







 提出一种新的图像合成方法——空间自适应规范化(SPADE),通过学习输入语义布局的空间自适应转换来调制标准化层中的激活,有效传播语义信息并支持多模态和风格导向的图像合成。
提出一种新的图像合成方法——空间自适应规范化(SPADE),通过学习输入语义布局的空间自适应转换来调制标准化层中的激活,有效传播语义信息并支持多模态和风格导向的图像合成。
Semantic Image Synthesis with Spatially-Adaptive Normalization
作者:Taesung ParkP{UC Berkeley}, Ming-Yu Liu{NVIDIA}, Ting-Chun Wang{NVIDIA}, Jun-Yan Zhu{NVIDIA, MIT CSAIL}
会议:CVPR 2019
论文:https://arxiv.org/abs/1903.07291 (这篇论文在CVPR官方下载的pdf,里面的文字无法选中,在arxiv中下载的可以选中,比较方便)
代码:https://github.com/NVlabs/SPADE
视频:https://www.youtube.com/watch?v=9GR8V-VR4Qg&t=613
Abstract
我们针对给定语义生成图像提出了空间自适应的标准化(spatially-adaptive normalization),一个简单而高效的层。过去的方法直接将语义分布输入到网络,并经过层层卷积、标准化和非线性层。我们表明这是次优的(不是最优的),因为标准化层倾向于“洗掉”语义信息。为了解决这个问题,我们提出使用input layout,通过空间自适应学习到的转换(transformation)来调制标准化层中的激活。我们的模型允许用户控制语义和风格。
1. Introduction
为了解决这个问题,我们提出了空间自适应规范化,这是一个条件标准化层,它通过空间自适应学习到的转换使用输入语义布局来调整激活值,并可以有效地在整个网络中传播语义信息。
最后,我们的方法支持多模态和风格导向的图像合成,支持可控的、多样的输出,如图1所示。另外,请查看我们的SIGGRAPH 2019实时直播演示 demo。

2. Related Work
Deep generative models 我们的工作建立在GANs的基础上,但目标是有条件的图像合成任务。
Conditional image synthesis
Unconditional normalization layers 例如AlexNet中的本地响应标准化[29]和Inception-v2网络中的批处理标准化都为无条件标准层
Conditional normalization layers 条件标准化层包括条件批处理标准化(Conditional BatchNorm条件批处理模式)[11]和自适应实例标准化(Adaptive Instance Normalization, AdaIN) [19]。这两种方法最初都用于风格迁移任务,后来被用于各种视觉任务[3,8,10,20,26,36,39,42,49,54]。与早期的规范化技术不同,条件规范化层需要外部数据,通常操作如下。首先,层激活被标准化为零均值和单位偏差。然后,通过使用学习的仿射变换调制激活来反标准化(denormalized)标准化的(normalized)激活,仿射变换的参数是从外部数据推断的。对于风格迁移style transfer任务[11,19],仿射参数用于控制输出的全局样式,因此在空间坐标上是一致的。相比之下,我们提出的标准化层应用了一个空间变化的仿射变换,使其适用于从语义信息(semantic masks)的图像合成。