







 本文探讨了SQL编写规范,强调了规范化的益处,包括逻辑清晰、调试简便和模块化处理。同时,介绍了Spark数据倾斜的现象,如任务执行速度不均和内存溢出异常,并解释了其产生的原理,主要涉及shuffle操作和数据分布不均。
本文探讨了SQL编写规范,强调了规范化的益处,包括逻辑清晰、调试简便和模块化处理。同时,介绍了Spark数据倾斜的现象,如任务执行速度不均和内存溢出异常,并解释了其产生的原理,主要涉及shuffle操作和数据分布不均。
一.SQL规范
1、SQL编写规范
逗号放字段前面
对用到的表都用子查询的形式,并且只取需要用到的字段
缩进(select/from/where …and …/group by/order by/join/on…)
符号前后留空格
对一些复杂的逻辑和需要注意的点加上注释说明
别名 同级用1、2、3...区分(如 t1、t2、t3)
2.规范的好处
规范的好处逻辑结构清晰
便于调试
便于模块化处理
美观,条理清楚
3.误区
觉得耗费时间,增加工作量
觉得都一样,自己明白就行
二.数据倾斜(spark)
1、现象
1.1 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在10分钟之内执行完了,但是剩余两三个task却要一两个小时。
1.2 之前能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常
2、原理
2.1 聚合或join等(distinct、groupby、repartition)操作产生shuffle
2.2 拉取各个节点的key到某个节点上的一个task来处理
2.3 整个spark作业的运行进度是由运行时间最长的那个task决定的
2.4 某个task的key特别多,就产生了数据倾斜
一.SQL规范
1、SQL编写规范
逗号放字段前面
对用到的表都用子查询的形式,并且只取需要用到的字段
缩进(select/from/where …and …/group by/order by/join/on…)
符号前后留空格
对一些复杂的逻辑和需要注意的点加上注释说明
别名 同级用1、2、3...区分(如 t1、t2、t3)
2.规范的好处
规范的好处逻辑结构清晰
便于调试
便于模块化处理
美观,条理清楚
3.误区
觉得耗费时间,增加工作量
觉得都一样,自己明白就行
二.数据倾斜(spark)
1、现象
1.1 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在10分钟之内执行完了,但是剩余两三个task却要一两个小时。
1.2 之前能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常
2、原理
2.1 聚合或join等(distinct、groupby、repartition)操作产生shuffle
