







 本文介绍了如何使用sklearn库在Python中实现SVM,以预测用户是否购买SUV为例,通过年龄和薪水数据进行分类。经过训练和测试,模型的准确率达到了90%,并探讨了SVM的线性核函数应用。
本文介绍了如何使用sklearn库在Python中实现SVM,以预测用户是否购买SUV为例,通过年龄和薪水数据进行分类。经过训练和测试,模型的准确率达到了90%,并探讨了SVM的线性核函数应用。
SVM——support vector machine
是目前使用最广泛的分类模型,该模型又被称为大间距分类器
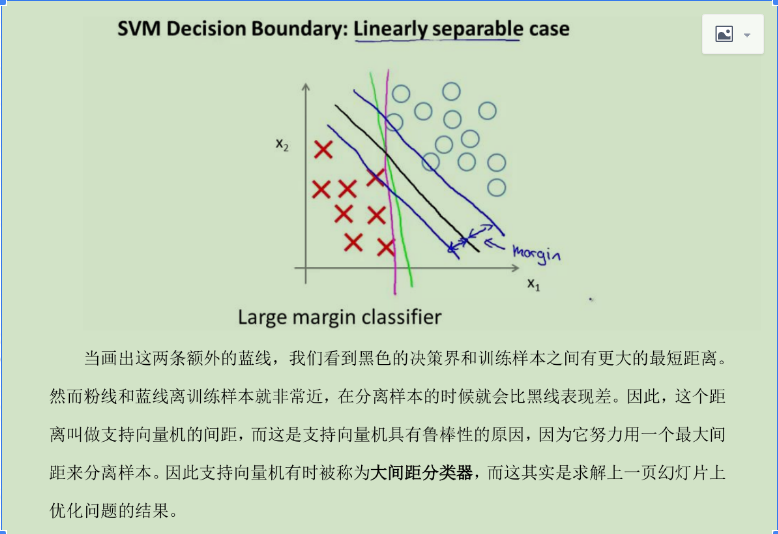
样例:
场景:根据用户的年龄、薪水来预测其是否购买SUV
数据集:
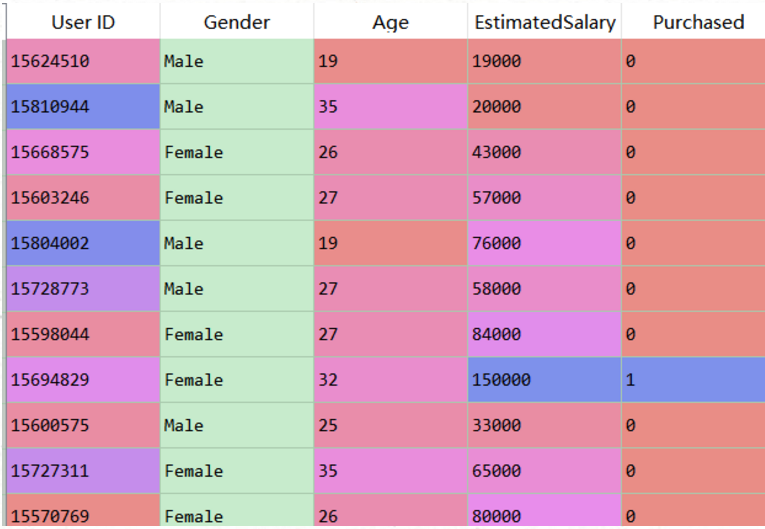
简单分析一下这个数据集,第一列是用户id,第二列是用户性别,本次实验不考虑这两个特征。我们希望通过根据用户的年龄和薪水预测用户是否会购买SUV,根据预测结果对用户进行针对性推销。那么age和salary将是我们自变量X,purchased则是我们的因变量y。
代码:
- 数据预处理(导入标准库、导入数据集、分割训练集和测试、特征缩放)
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Fitting classifier to the Training set
# Create your classifier here
from sklearn.svm import SVC
classifier = SVC(kernel = "linear",random_state = 0)
classifier.fit(X_train, y_train)
- 构造SVM分类器,用训练集拟合分类器,用拟合好的分类器进行预测
# Fitting classifier to the Training set
# Create your classifier here
from sklearn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









