)所示,为插值的全局强度。我们称这种方法为simultaneous,因为它同时更新所有的通道。直观地,当λ为小值或中间值时,具有大 M k ′ , c M_{k',c} Mk′,c的通道将具有更高的权重,从而具有定位插值的效果。
我们提出了一种方法,实现了优于等式(4)的局部化,简称sequential。我们首先将最相关的通道设置为最大斜率1,然后升高第二最相关、第三最相关等的斜率。该查询定义对应于解决以下目标:
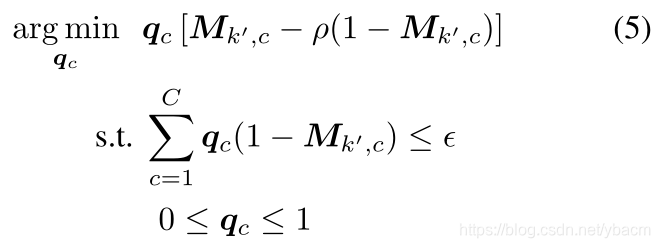
我们通过基于 M k ’ M_{k’} Mk’对通道进行分类来解决这个问题,并贪婪地将 q c = 1 q_c= 1 qc=1分配给最相关的通道,只要ROI之外的总效果不超过某个预算 ϵ \epsilon ϵ。此外,非零权重仅分配给 M k ′ , c > ρ 1 + ρ M_{k′,c}>\frac{ρ}{1+ρ} Mk′,c>1+ρρ的通道,这通过忽略不相关的通道提高了局部编辑的鲁棒性,即使当预算 ϵ \epsilon ϵ有更多的改变时。

4. Experiments
4.1. Qualitative evaluation
在图3和图4中,我们用在两个数据集上训练好的StyleGAN生成器展示了我们的编辑方法:FFHQ[16]包括70K面部图像,LSUN-卧室[29]包括描绘卧室的大约3M彩色图像。
在这两个数据集中,我们发现生成器的第一个32 × 32分辨率层是“最语义的”(应该是最能分辨出不同的语义特征吧)。因此,我们选择这个层来应用球形k-means聚类。我们设置 ρ \rho ρ满足 ρ 1 + ρ = 0.1 \frac{\rho}{1+\rho}=0.1 1+ρρ=0.1以及微调 20 ≤ ϵ ≤ 100 20\leq \epsilon \leq 100 20≤ϵ≤100来获取最佳性能。我们发现 ϵ \epsilon ϵ的调优主要取决于目标图像和感兴趣的对象,而不是风格参考。请注意,根据局部编辑的性质,对目标图像的更改可能是微妙的,最好在屏幕上放大查看。
图5将我们的方法与特征级混合[26]和像素级(泊松)混合[24]方法进行了比较,显然它们的输出缺乏真实感。相比之下,我们的编辑方法主要影响感兴趣区域,但通过允许一些必要的全局变化来保持基线GAN的照片真实感。然而,我们的方法并不总是“忠实地”复制对象的外观,如图4的窗口行所示。

图6展示了我们的方法对最近在LSUN-cat和LSUN-Cars上训练的StyleGAN2模型[17]的适用性[29]。与传统的混合方法不同,我们的技术能够在未对齐的图像之间转移部分,如图4所示。

4.2. Quantitative analysis
我们从局部性和照片真实性两个方面对编辑结果进行量化评估。
4.3. Locality
为了评估编辑的局部性,我们计算了目标图像和它们的编辑输出之间的像素空间的平方误差。图7 (a)显示了在FFHQ的50K样本上平均的未编辑和编辑图像之间的差异,其中在每个像素位置,我们计算CIELAB颜色空间中的平方距离。这个数字表明,迁移是可察觉的和局部的,并不是所有的物体部分都是一样的。与眼睛和嘴相比,眼睛和嘴的编辑非常局部化,编辑鼻子似乎会强制与其他面部部分建立微妙的关联。这种相关性权衡了对单个部分外观的控制与整体输出的合理性和真实性。
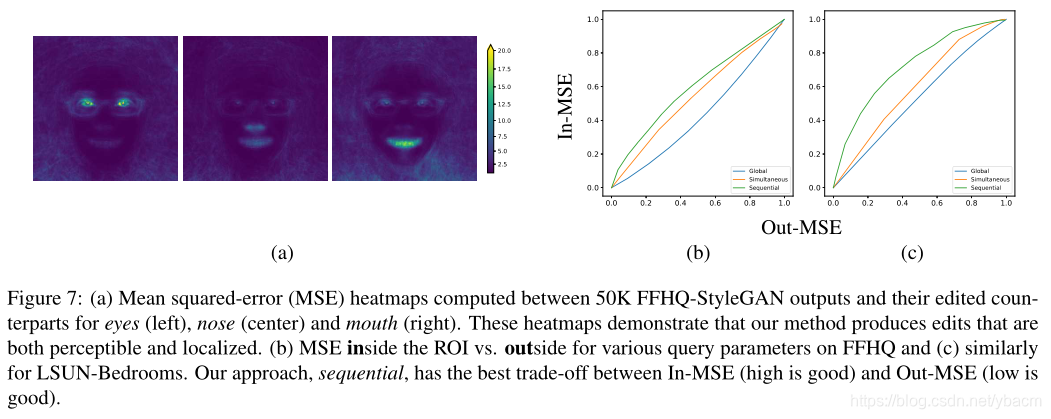
我们进一步检查了我们的方法和3.2节中描述的变体的定位能力。首先,我们使用第3.1节中预先计算的球形k-means聚类,为每幅图像获得给定感兴趣区域的二进制掩码。然后,我们用λ (等式2和4)和 ϵ \epsilon ϵ (等式5)的各种值执行插值。对于每个这样的设置,我们测量每个目标输出对的(标准化的)内均方误差和外均方误差,即感兴趣区域内的均方误差和感兴趣区域外的均方误差。在图7 (b)和©中,我们分别显示了对于FFHQ和LSUN-卧室,我们的方法(sequential)具有更好的定位,即,对于ROI内相同的变化量,ROI外的变化更少。
4.4. Photorealism
测量照片真实感是具有挑战性的,因为还没有一种直接的计算方法来评估图像的照片真实感。FID[11]已被证明与人类的判断有很好的相关性,并已成为评估的标准度量。
我们编辑的图像与基线GAN的普通输出没有显著差异。

然而,当我们计算用特征混合编辑的50K FFHQ图像的FID时,获得了相同的结果[26],尽管图5定性地显示这些产生的输出缺乏照片真实感。**这再次强调了以自动化方式正确测量照片真实性的困难。**我们没有用泊松混合进行类似的分析,因为我们用这种方法观察到的许多失败案例不能证明处理大量1024×1024图像所需的大量计算成本是合理的。对于特征混合和泊松编辑,我们无法测试卧室数据集,因为这些方法不适用于未对齐的图像对。
5. Conclusion
我们已经证明了StyleGAN的潜表征在空间上解开了语义对象和部分。我们利用这一发现介绍了一种在StyleGAN图像中编辑局部语义部分的简单方法。核心思想是让潜对象表征来指导样式插值,以产生真实的部分迁移,而不引入StyleGAN中没有的东西。结果的局部性取决于一个对象的表征从其他对象表征中分离出来的程度,这在StyleGAN的情况下是很关键的。重要的是,我们的技术不涉及语义分割模型的外部监督,或者复杂的空间操作。
整体有些偏数学化,没太看懂。。可以看看这篇博客的总结https://www.cnblogs.com/Xuang/p/13162716.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









