







在上一节中我们简单介绍了进程的概念,还有父进程和子进程
这篇文章的主要内容是介绍如何使用fork函数创建子进程,fork函数的一些特点
查看进程的另一种方式
在上一节中主要使用ps命令列举进程条目,但我们知道,在Linux系统中,一切皆文件
因此所谓的进程条目,本质上也是存着的一个动态文件proc,这里面存放着所有的进程信息
因为这个文件是会随着进程的改变实时更新其中的内容,因此我们称之为动态文件
我们可以使用ls /proc/查看所有进程文件,也可以在其后加上特定进程的pid,查看特定进程
例如

我们同样可以创建一个死循环,然后来使用这个命令来查看其中的内容

在我们自行创建的进程当中存在着许多文件,这里有两个文件值得我们注意,一个是exe文件,另一个是cwd文件
其中exe文件指的是可执行程序的位置,而cwd代表默认的当前文件,或者可以简单理解为当前的文件路径,就好比pwd命令查看当前路径,他就是从cwd文件获取的路径
如何创建子进程
众所周知Linux的底层是使用c语言实现的,因此所谓的创建进程本质上就是调用了一个c语言函数,也就是用代码创建进程,而我们用户使用代码创建进程称之为系统调用,函数是fork
我们可以在c语言中写一个函数来直接调用看看情况
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("这是一个进程,pid是%d\n",getpid());
fork();
printf("This is a process, pid is %d\n",getpid());
sleep(1);
return 0;
}
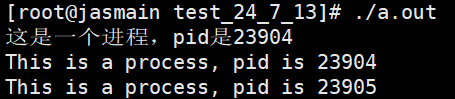
这里我们发现了第一个不对劲的地方,我明明只打印了一次英语的部分,但是输出结果却有两份
我们继续观察,如果我将这部分放在死循环里是什么样的
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("这是一个进程,pid是%d,ppid是%d\n",getpid(),getppid());
while(1)
{
fork();
printf("This is a process, pid is %d, ppid is %d\n",getpid(),getppid());
sleep(1);
}
return 0;
}
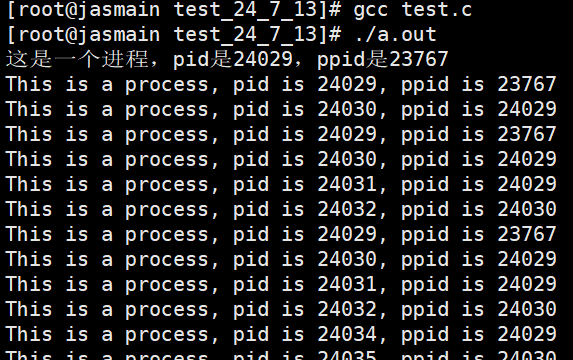
这里我们打印了进程id和父进程id,我们可以发现一些规律,其实也就是进程创建的子进程一直以他本身为父进程,然后这里的每一个子进程,又会一直创建他的子进程
fork函数详解
fork函数的用法
通过上面的代码,我们其实可以发现一点规律,在fork之前的代码,只有父进程执行,而fork之后的代码,父子进程都要执行
fork函数还有一个特别反直觉的内容,就是他的返回值有两个,分别返回给父子进程,并且父子进程受到的返回值还不相同
我们先不纠结这里的原理是什么,他这么设置肯定有这么设置的道理
首先返回值不同其实就可以在一段代码中区分父子进程了,这样就不至于写出特别乱的代码(执行起来特别乱,因为父子进程都会执行fork之后的代码),他的用法如下
int forkid = fork();
if(forkid==0)
{
// 子进程代码
}
else
{
// 父进程代码
}
这样就可以实现不同的进程,执行不同的操作的用法
我们可以使用这样的代码查看fork的返回值
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("这是父进程,pid是%d\n",getpid());
pid_t id = fork();
if(id==0)
{
while(1)
{
printf("这是子进程,在执行操作二,pid是%d,ppid是%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
while(1)
{
printf("这是父进程,在执行操作一,pid是%d,ppid是%d\n",getpid(),getppid());
sleep(1);
}
}
return 0;
}
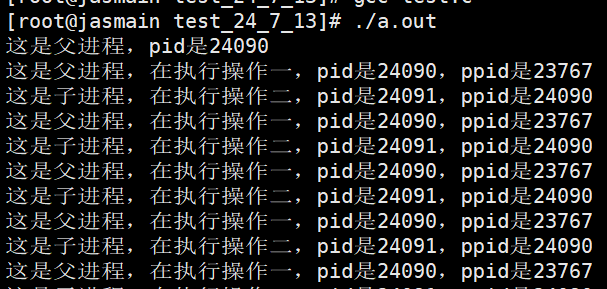
这样子两个执行流其实就不会互相干扰了
fork函数做了什么
当fork函数创建子进程时,操作系统就会以父进程为模板创建子进程的PCB,但此时子进程是没有代码和数据,他只能和父进程共享代码和数据,父子进程也就会执行相同的代码了
那么又因为一个父进程可以创建很多子进程,但是每一个子进程都有唯一确定的父进程,这就确保了父进程id的唯一性,类似于树的结构,当父进程获取到子进程id时,也就方便了父进程管理子进程
为什么fork有两个返回值
首先,我们需要了解一些fork函数大概的工作流程
- 找到父进程的PCB对象
- 为子进程开PCB,
malloc(task_struct) - 以父进程PCB为模板,初始化子进程PCB
- 让子进程PCB执行父进程中的代码和数据
- 让子进程进入调度队列,等待CPU处理
- …
- 返回
所以这里就很明显了,其实在子进程开新的PCB之后,就已经有了两个进程,两个执行流,自然也就有了两个函数、两个返回值,并且这两个函数还分属于不同的进程,才能有不同的返回值
父子进程的运行顺序是什么样的
这个问题看似很奇怪,但是考虑到我们CPU同时只能执行一项任务,也很好思考,进程的调度必须要有一个顺序
这里其实就说明,父子进程的运行顺序其实并非由用户决定,而是由PCB中的调度信息决定的,例如进程优先级、算法信息等,我们后面也会进行介绍
为什么fork函数的两个返回值不同
前面我们说明了为什么fork函数会由两个返回值,但是这两个返回值明明是一个变量,那么为什么同一个变量会有不同的值呢
首先我们需要明确一点,父进程本质上只是一个管理关系,父子进程本质上仍然是两个独立运行的进程,也就是说kill掉父进程,子进程仍然会运行(这时候子进程就处于一个特殊的状态,我们后续也会介绍),同样的kill掉子进程,父进程也是不会受到影响的
那么问题还是没有解决,操作系统是如何做到让数据在每个进程中都有一份的呢,其实就是我们之前学到类和对象管理的写时拷贝
当子进程想要使用父进程的数据时,就会拷贝一份到子进程的PCB中,这样子进程的变量如何变化也不会影响到父进程了,因此当fork函数返回时,也会触发写时拷贝,此时两个进程的id就不同了
fork函数的细节其实还有很多,但目前我们的目标还只是初步了解,等我们深入学习之后再回头来学习即可
















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











