







底层shared工程
1. 线程&线程池
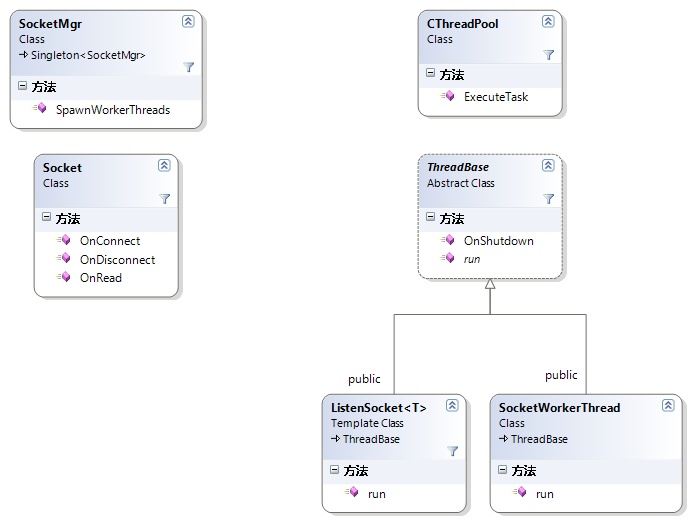
线程对象的基类ThreadBase提供了2个接口:
- virtual bool run() = 0;
- virtual void OnShutdown() {};
新建线程对象只需要从ThreadBase派生,并实现run接口。然后使用CThreadPool::ExecuteTask()将线程对象加入线程池中,线程池内部配一个空闲线程(如果没有就新建一个)去执行该对象的run函数。
ThreadBase有点类似ACE中的主动对象ACE_Task,不同的是ThreadBase本身没有线程,而是使用的线程池CThreadPool的线程。CThreadPool::IntegrityCheck以类似回调函数的形式供上层调用,释放或新加空闲线程来保证线程数量稳定在一个常数范围内。
注:实际上作为上层基类的类是从ThreadBase派生的CThread,封装了一些状态控制的操作。
2. 网络
Socket类
封装了SOCKET套接字的操作及读写同步和缓冲。其中缓冲区使用了一个封装的环形缓冲区CircularBuffer。使得上层应用处理TCP连接像”发送/接收操作没有一次完成”这种情况变得很简单。发送之后如果一次没有发完会在工作线程中接着发送(HandleWriteComplete中调用WriteCallback),而上层的接收操作如果发现数据没有接收完全,可以直接返回(工作线程会再投递一个recv操作),然后等待下次recv调用完成,直至接收数据包完成(可参看任何一个Socket派生类的OnRead)。
但是在Ascent中,消息处理都放在了OnRead中,这个还有改进的余地。更好的做法是当OnRead解析出一个完整的消息包之后,把拆出的应用数据交给上层应用的消息队列中,由应用处理线程去解析应用协议,而不是在通讯的工作线程中去处理。这样可以避免应用处理阻塞时整个通讯线程也跟着阻塞。
SocketMgr类
SocketMgr是一个单体对象(基本上Mgr都是从Singleton派生的),负责管理所有的Socket对象,SocketMgr在构造函数中会创建一个完成端口,并在线程池CThreadPool中添加一定数量的工作线程(SocketWorkerThread).SocketWorkerThread将从完成端口队列中取出完成操作,根据不同的操作调用相应的处理函数:
- if(ov->m_event < NUM_SOCKET_IO_EVENTS)
- ophandlers[ov->m_event](s, len);
这里使用了一种消息处理的方式,曾经见过一种说法叫跳跃表,但是也不太确定。就是将多个函数指针放入一个函数指针数组中,消息号(协议号)则作为函数指针数组的下标,从而可以直接调用相应的处理函数,而不必写多个case语句。其他很多地方,比如消息处理,也都是使用的这种方法。
在处理函数中会调用相应Socket类的虚函数接口(如OnRead)。通讯类只需要从Socket类派生并实现虚函数接口即可。 释放的socket会放入SocketGarbageCollector的队列中在update时删除。
ListenSocket
ListenSocket是一个模板类,其参数T是Socket类(或者其的派生类)。ListenSocket是从ThreadBase派生(而不是Socket类)。ListenSocket在构造函数中绑定一个监听端口,并在run()函数中接受连接,使用Accept的SOCKET(大写)初始化一个T类型的对象,然后调用T::Accept()绑定到完成端口(AssignToCompletionPort)并在完成端口投递一个recv操作(SetupReadEvent),然后加入到SocketMgr的Singlton对象中。
3. 数据库操作:
这里使用了一个 Factor Method模式,通过CreateDatabaseInterface接口,使用配置参数创建出一个子类对象,并返回一个Database指针。上层应用中只能使用Database的接口,从而可以将不同的数据库实现封装起来,并可以根据配置文件调整数据库类型。
这里提供了SQLite、MySQL、Postgres三种数据库的实现。
Database从CThread派生,并使用了数据库连接池,除了提供同步的查询外,还提供了:
异步执行sql。添加的sql语句可以加入队列中queries_queue,在Database的run函数中将以阻塞的方式从队列中取出查询语句执行。
异步的事务提交。批量sql语句以QueryBuffer的形式放在另一个队列query_buffer中。类class QueryThread : public CThread的run函数将调用Database::thread_proc_query函数,以事务的方式批量提交。
(这里描述起来很复杂,一看代码应该就明白了吧…..)
其他:
Vmap:这个是矢量地图。还有g3dlite好像是最近才加进来的。用于服务器端的地形判断,解决一些类似法师闪现穿墙的问题。这方面不熟,忽略之….
再其他就是一些工具性质的代码。其中CrashHandler.cpp中有关于程序崩溃后的内存转储的实现(生成.dmp文件)。能够通过打开在程序崩溃后产生的.dmp文件,直接定位到崩溃代码,找bug比较有用。)















 7118
7118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









