






AI是未来?——token&词表&BPE
文章目录
引⾔
chatGPT流⾏之后,有个token这个“新概念”突然变得流⾏了起来:chatGPT⼀次输⼊有token数限制,费⽤按token数计算等。那么token究竟是什么?对应⼀个字符?切词后的结果?切词标准化之后的结果?本⽂将对token做⼀个介绍,并基于⽐较流⾏的BPE编码⽅案做⼀个详细的剖析。
Token简介
token跟⾃然语⾔处理(NLP)中的⼀个关键步骤相关 - 词元化(tokenization),所以token有时 候也会被翻译成“词元”。在整个的NLP处理中,词元化有3类⽅法,分别是:字符级词元化、单词级词元 化、N元语法词元化。字符级词元化就是每个字符对应⼀个token。单词级词元化⽯每个单词作为⼀个 token。N元语法词元化是多个连续单词对应⼀个token。
⼤模型的词元⽅案 - ⼦词
⼦词(subword)词元化是单词级词元化的⼀种,这种⽅案把会单词再切得更细⼀些,⽤更基础的单位来表达语⾔。⽐如:"subword"这个词,可以拆分成"sub"和"word"两个⼦词,"sub"是⼀个通⽤的前缀可以和其他组合词的"sub"前缀合并,这样⼤模型将会学会使⽤"sub"前缀。类似的,“encoded"可以拆解为"encod”+“ed”,“encoding”可以拆解为“encod”+“ing”,这样两个词的核⼼部分"encod"被提取出来了,⽽且还得到时态信息。⼦词⽅案⽐较常⻅的有BPE、WordPiece、ULM等,BPE⽐较常⻅。
BPE
BPE是什么?
BPE的全称是:Byte Pair Encode,最早在1995年提出,当初也不是⽤在NLP领域,⽽是为了实现数据压缩。这个⽅法的关键部分是“Byte Pair”,它采⽤贪婪策略每次把当前⽂本中最⾼频的两个字节压缩成⼀个新的单字节(为了防⽌混淆,要使⽤当前⽂本集合中不存在的字节)。通过⼀次次地反复替换,可以快速把原始输⼊变成⼀个⾮常短的最终⽂本 + 映射表的结构。由于总是去找最⾼频的两个字节⽤⼀个字节替换它们,因此,这个“最终⽂本”会⾜够短,且映射表的映射条数也不会很⻓。
举例:
原始输⼊:supplysupplies
第⼀轮,统计词频,最⾼频组合如下:
[(‘su’, 2), (‘up’, 2), (‘pp’, 2)]
选择将’su’替换为’X’,得到:XpplyXpplies
第⼆轮,统计词频,最⾼频的组合如下:
[(‘Xp’, 2), (‘pp’, 2), (‘pl’, 2)]
选择将’Xp’替换为’Y’,得到:YplyYplies
第三轮,统计词频,最⾼频的组合如下:
[(‘Yp’, 2), (‘pl’, 2), (‘ly’, 1)]
选择将’Yp’替换为’Z’,得到:ZlyZlies
第四轮:统计词频,最⾼频的组合如下:
[(‘Zl’, 2), (‘ly’, 1), (‘yZ’, 1)]
选择将’Zl’替换为’W’,得到:WyWies
第五轮:统计词频,最⾼频组合如下:
[(‘Wy’, 1), (‘yW’, 1), (‘Wi’, 1)]
已经全部为1,编码停⽌。
最终的结果得到:
1)字符串WyWies(⻓度为6,原始字符串⻓度为14个字符,压缩率为42.8%)
2)4条替换规则:su->X, Xp->Y, Yp->Z, Zl->W
BPE在NLP中的应⽤
在上⼀节例⼦的基础上,对替换规则依次增加两个条件:
1)要求替换规则的左侧必须⽤原⽂本集合中的字节表达(即:X必须表达为su,Y必须表达为sup),那么我们可以得到由 [su,sup,supp, suppl ] 4个⼦串构成的集合。
2)要求剔除唯⼀的更短组合,即当“Xp->Y”替换为 X+p = sup时,如果X没有和p之外的其他字节组合,那么字典中不能出现X所代表的su,清理之后,得到[suppl]这个集合。
经过上⾯两个条件的处理,我们发现最终得到的结果是supply、supplies的公共部分,通过BPE能够实现词⼲的提取!类似suppl这样的单词⽚段对应了NLP中⼦词(subword)的概念,BPE就从数据压缩算法扩展成了NLP的⼦词编码算法。
BPE是如何实现编码和解码的?
