






回顾一下模型的生命周期

需要注意的是,在这个流程中,测试至少要参与的以下的活动:
- 离线的模型测试
- 线上线下一致性测试
- 数据质量测试
- 模型的线上质量监控
- 建模过程的功能/性能等测试
可以看出来测试人员需要做的事情其实不少,整个建模过程中也可以看到大部分过程都是数据处理过程。 所以我也经常说AI领域中的测试人员大部分时间都是在和数据打交道, 所以也是要求熟练使用数据处理的技术。 而今天我们就看看结构化数据领域内最常用的技术Spark, 这是对于测试人员来说,性价比最高的技术了, 因为它可以做的事情非常多。 并且Spark本身也有ML库(机器学习库)来完成人工智能相关的算法。所以测试人员学习Spark是一个非常有性价比的选择。
环境搭建
下载spark
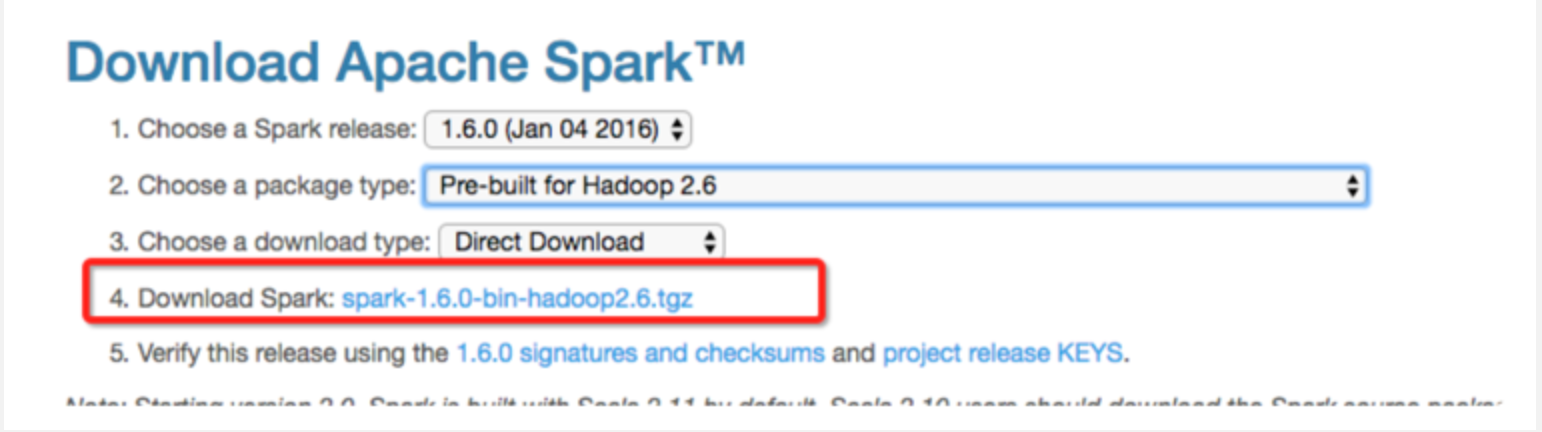
我们运行 bin/pyspark 之后就进入了 spark 的 python shell。我们为了验证是否成功了,可以运行下面的代码
lines = sc.textFile("README.md")
print lines.first()接下来就会看到打印出一条信息:# Apache Spark。 spark 提供的 python shell 是我们良好的学习平台。我们可以在里面随意的调用 spark 提供的 API。
IDE环境
可能有些同学已经习惯了 IDE 带来的好处 (例如我),所以也希望能通过 IDE 来进行学习和开发。 但是 spark 并没有提供任何 python 模块给我们下载使用, 也就是说,你无法通过 pip install 的方式下载 spark 模块。 这一点就不如 java 和 scala 了,maven 是可以直接集成 spark 的。 所以我们要做一点额外的事情以让 pycharm 能够拥有开发 spark 程序的能力。
