







 本文深入探讨了Mahout如何利用Hadoop实现KMeans聚类算法的并行化。通过KMeansCluster类图,展示了Mahout的算法架构,并强调了KmeansCluster中的关键方法,如clusterPoints()和runKMeansIteration()。KMeansDriver作为算法的Driver,负责配置和运行Job以执行数据挖掘任务。
本文深入探讨了Mahout如何利用Hadoop实现KMeans聚类算法的并行化。通过KMeansCluster类图,展示了Mahout的算法架构,并强调了KmeansCluster中的关键方法,如clusterPoints()和runKMeansIteration()。KMeansDriver作为算法的Driver,负责配置和运行Job以执行数据挖掘任务。
众所周知,Mahout是基于Hadoop分布式系统的,要想看懂Mahout的源码,首先得明白mahout是如何使用hadoop的!
首先,在我的<<Hadoop运行原理详解>>一篇中,详细介绍了hadoop的运行机制,这里就不多说了!下面我就以Kmeans聚类算法为例,讲讲mahout如何利用hadoop实现数据挖掘算法并行化.如以下类图所示,
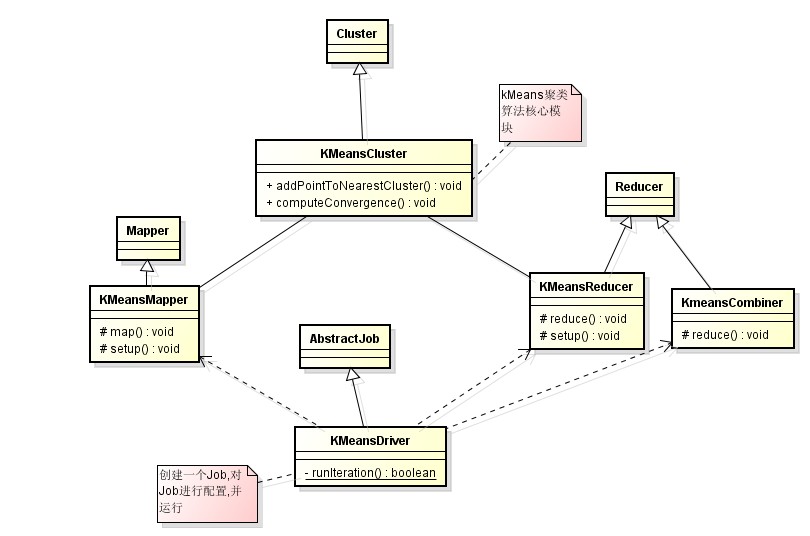
该图描述了整个mahout实现Kmeans算法的架构图,首先KmeansCluster继承Cluster,在KmeansCluster中有几个比较重要的方法,首先clusterPoints()是实现Kmeans聚类算法的方法,而其中调用了runKMeansIteration()方法,该方法是单次聚类迭代方法.
尤其可见,这块算法实现和普通kmeans算法没有太大差别!在Mahout针对每个算法都有一个Driver,这个东西是干什么的啊?
我们先看看KMeansDriver源码,KmeansDriver继承了AbstractJob.我们知道Hadoop上的任务都是以Job的形式启动的!我们要使用某个算法进行一项数据挖掘工作
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









