







 本文介绍了K-Means聚类的步骤,包括选择聚类数K,避免随机初始化陷阱,以及如何利用手肘法则确定最佳聚类数。通过实例演示了如何使用sklearn实现聚类,并展示了kmeans++算法的重要性。文章最后通过代码展示了K-Means聚类的实际应用。
本文介绍了K-Means聚类的步骤,包括选择聚类数K,避免随机初始化陷阱,以及如何利用手肘法则确定最佳聚类数。通过实例演示了如何使用sklearn实现聚类,并展示了kmeans++算法的重要性。文章最后通过代码展示了K-Means聚类的实际应用。
用sklearn实现聚类——K-Means算法
1.k-means聚类的步骤
- 选择想要分类的个数K
- 在平面中随机选择K个点(并不需要找数据中的点)
- 分配:依据数据集中的每个点到K个点的距离,找到每个点对应的最短距离的点(比如m1离k3最近),这样数据集将分成K类
- 更新:寻找每个类的中心点,将其设置为K点
- 循环步骤3、4直到中心点就是K点
大致过程:




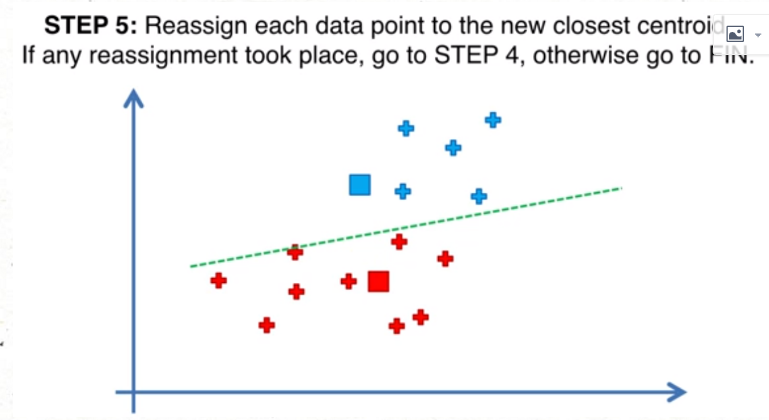
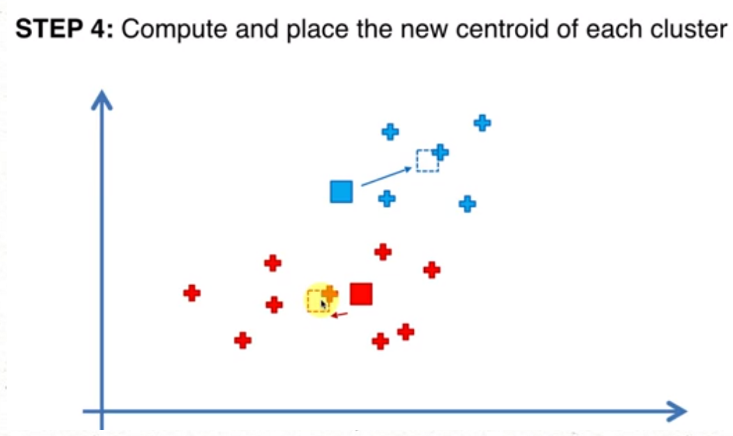


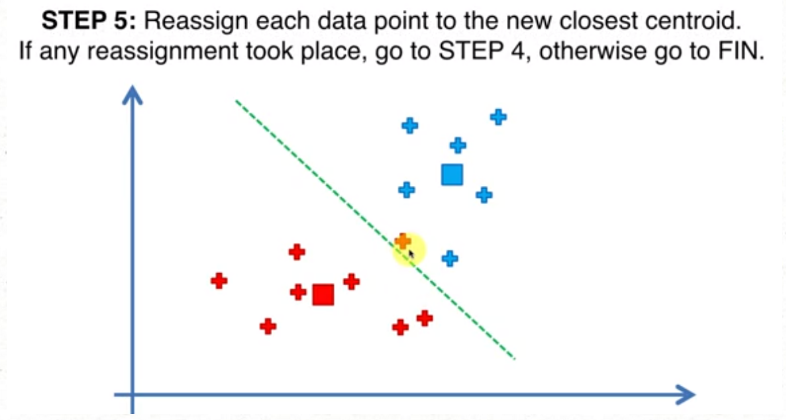



2.随机初始化陷阱
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样
做:
- 我们应该选择 K<m,即聚类中心点的个数要小于所有训练集实例的数量
- 随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。根据初始化的情况还可能出现不同的分类情况。
如图:
理想情况:

实际情况:

实际的结果和理想的结果相差很大,但很难说哪种聚类方式是对的,哪种聚类方式是错的,因为他们都有各自的道理.
说明初始化的中心点对于最终结果有决定性的作用
我们应该如何解决这类问题呢?
使用kmeans++算法,推荐博客:简单易学的机器学习算法——K-Means++算法
3.如何选择聚类数?手肘法则
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用 K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
当人们在讨论,选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”。关于“肘部法则”,我们所需要做的是改变 K 值,也就是聚类类别数目的总数。我们用一个类来运行 K 均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数 J。K 代表聚类数字。
运用手肘法则之前,我们必须引入一个概念:组内平方和:
组内平方和又称残差平方和、误差平方和等,根据n个观察值拟合适当的模型后,余下未能拟合部份(ei=yi一y平均)称为残差,其中y平均表示n个观察值的平均值,所有n个残差平方之和称误差平方和。在回归分析中通常用SSE表示,其大小用来表明函数拟合的好坏。将残差平方和除以自由度n-p-1(其中p为自变量个数)可以作为误差方差σ2的无偏估计,通常用来检验拟合的模型是否显著。

简单来说:
- 组内平方和越大,样本越’分散’
- 组内平方和越小,样本越’集中’
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