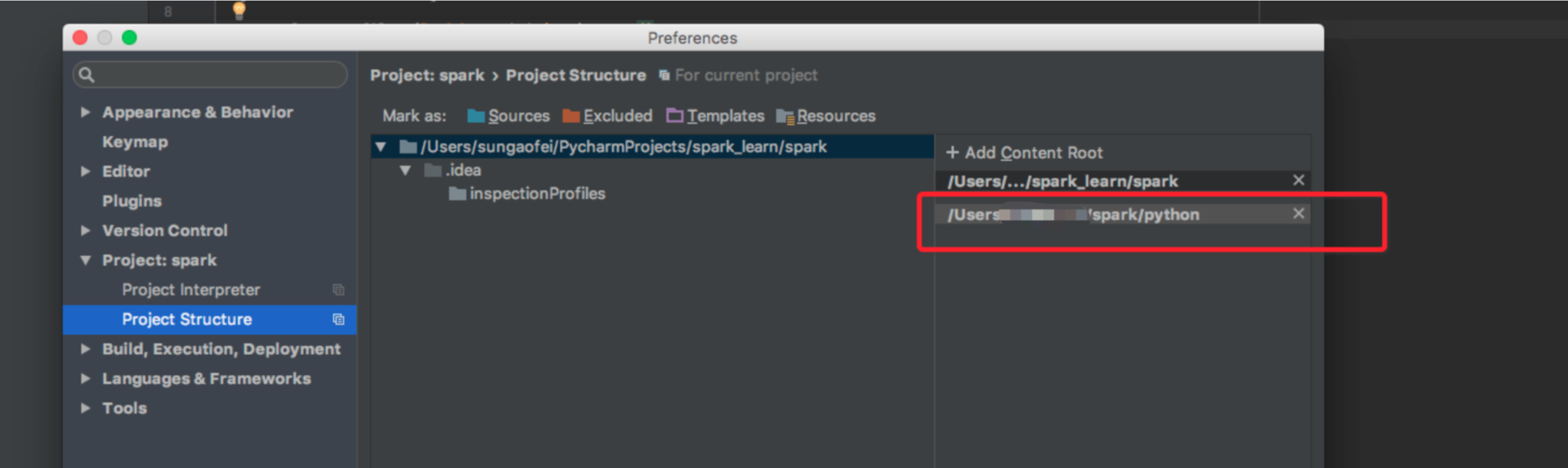
在 pycharm 找到 Project Structure 把解压的目录中的 python 目录加进去
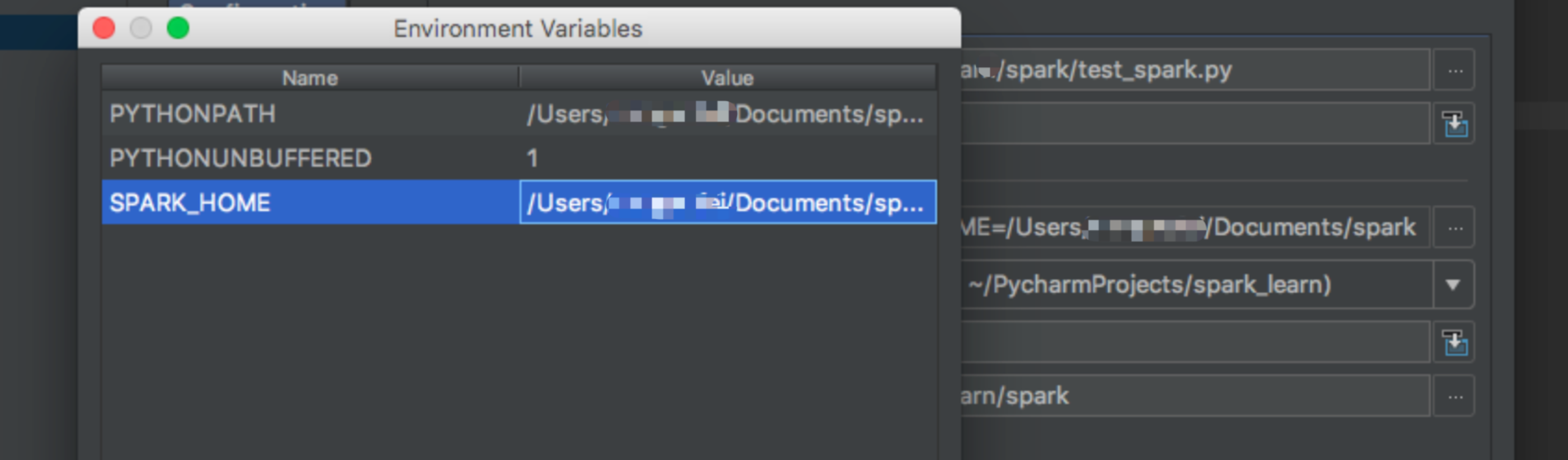
添加 run-->Edit configurations。 添加一个运行配置。并配置 SPARK_HOME 环境变量为解压目录。然后配置 PYTHONPATH 环境变量为解压目录中的 python 目录
然后各位就可以在 pycharm 上编写 spark 代码并运行了。
"""SimpleApp"""
from pyspark import SparkContext
logFile = "/Users/xxxxxx/Documents/spark/README.md"
sc = SparkContext("local","Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
temp = logData.first()
print temp
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))从demo中学习
"""SimpleApp"""
from pyspark import SparkContext
logFile = "/Users/xxxxxx/Documents/spark/README.md"
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
temp = logData.first()