王等人提出了一种与之密切相关的图像超分辨率方法[49]。这两种方法都建立在以语义输入为条件的空间自适应调制层(spatially-adaptive modulation layers)上。他们的目标是将语义信息生成超分辨率的图像,我们的目标是设计一种用于样式(style)和语义解耦(semantics disentanglement)的生成器。我们专注于在调节标准化激活的上下文中提供语义信息。我们使用不同比例的语义映射,这使得从粗到细(coarse-to-fine)的生成成为可能。
3. Semantic Image Synthesis
设 m ∈ L H × W m ∈ L^{H×W} m∈LH×W为语义分割mask,其中L为表示语义标签的一组整数,H和W为图像高度和宽度。m中的每个条目表示一个像素的语义标签。我们的目标是学习一个映射函数,该函数可以将输入的分割掩模m转换成逼真的真实图像。
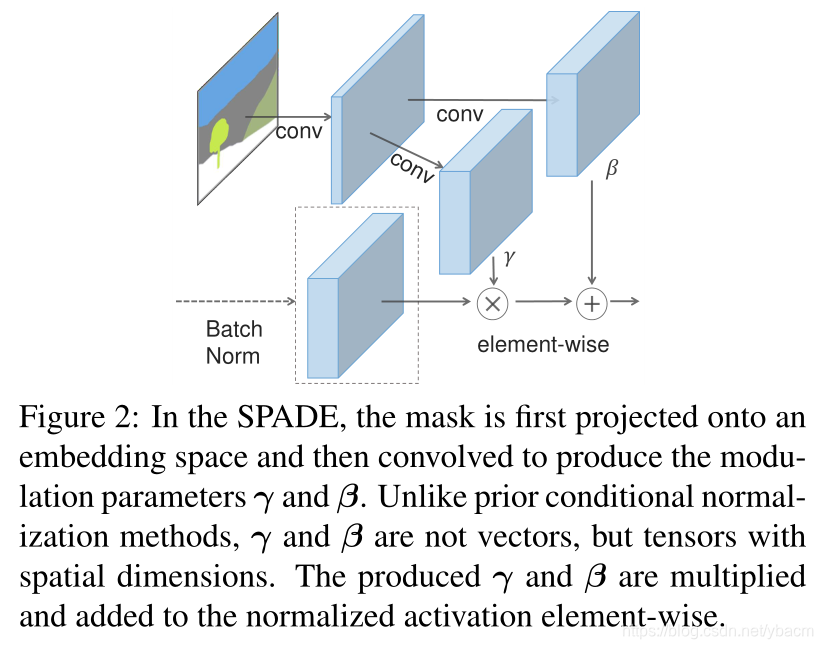
**Spatially-adaptive denormalization. ** 假设 h i h^i hi是N样本一个batch的深度卷积网络的第 i i i层的激活值。设 C i C^i Ci为该层的通道数量。 H i H^i Hi和 W i W^i Wi为该层激活值映射图的高度和宽度。我们提出一个新的条件标准化方法,叫做SPatially-Adaptive (DE)normalization(SPADE)。类似于Batch Normalization,激活值是在通道等级(channel-wise manner)上进行标准化,然后用学到的比例和偏置scale and bias来调整它。图2展示了SPADE设计。这个激活值( n ∈ N , c ∈ C i , y ∈ H i , x ∈ W i n \in N,c\in C^i, y \in H^i, x\in W^i n∈N,c∈Ci,y∈Hi,x∈Wi)为:
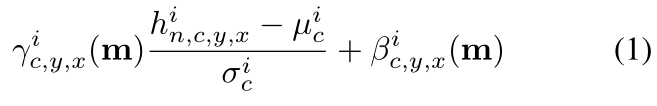
其中, h n , c , y , x i h^i_{n,c,y,x} hn,c,y,xi表示标准化前该位点的激活值, μ c i \mu^i_c μci和 σ c i σ^i_c σci表示通道c中激活的均值和标准差:
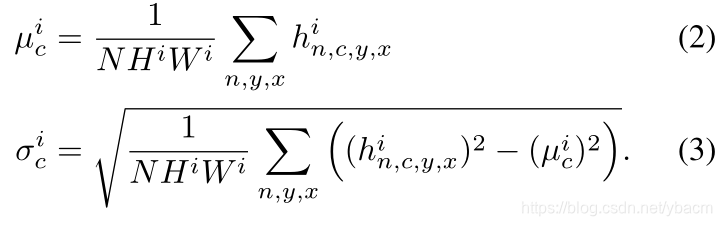
(1)中的变量 γ c , y , x i ( m ) γ^i_{c,y,x}(m) γc,y,xi(m)和 β c , y , x i ( m ) β^i_{c,y,x}(m) βc,y,xi(m)是标准化层的学习调整参数。与BN[21]相反,它们依赖于输入的分割掩码,并随位置(y,x)而变化。我们使用符号 γ c , y , x i γ^i_{c,y,x} γc,y,xi和 β c , y , x i β^i_{c,y,x} βc,y,xi来表示将m转换为第 i i i个激活图中位置(c,y,x)处的缩放和偏置的函数。我们用一个简单的两层卷积网络实现函数 γ c , y , x i γ^i_{c,y,x} γc,y,xi和 β c , y , x i β^i_{c,y,x} βc,y,xi,其设计见附录。
