






1 需求:
获取专辑信息:
专辑名字,歌手,流派,语种,发行时间,发行公司,类型,介绍
以及专辑中的歌曲,歌手和时长
全部保存为json格式
2 分析页面
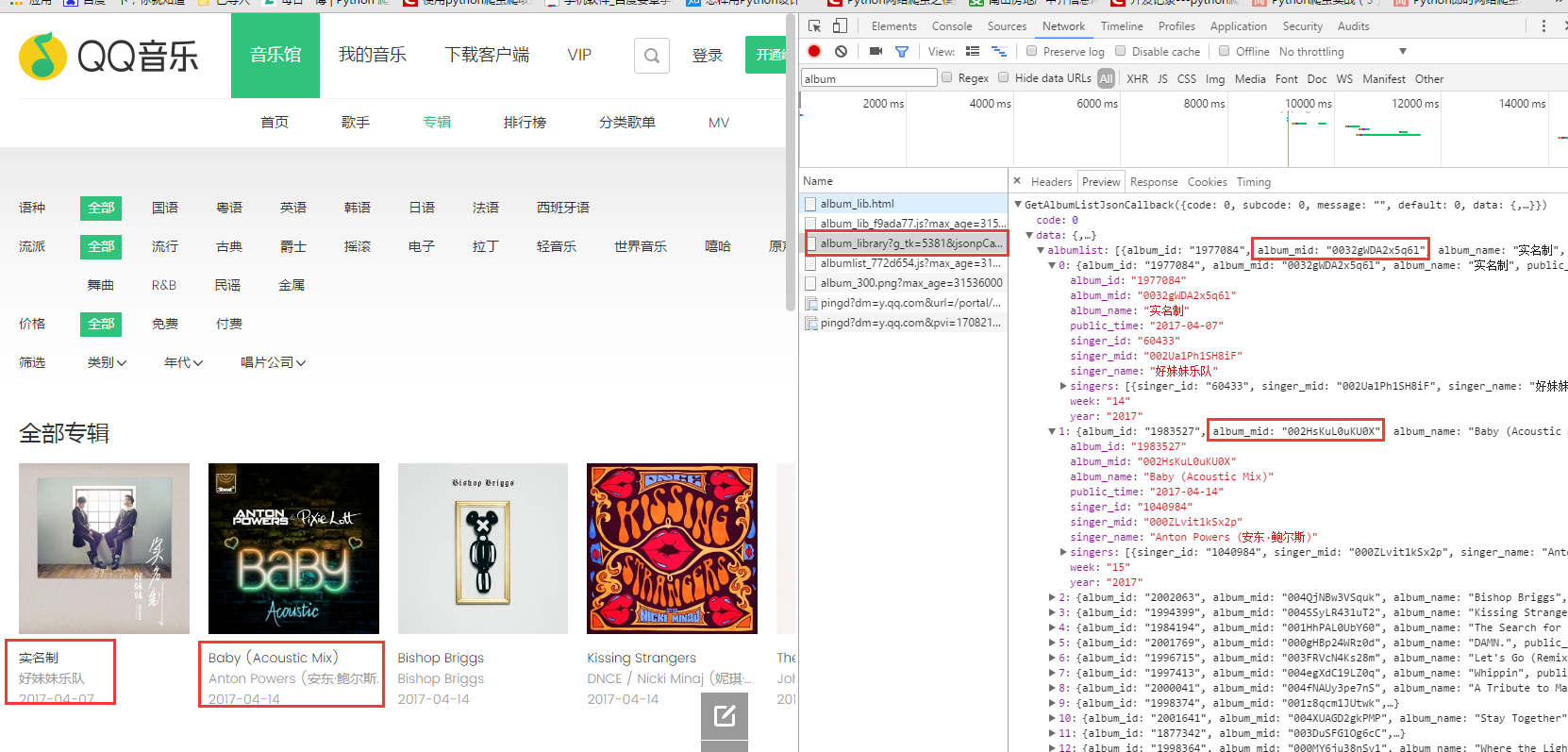
专辑链接所在的url为上图右方的链接:去掉多余参数则如下图所示:

