









1.什么是DATASET
数据集是逻辑上相关的数据集合,主机上的数据、编写的程序源码存放于Data Set中。简而言之:数据集就是类似PC机中的“文件”。
根据不同的组成结构,Dataset可分为不同的类型。
2. DATA SET的类型
2.1 顺序数据集(Sequential Data Set)
顺序数据集也被认为是
物理顺序集(Physical Sequential----PS)记录按写入的先后顺序排列,新记录被附加到数据集的尾部。在顺序数据集里,数据是按顺序存取的,想要获取记录5,系统必须先读取前4个记录。
可以直接查看和修改,可以存放数据或者源码,可将其简单理解为PC上的根目录下的“
文本文件”
2.2 分区数据集(Partitioned Data Set----PDS)
将数据集分为按顺序组织的成员(Member),每个数据集可以有一个或多个成员,每个成员有唯一的名字,作为数据集的一部分存储在地址目录中。
分区数据集打开以后,不需要查询整个数据集,用户就可以获取任何一个Member的记录,根据需要可以增加或删除任何一个Member记录。但只是删除了地址目录中的Member名,因此删除记录的空间是不能被重修使用的。
分区数据集可以理解为PC机中的“文件夹”,里边可以存放多个Member,Member中可以存放数据或者源码,Member也类似PC上的“文本文件”。PDS需要压缩才能释放系统空间,Member的数量要受目录块数量的影响。
2.3 扩展分区数据集(Partitioned Data Set Extended----PDSE)
与PDS数据集类似,也是由多个Member组成,唯一区别是,PDSE的地址目录的大小是动态的,因此在增加或删除Member时,系统会自动分配或回收存储空间。在建立是不需指定目录块数量。
2.4 VSAM 数据集(Virtual Sequential Access Method)