print temp
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))
在全局的 level,spark 的应用是由一个驱动程序在集群中发起并行的多个操作。这个驱动程序包含了你的应用的 main 函数并定义了你的分布式数据集合。在上面的例子中,我们可以理解 SparkContext 对象就是 spark 的驱动。它负责连接集群,我们用local模式告诉 spark 我们使用本地集群模式以方便我们学习和调试。在你有了这个驱动之后,我们就可以随意的创建 RDD 了,RDD 是 Spark 的分布式数据集合的定义,我们暂时只需要知道它是存储数据的地方,之后会详细说明一下。 sc.textFile() 是从一个文本中读取数据并转换为 RDD 的方法。当我们有了 RDD 之后,就可以随意调用 spark 提供给我们的方法。例如上面例子中的 filter(熟悉 python 的朋友一定觉得这个方法很熟悉) 以及 count 方法。 在我们上面的操作中。 驱动程序会在集群中管理一定数量的 executor。 例如当我们调用 count() 方法的时候。集群中不同的机器会各自读取这个文件中的一部分并分别计算各自的行数,当然了现在我们使用的是 local 模式。所以我们的应用是运行在单机上的。整个过程差不多是下面这个样子的。

在这个 demo 中,我们是可以看到 spark 是支持函数式编程的,大部分的方法都要求传递一个函数进去。例如上面的 filter 方法。这是一个过滤函数,上面的 demo 中我们分别取包含字母 a 和 b 的行。熟悉 python 的小伙伴一定对 lambda 表达式不陌生了。
RDD基础
上面提到过 RDD,它是 spark 定义的固定不变的分布式数据集合. 我们可以使用两种方式创建 RDD