事实上,SPADE与现有的几个标准层相关,并且是它们的推广。首先,用图像类别标签替换分割掩模m,并使调制参数空间不变(即, γ c , y 1 , x 1 i ≡ γ c , y 2 , x 2 i γ^i_{c,y_1,x_1}≡ γ^i_{c,y_2,x_2} γc,y1,x1i≡γc,y2,x2i和 β c , y 1 , x 1 i ≡ β c , y 2 , x 2 i β^i_{c,y_1,x_1}≡ β^i_{c,y_2,x_2} βc,y1,x1i≡βc,y2,x2i,这是对于任意 y 1 , y 2 ∈ { 1 , 2 , . . . , H i } y_1,y_2\in \{ 1,2,...,H^i\} y1,y2∈{1,2,...,Hi}和 x 1 , x 2 ∈ { 1 , 2 , . . . , W i } x_1,x_2\in \{ 1,2,...,W^i\} x1,x2∈{1,2,...,Wi}),我们得到了条件BN[11]的形式。事实上,对于任何空间不变的条件数据,我们的方法都简化为条件批处理Conditinoal BatchNorm。类似地,我们可以通过用真实图像替换m,使调制参数在空间上不变,并设置N = 1,来得到AdaIN [19]。由于调制参数自适应于输入分割掩模,因此所提出的SPADE更适合于语义图像合成。

SPADE generator. 使用SPADE,不需要向生成器的第一层提供分割图,因为学习的调制参数已经编码了足够的关于标签布局的信息。因此,我们丢弃了生成器的编码器部分,其在最近的架构中普遍使用[22,48]。这种简化获得了更轻量级的网络。此外,类似于现有的类条件生成器[36,39,54],新的生成器可以采用随机向量作为输入,为多模态合成提供了一种简单自然的方法[20,60]。
图4展示了我们的生成器架构,它使用了几个带有上采样层的ResNet块[15]。所有标准化层的调制参数都是使用SPADE学习的。由于每个残差块在不同的尺度下操作,我们对语义掩码进行下采样以匹配空间分辨率。(在SPADE生成器中,每个标准化层都用segmentation mask去调整层的激活值)
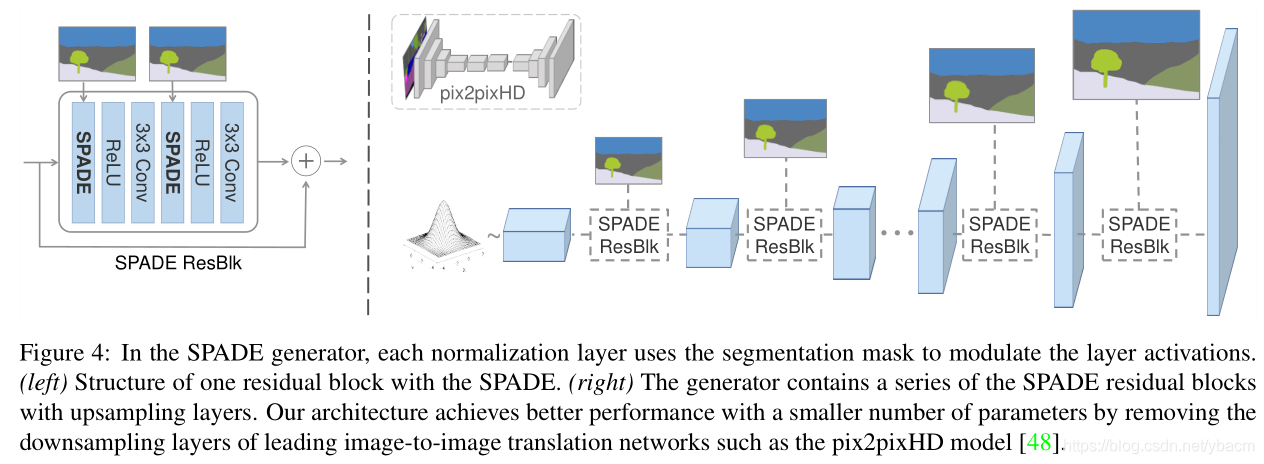
除了用hinge损失项[31,38,54]替换最小平方least squared损失项[34]之外,我们用pix2pixHD [48]中使用的相同多尺度鉴别器和损失函数来训练生成器。我们测试了最近无条件GANs [1,36,39]中使用的几种基于ResNet的鉴别器,观察到了与上述类似的结果,但是有更高的GPU内存要求。将SPADE添加到鉴别器中也只是产生类似的性能。对于损失函数,我们观察到移除pix2pixHD损失函数中的任何损失项都会导致生成结果降级。
Why does the SPADE work better? 简而言之,它相对于常见的标准化层可以更好的保存语义信息。具体地说,虽然标准化层(如实例化层InstanceNorm[46])是几乎所有最先进的条件图像合成模型[48]中的基本部分,但是当应用于uniform或flat的分割掩模时,它们往往会洗掉语义信息。
让我们考虑一个简单的模块,首先将卷积应用到分割掩码,然后进行标准化。此外,让我们假设将具有单个标签的分割掩膜作为模型的输入(例如,所有像素都具有相同的标签,例如天空或草地)。在此设置下,卷积输出也是uniform的,不同的标签具有不同的一致uniform值。现在,在我们将InstanceNorm应用于输出之后,标准化的激活值将变成全零,不管给定的输入语义标签是什么。语义信息完全丢失了。这种限存在于广泛的生成器体系结构,包括pix2pixHD及其在所有中间层连接语义掩码的变体,只要网络对语义掩码应用卷积然后标准化。在图3中,我们根据经验表明,pix2pixHD正是这种情况。因为分割掩码通常由几个均匀uniform的区域组成,所以在应用标准化时会出现信息丢失的问题。
相比之下,SPADE生成器中的分割掩码是通过空间自适应调整然后输入fed的,没有标准化。只有来自前一层的激活被标准化。因此,SPADE生成器可以更好地保存语义信息。它享有标准化的好处,而不会丢失语义输入信息。