3. DATA SET的查看
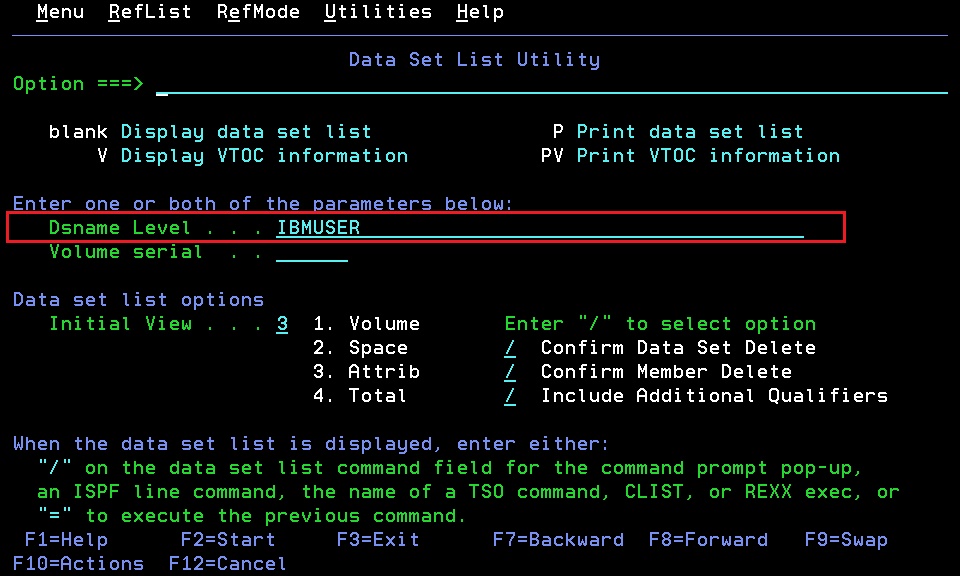
在ISPF Primary Option Menu(即ISPF主画面)的命令行输入 3.4 即可进入Data Set List Utility(数据集列表功能画面),在Dsname Level中输入USERID或具体的文件名,按确认键即可进入文件列表。
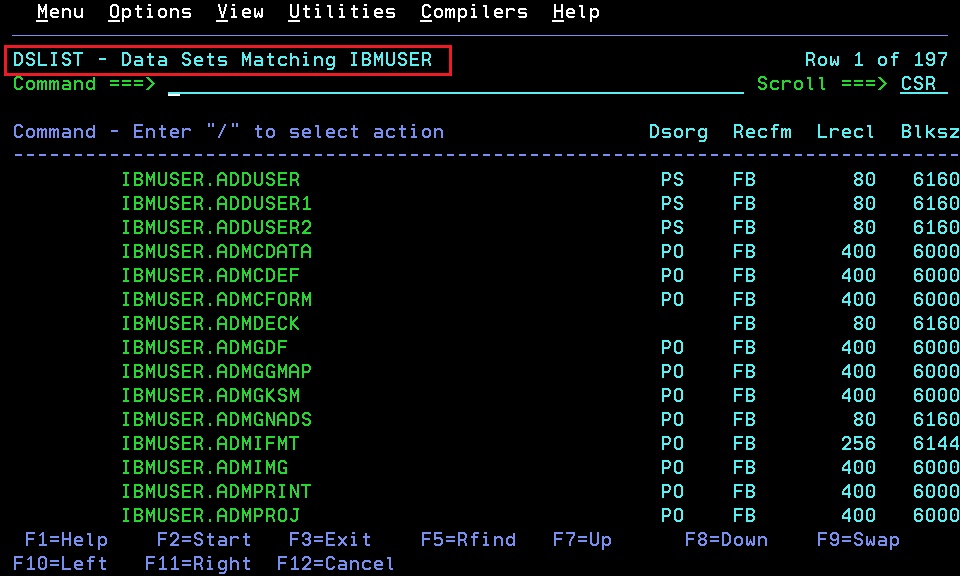
可以在DSLIST画面按F10或F11,将屏幕项翻到包含Dsorg的画面,通过Dsorg来区分
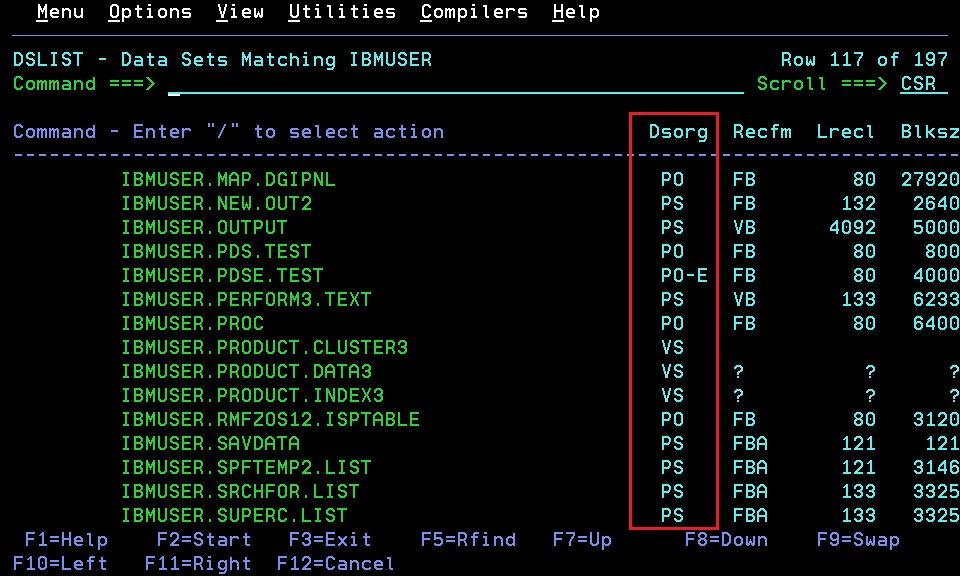
文件类型 Dsorg
PS => PS
PDS => PO
PDSE => PO-E
VSAM => VS4. DATA SET的打开
打开方式:
Edit:(对应数据集操作的列表上的‘1’)编辑形式打开,可修改,保存。
View:(对应数据集操作的列表上的‘2’)查看形式打开,可修改,但不能保存。
Browse:(对应数据集操作的列表上的‘3’)浏览形式打开,不可修改。
打开数据集的操作步骤:
1.选择希望打开的数据集,光标放到数据集名上按确认键
2.在显示的数据集操作的列表上,选择希望操作数据集的方式(1/2/3)后按确认键
3.如果是PDS进入目录后,看到目录下数据集列表,光标放到希望操作的文件名前的下划线上后按确认键打开数据集。
5. DATA SET的建立
DATA SET的命名基本原则:
一个数据集名由多个段组成(一般至少2段,多采用3段式)
段与段之间用一个分段符‘.’间隔
每个段的命名:
•长度不能超过8个字符
•首位只能是字母(A—Z)或通配字符:@、#、$
•除首位外,可以是字母(A-Z)、数字(0-9)、或通配字符@、#、$
一个数据集的名字最大长度是44个字符,包括分段符‘.’