编码是指把⼀段⾃然语⾔转换为另外⼀种表示,⽐如转换成由⼀个个⼦词构成的列表。解码则是把⼦词列表表示的⼀段数据转换为对应的⾃然语⾔。
在编码和解码之前,我们⾸先需要得到⼀个词典:
1.准备好⾜够⼤的语料,并统计语料中每个单词的词频。
2.确定subword词典的⼤⼩(单词个数)
3.将单词拆解成字符序列,并在单词末尾加特殊标记(⽐如“”)
4.因此,⼀开始,字词的字典是由单个字⺟构成的
5.每⼀轮统计连续2个单位出现的频率,选择最⾼频的合并成⼀个subword
6.重复执⾏上⼀步,直到subword词表⼤⼩符合⽬标,或者最⾼频变为1
说明:
1)词尾加’‘等特殊标记的⽬的是让后缀和单词中间的词区分开来。⽐如:⽐较级的后缀’er’(high-er,fast-er) 和 error erase中的er具有不同的意义,需要做⼀定的区分。实际上词头也可以加区分符,因为 in, un等前缀和词中间的含义也有很⼤不同。
2)词表⼤⼩的变化,通常是先增加后减少的。下图是基于PTB数据集做的实验,做了1.6万轮左右之后,subword词表⼤⼩开始逐渐缩⼩。
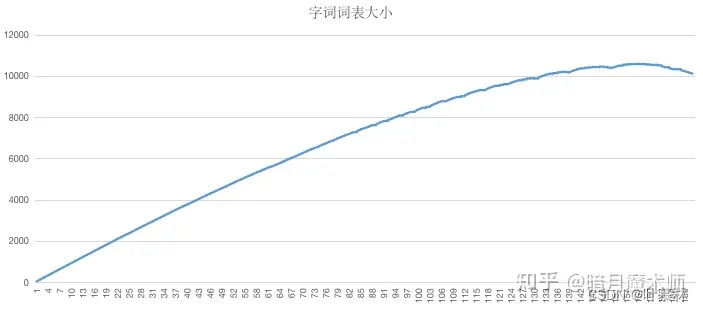
3)⽬标词表的⼤⼩设定⾮常重要 。如果设置过⼩,词表中更多的是⾼频的短字⺟组合,subword不够有区分度(极限情况就是26个字⺟)。如果设置过⼤,⼀⽅⾯计算时间很⻓,另⼀⽅⾯如果语料集不够⼤,得到的往往是原来的全部词汇,失去了做⼦词的意义。⼀般会采⽤16k-32k的词表。
4)最重要的是,要有“⾜够多的语料”。前⾯的PTB数据集实际上很⼩,只有90万个单词,⼤约5M,⼀个⽐较可⽤的语料库⾄少应该要有20G的⽂本,⼤概40亿单词。
有了词表之后,就可以开始编码了:
1.⼦词按⻓度从⻓到短排序;
2.对于输⼊的单词,遍历整个⼦词表,将单词匹配中的部分切分出来,如果有⽆法转化的⼦串,编码为特殊字符(如"")
举例:
有⼦词词典:[‘five’, ‘surviv’, ‘ing’, ‘worker’]
“five surviving workers”这句话将会编码为:
five -> [‘five’]
surviving -> [‘surviv’, ‘ing’]
workers -> [‘worker’, ‘’]
整句话的列表是:[‘five’, ‘surviv’, ‘ing’, ‘worker’, ‘’]那么,如何解码呢?从上⾯的例⼦可以看出,编码其实就是对单词进⾏切分的过程。所以,只要把切开的⼦串再拼接回去,就是解码。拼接过程中需要对部分特殊的字符(如:开头,结束等)做⼀些替换处理。
⼩结
本⽂介绍了⾃然语⾔的词元化(tokenization),并以BPE算法为例介绍了⼦词的编码解码⽅法。基于本⽂的内容,⼤家也可以理解为什么GPT的2000token只能有1500个左右的单词
转载自:https://zhuanlan.zhihu.com/p/636989211
token和loss的关系?
训练1个t的token















 1832
1832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