Multi-modal synthesis. 通过使用随机向量作为生成器的输入,我们的架构为多模态合成提供了一种简单的方法[20,60]。也就是说,可以连接一个编码器,将真实图像处理成随机向量,然后将该向量馈送给生成器。编码器和生成器形成一个VAE [28],其中编码器试图捕捉图像的样式,而生成器通过编码的样式和分割掩码信息来重建原始图像。编码器还在测试时充当样式指导网络,以捕捉目标图像的样式,如图1所示。对于训练,我们增加了KL-散度损失项[28]。 将真实图片与语义图像相结合生成新图片
4. Experiments
Implementation details. 我们将Spectral Norm[38]应用于生成器和判别器中的所有层。生成器和鉴别器的学习速率分别为0.0001和0.0004[17]。我们在β1= 0和β2= 0.999的情况下使用ADAM solver[27]。所有的实验都是在NVIDIA DGX1上进行的,有8个32GB的V100 GPUs。我们使用同步批处理,也就是说,这些统计数据是从所有的图形处理器中收集的。
Datasets. 我们在几个数据集上进行了实验。
- COCO-Stuff [4]来自COCO数据集[32]。它有118,000个训练图像和5,000个从不同场景捕获的验证图像。它有182个语义类。由于其巨大的多样性,现有的图像合成模型在该数据集上表现不佳。
- ADE20K [58]由20,210个训练图像和2,000个验证图像组成。类似于COCO,数据集包含具有150个语义类的挑战性场景。
- ADE20K-室外是ade 20k数据集的一个子集,只包含室外场景,用于Qi等人[43]。
- Cityscapes 数据集[9]包含德国城市的街道场景图像。训练集和验证集的大小分别为3,000和500。最近的工作已经在城市风景数据集上实现了逼真的语义图像合成结果[43,47]。
- Flickr Landscapes。我们从Flickr收集了41000张照片,并使用1000个样本作为验证集。为了避免昂贵的手动注释,我们使用训练好的DeepLabV2 [5]来计算输入分割掩码。
我们在相同的训练集上训练不同的语义图像合成方法,并在每个数据集的相同验证集上报告它们的结果。
Performance metrics. 我们采用了以前工作的评估方案[6,48]。具体来说,我们对合成图像运行语义分割模型,并比较预测的分割掩码与真实输入的匹配程度。直观地说,如果输出图像是真实的,一个训练好的语义分割模型应该能够预测真实标签。为了测量分割精度,我们同时使用了mean Intersection-over-Union(mIoU)和pixel accuracy(accu)。我们对每个数据集使用最先进的分割网络:DeepLabV2 [5,40]。除了mIoU和accu分割性能指标,我们还使用Fréchet Inception Distance(FID) [17]来测量合成结果分布和真实图像分布之间的距离。
Baselines.
Quantitative comparisons. 如表1所示,我们的方法在所有数据集上都比当前最先进的方法有很大的优势。

Qualitative results. 在图5和6中,我们提供了定性比较。我们发现,我们的方法产生的结果具有更好的视觉质量和更少的可见伪像,特别是对于COCO-Stuff和ADE20K数据集中的不同场景。当训练数据集很小时,SIMS模型也能渲染出视觉质量很好的图像。然而,所描绘的内容经常偏离输入分割遮罩(例如,图6第二行中游泳池的形状)。




Human evaluation.
