







0x00 字符的编码
计算机毕竟是西方国家的发明,最开始并没有想到会普及到全世界,只用一个字节中的7位(ASCII)来表示字符对于现在庞大的文字数量来说显然不够,所以先后经历了好几套编码方案,不同国家和地区又有自己的方案,造成了现在诸多的历史遗留问题。具体讲述编码原理请看这篇文章:PYTHON编码的前世今生
0x01 Python中的字符串
Python有两种不同的字符串,一种存储文本,一种存储字节。对于文本,Python内部采用Unicode存储,而字节字符串显示原始字节序列或者ASCII。
什么叫编码(encode)?
按照字面意思和以往经验,我要把这个文本或字符串用“UTF-8”编码,感觉上应该是对字节数据进行编码然后显示正确的文字。大多数人都是这么想的,可事实呢?
编码的意思是将Unicode字符按照编码规则(如UTF-8)编成字节序列:

有人此时会问,我用 print 语句打印出来怎么是乱码或者是中文,并不是字节序列。这是因为你调用 print 语句的时候,默认进行了隐式解码,为的是让人类看见友好的字符数据 ,也就是默认的进行了str()包装,想看见背后真正的十六进制数,你需要调用魔术方法 _repr_() 。
什么叫解码(decode)?
对应的,解码就是将字节序列按照编码规则(如UTF-8)解释成unicode形式。

这里或许又会有疑问,编码解码都是十六进制,那中文字符咋显示的?
这又要结合你的环境了。看完我上面推荐的文章,你就会明白,Unicode只是一种标准,而具体的编码才是实现方式。有了正确的Unicode编码,仅仅代表你有了正确的英文文献,想翻译成中文,还得再转换一次。而这一次转换,是你的环境帮你完成。举个例子,你打开一个文档,发现是乱码,多半是文本编辑器的解码方式有问题,换个解码规则就好了。
0x02 Python2 和 Python3 之间的区别
Python3 一切都很美好
在Python3当中,文本字符串类型(使用Unicode数据存储)被命名为 str , 字节字符串类型被命名为 bytes 。一般情况下,实例化一个字符串会得到一个 str 对象 :
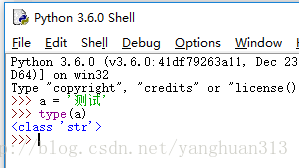
所以现在很多人都说,Python3默认是Unicode,也就是这个意思。
如果你想得到bytes,那就在文本之前加上前缀 b , 或者 encode 一下。

所以,很显然,str 对象有一个encode方法,bytes 对象有一个decode方法。
Python2 相当的操蛋,甚至会误导你
在Python3中的 str 对象在Python2中叫做 unicode ,感觉很通俗对吧?但 bytes 对象在Python2中叫做 str ,对。。就是你平时用的 str , 默认的那个。。。
如果你想得到一个文本字符串,你需要在字符串之前加上前缀 u 或者 decode 一下。
搞笑的还不止这么点,Python2中的 str (字节) 对象,竟然有一个 encode 方法!!!而且你别指望它有什么特殊用处,它就是用来报错的,永远都别使用它!!!
同样的,unicode (文本字符) 对象也有一个用来报错的 decode 方法。
我们尝试一下:

不知道大家注意到错误信息没有,我们在进行解码,规则是GBK,但它说 无法用 ascii 进行编码 ,这是为什么?
这就是Python2自作聪明为了对一个unicode对象执行解码而进行的隐式编码 ,等于以下代码:
- 1
这就是为什么很多人说,Python2的编码很操蛋。
0x03 小结
如果你在用2.X,请养成在字符串加上 u 前缀的习惯,统一编码UTF-8,如果windows控制台或者Pycharm控制台依旧出现乱码,那多半是控制台编码不同,改过来就好。















 8793
8793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