- 通过 sc.textFile() 从外部文件中读取。就如我们的 demo 一样
- 通过从一个集合中初始化一个 RDD。如下:
lines = sc.parallelize(["pandas", "i like pandas"])
transformations and actions
- - transformations: 是一种返回一个新的 RDD 的方法。它遵循延迟计算的规则。也就是说 spark 在运行的时候遇到 transformation 的时候并不会真正的执行它,直到碰到一个 action 的时候才会真正的执行。大部分 transformation 都是按行元素处理,就是说他们同一时间只处理一行数据 (有少数 transformation 不是的)
- - action: 如我们 demo 中的 count() 用来计算数据的行数. 我们还可以使用 frist() 取出第一条数据,用 take(n) 来取出前 n 条数据,saveAsTextFile() 用来把数据存储到外部文件。也就是说 action 是我们真正使用数据来进行计算的方式,真正实现数据的价值的方式。
常见的 transformation
map
除了我们在 demo 中看到的 filter() 方法来过滤数据,我们还可以使用 map() 这种 MapReduce 时代保留下来的函数。看下面的 demo
from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).foreach(lambda x: print(x))刚才我们说大部分 spark 的 transformation 是单行处理的。所以当我们把 lambda 定义的匿名函数传递给 map 的时候。 map() 会把数据中的每一行取出来作为参数进行调用。它和 filter 的区别可以用下图来表示。