DATA SET的命名一般原则:
一般系统会对一个USERID命名DATASET的首段权限作限制,所以,此段不能任意命名,一般为USERID名。
第2段称为GROUP,原则可任意命名(但需遵从系统规范,体现在两点:
1,上述每段命名规则;
2,每个公司、每个项目会对二段进行约束,比如我们:USERID.COBOL专门存放COBOL程序、USERID.JCL专门存放编译器、执行器等等)
第3段称为TYPE,如:data,text或编程语言名(如:COB),原则可任意命名(但需遵从系统规范)
新建DATA SET 数据集:
在ISPF Primary Option Menu(即ISPF首画面)的命令行输入3.2即可进入DATA SET UTILITY
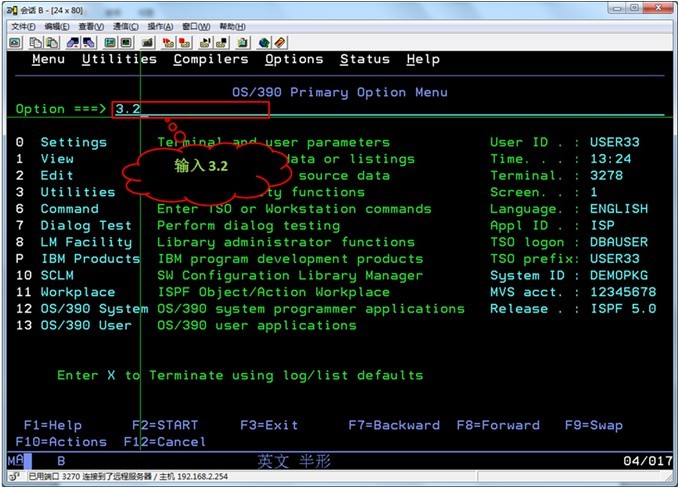
在DataSet Name里,输入三段名称,在Option里输入A,并按CTRL执行。
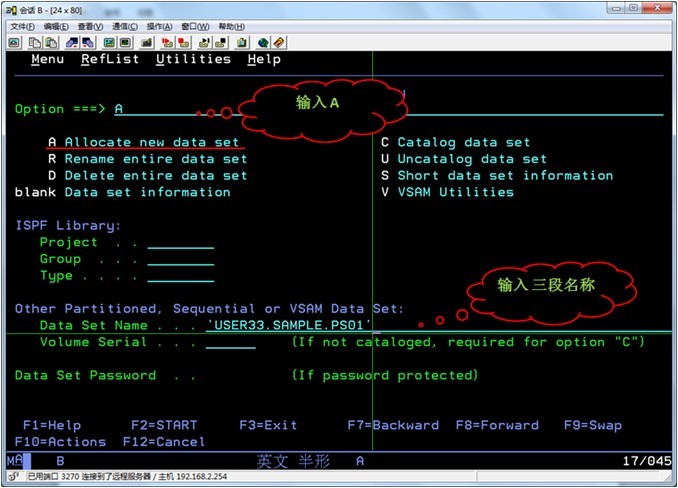
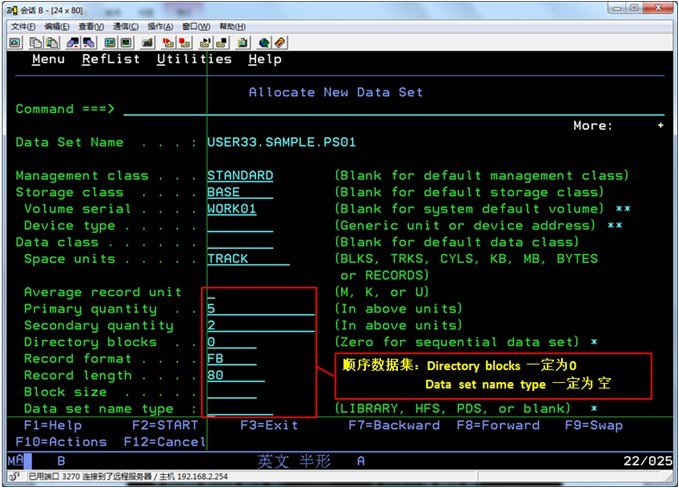
设置DATASET的参数(PS数据集)
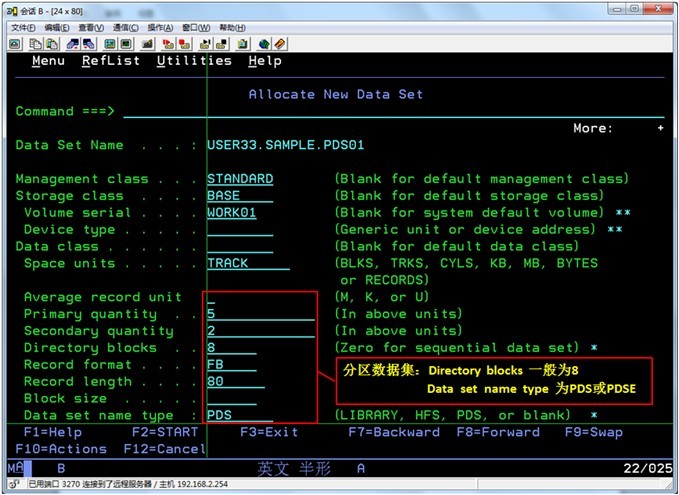
设置DATASET的参数(PDS/PDSE数据集)
按CTRL执行回到3.2界面,数据集创建成功。
参数含义:
Management class:管理类别 指定数据集管理方面的信息(如备份,有效期)
Storage class:存储类别 指定新分配数据集存储相关信息(如卷名,卷类型)