2.2 拉取各个节点的key到某个节点上的一个task来处理
2.3 整个spark作业的运行进度是由运行时间最长的那个task决定的
2.4 某个task的key特别多,就产生了数据倾斜
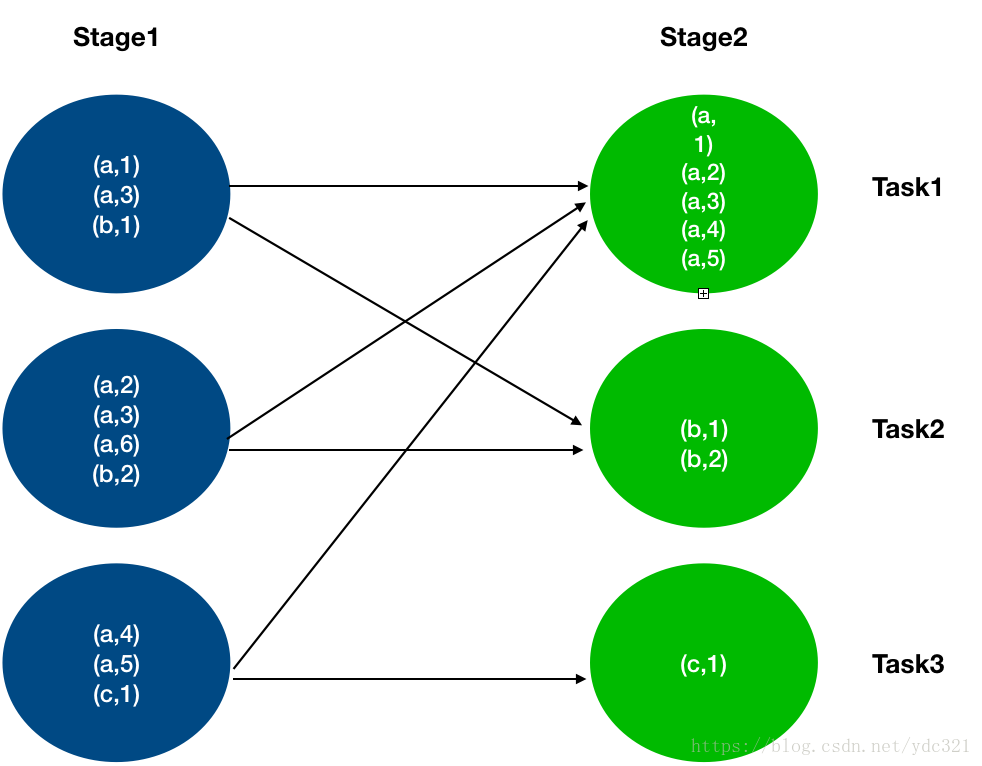
3.1 通过log定位到哪一个task发生了数据倾斜(时间特别长,数据量特别大)
3.2 由task得知对应的是哪一个stage
3.3 根据stage划分原理推算出是哪一块代码(这部分代码肯定有shuffle类算子)
4、排查
4.1 分析定位到的代码块涉及到的表或数据集
4.2 查看其中的key分布情况
5、解决
方案一:过滤少数导致倾斜的key
适用场景:导致数据倾斜的key为个别几个,而且对计算本身的影响不大
实现原理:将导致数据倾斜的key过滤掉之后,这些key不在参与shuffle计算,就不会产生倾斜
方案优点:实现简单,可以完全规避掉数据倾斜
方案缺点:适用场景少
方案二:提高shuffle操作的并行度
适用场景:由不少的key导致倾斜,并且这些key的数据量差异不是特别大
方案原理:spark sql 中把参数 spark.sql.shuffle.partitions的值调大(默认是200),增加task数量,让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据
方案优点:实现简单,只需设置参数
方案缺点:无法解决某些特殊情况,比如就某一个key对应的数据量特别大,此时无论怎么调参,这个key还是在某一个task中做处理
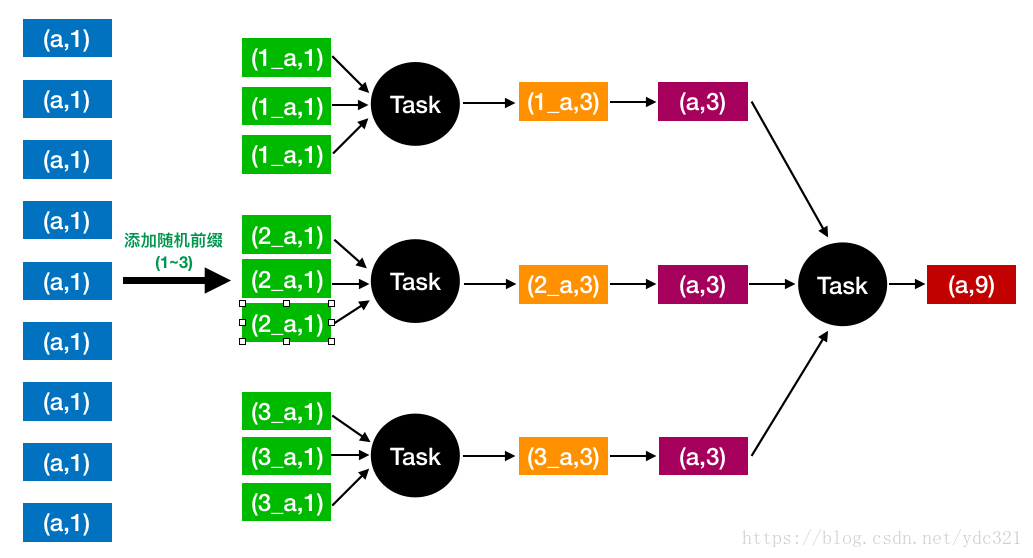
方案三:两阶段聚合(局部聚合+全局聚合)
使用场景:使用聚合类操作而发生倾斜时
实现原理:
【局部聚合】先给每个key打上个1~n的随机数,然后进行聚合
【全局聚合】对局部聚合的结果去掉打上随机数的前缀,再进行全局聚合
方案优点:对于聚合类导致的数据倾斜,效果非常不错
方案缺点:仅适用于聚合类操作,对join类的操作不适用
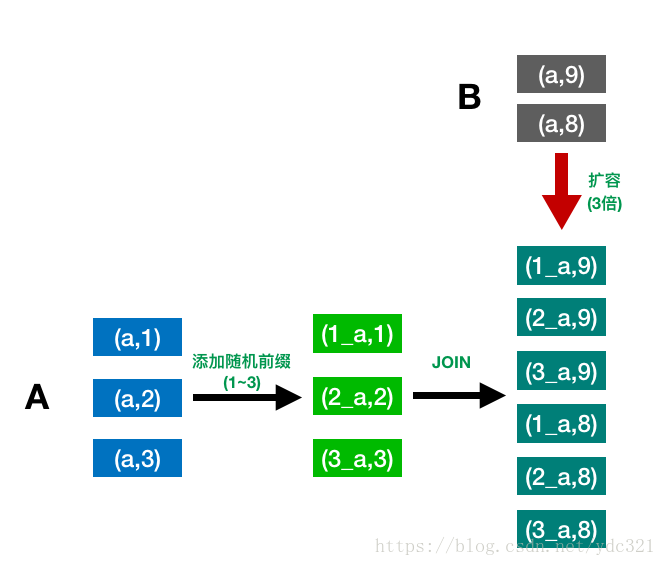
方案四:(采样)随机前缀和扩容表进行join
适用场景:有(少数)大量的key导致数据倾斜
实现原理:对造成倾斜key所在的A表的每条数据都打上1~n的随机前缀,对另一个正常的B表进行n倍扩容,每条数据都打上一个1-n的前缀,然后进行join
方案优点:对join类型的数据倾斜基本可以处理,效果显著
方案缺点:需要对数据进行扩容,对内存资源要求较高
尝试不同方案
寻找更多方案
多种方案组合使用

















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