flatMap
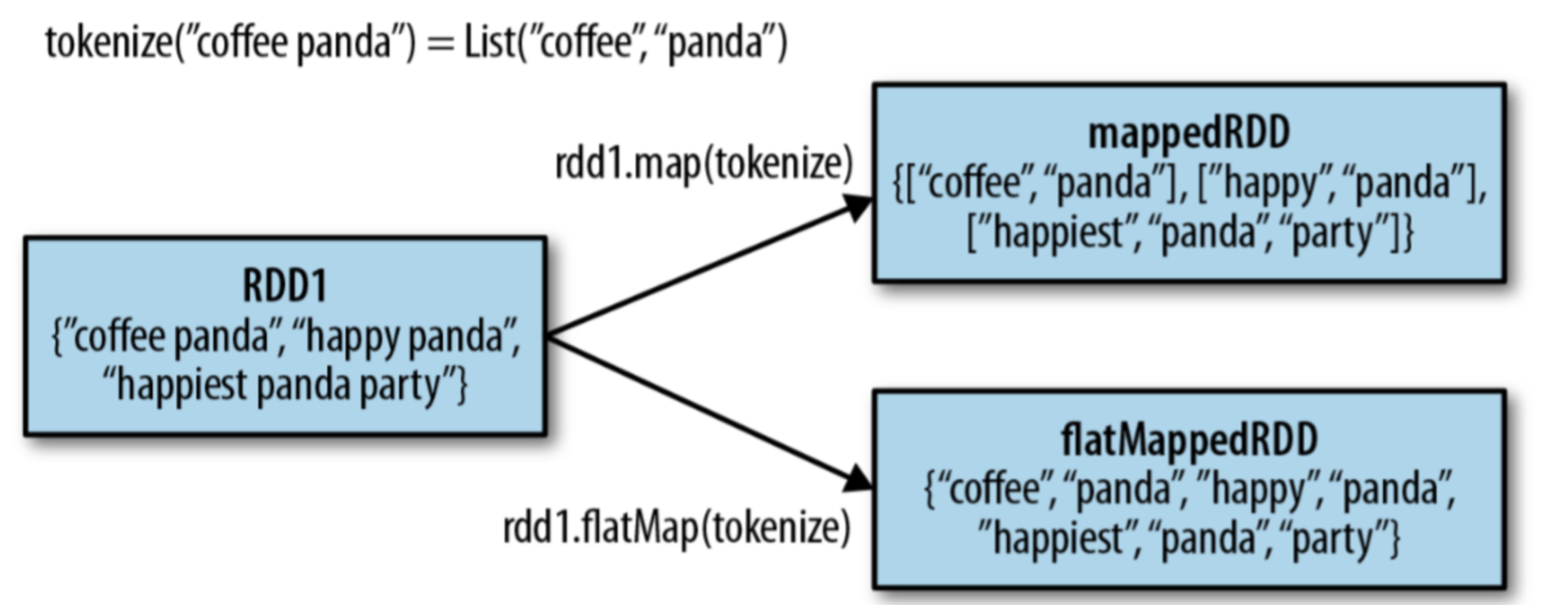
与 map() 很相似的一个方法是 flatMap()。map 的操作是处理每一行的同时,返回的也是一行数据。 flatMap 不一样,它返回的是一个可迭代的对象。也就是说 map 是一行数据转换成一行数据,flatMap 是一行数据转换成多行数据。例如下面的 demo
from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.foreach(lambda x: print(x))下图可以表示 map 和 flatMap 的区别
其他集合操作
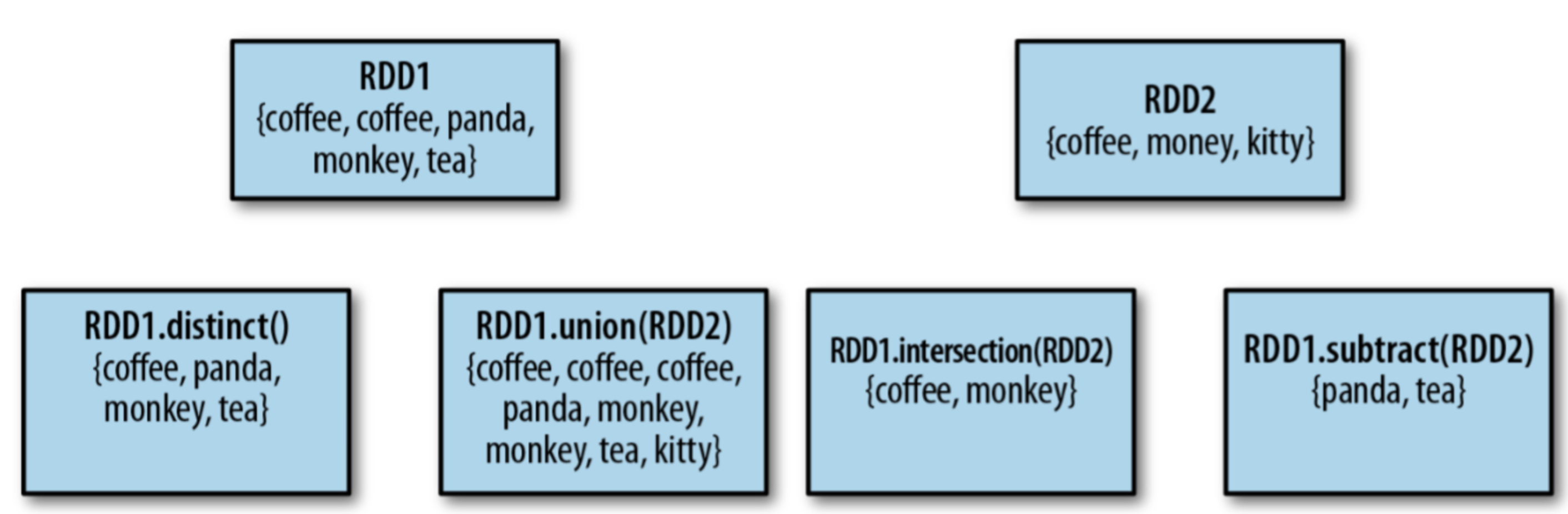
上图表示了 4 种集合操作。
Action
reduce
最常用的 action 操作是我们在 MapReduce 时期就熟悉 reduce 操作,此操作是一个聚合方法。
from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
sum = rdd.reduce(lambda x, y: x + y)
print(sum)reduce 接受一个函数当做参数,而这个函数也接受两个参数 x 和 y。 这俩个参数代表着 RDD 中的两行,reduce 是聚合函数。 它会不断的将之前计算出的两行传递给函数进行聚合计算。上面 demo 中的 sum 为 15.因为 reduce 做了一个累加的操作。
其他
此外还有我们早就见过的 count(),以及一些其他的例如:
- collect():返回 RDD 中所有的数据