Data class:数据类别 指定新分配数据集分配数据相关信息(如空间单位)
Space unit:申请空间的单位:BLKS(块)、TRKS(扇区)、CYLS(柱面)
Primary quantity:第一次分配空间的数量,按照指定空间单位分配
Secondary quantity:每次增加分配空间数量,按照指定空间单位分配,最多15次
Directory block:地址目录分配空间数量,PS必须为0,PDS必须大于0; 1个Directory block一般大约可存放5个Member 。Member 数量 = N*6-1(N: Directory block 数量)
Record Format:记录格式: FB(定长、分块) 、U(格式未定)
Record length:记录逻辑长度,必须大于0,一般为80
Block size:分块大小,如果记录格式为F,分块大小必须为记录长度的整数倍。如果留空,系统会为数据集计算并分配效率最高的分块大小,所以,一般留空
Data set name type:数据集类型,PS为空、分区数据集为PDS或LIBRARY(PDSE)
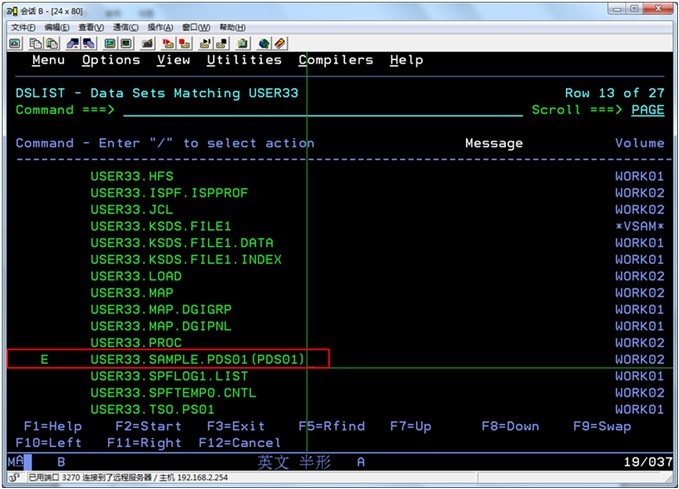
PDS/PDSE中添加MEMBER:
命令区输入‘E’,数据集后输入‘(member名)’















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