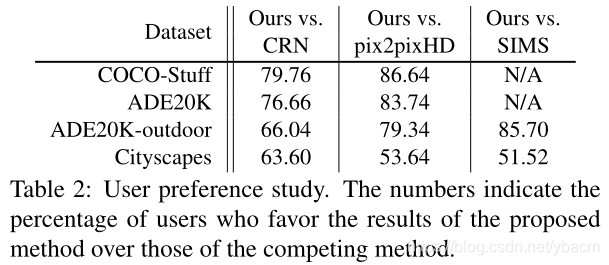
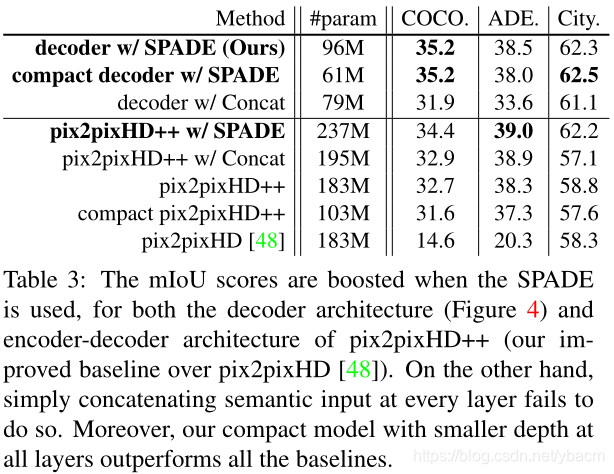
Effectiveness of the SPADE. 为了量化SPADE的重要性,我们引入了一个强大的基线,称为pix2pixHD++,它结合了我们发现对增强pix2pixHD性能有用的所有技术,除了SPADE。我们还训练一些模型,这些模型在所有中间层都接收分割掩码输入,是通过在通道方向的特征连接来实现的,称为pix2pixHD++ w/ Concat。最后,将强基线与SPADE相结合的模型称为pix2pixHD ++ w / SPADE。
如表3所示,无论是图4中描述的解码器式架构,还是pix2pixHD中使用的更传统的编码器-解码器架构,使用建议的SPADE的架构始终优于其对应架构。我们还发现,在所有中间层连接分段掩码,作为SPADE的合理替代,并不能获得与SPADE相同的性能。此外,解码器风格的SPADE生成器比强基线更好地工作,即使参数数量更少。
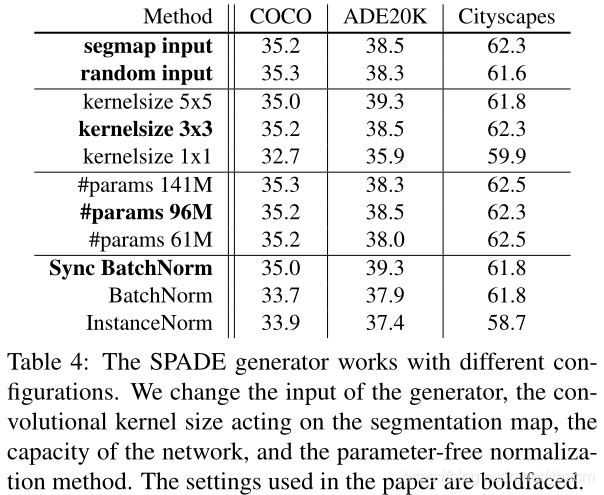
Variations of SPADE generator . 表4报告了我们的生成器的几个变化的性能。首先,我们比较发生器的两种输入,一种是随机噪声,另一种是下采样的分割图。我们发现这两种变体表现出相似的性能,并得出结论,由SPADE单独调制提供了关于输入掩码的足够信号。其次,在应用调制参数之前,我们改变无参数标准化层的类型。我们观察到SPADE在不同的标准化方法中可靠地工作。接下来,我们改变作用于标签映射的卷积核大小,发现1x1的核大小损害了性能,可能是因为它禁止利用标签的上下文。最后,我们通过改变卷积滤波器的数量来修改发生器的容量。我们在附录中提出了更多的变化和消融。
Multi-modal synthesis.

Semantic manipulation and guided image synthesis. 在图1中,我们展示了一个应用程序,其中用户绘制不同的分割遮罩,我们的模型渲染相应的风景图像。此外,我们的模型允许用户选择外部风格的图像来控制输出图像的全局外观。我们通过用图像编码器计算的风格图像的嵌入向量替换输入噪声来实现它。
5. Conclusion
个人总结:抛弃编码器对语义图的编码,使用随机噪声来作为生成器的输入,在每层的标准化之后都用SPADE ResBlk(不同层对应着不同尺度)来针对语义图作调整。

















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