- countByValue():统计每一个 value 出现的次数
- take(n):取出前 N 行数据
- foreach:循环 RDD 中的每一行数据并执行一个操作
persist
我们上面说过从性能上考虑 RDD 是延迟计算的,每遇到一个 action 都会从头开始执行。这样是不够的,因为有的时候我们需要重复使用一个 RDD 很多次。如果这个 RDD 的每一个 action 都要重新载入那么多的数据,那也是很蛋疼的。 所以 spark 提供了 persist 函数来让我们缓存 RDD。
lines = sc.parallelize(["hello world", "hi"])
a = lines.flatMap(lambda line: line.split(" ")).persist()
a.count()
a.take(10)上面我们使用 persist 函数缓存了 RDD。所以再调用 count() 和 take() 的时候,spark 并没有重新执行一次 RDD 的 transformation。spark 有很多缓存的级别。可以参考下面的图表
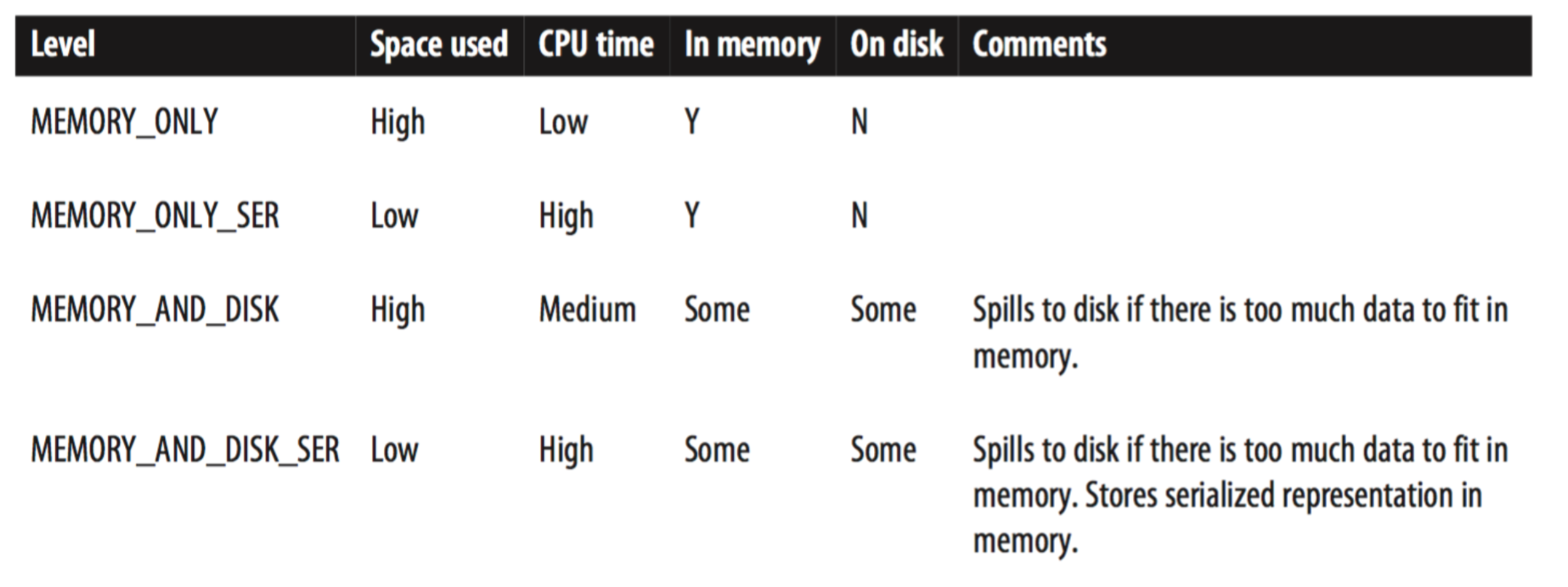
可以使用 persist(storageLevel='MEMORY_AND_DISK'),像这样的方式指定缓存级别。 默认是 MEMORY_ONLY。
结尾
今天就先写到这里, 主要是介绍了spark的入门基础, 下一次我们会更深入的了解spark的其他特性. 想看更多手把手教程请关注我的星球:
















 6984
6984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