page从0开始。
观察专辑的链接,


红框中的内容恰好是一图中的album_mid所对应的值。
打开专辑链接,要获取的内容如下:
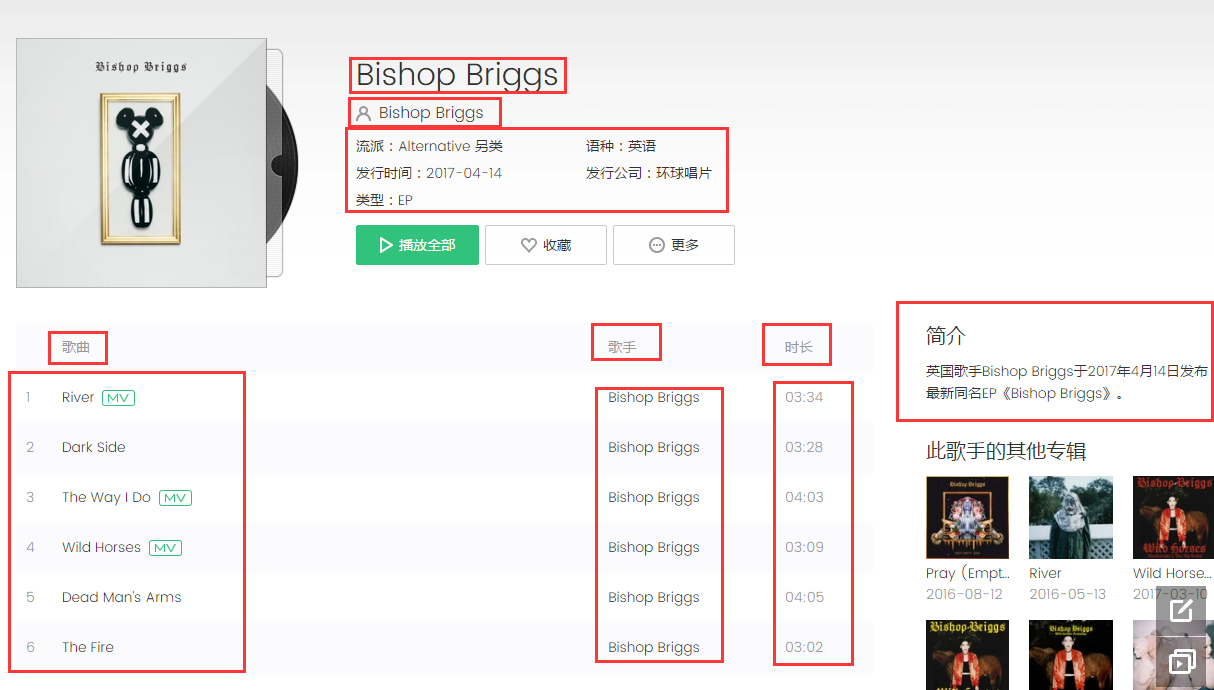
通过多次试着爬取,发现专辑中的信息并不统一,大概分为5类:
第一类:就是上图完整的类型
第二类:即完整类型中缺少了一个,要么是类型,要么是发行公司。需要进行判断。
第三类:

如图:没有歌手名字,并且是四个小字段。需要写判断。
第四类:

和上图是同种类型,但是是3个小字段。依旧需要写判断。
第五类:


这两种情况属于请求失败,当请求失败时,会直接返回null。此时创建空字典,让所有键对应的值为空。
下面是代码,写的不好,请多指教。
1 qq_music.py
# -*- coding: utf-8 -*-
"""
获取专辑信息
专辑名字,歌手,流派,语种,发行时间,发行公司,类型,简介
专辑中的歌曲,歌手和时长
数据全部存储为json格式(qqMusic0.json)
"""
import requests
import json
from bs4 import BeautifulSoup
import headers_file
import logging
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='qqM.log',
filemode='w')
class QQMusic:
def __init__(self):
pass
# 获取所有专辑的链接
def getAlbumLinks(self):
album_links = []
for page_num in range(1000): # page从0开始
base_url = 'https://c.y.qq.com/v8/fcg-bin/album_library?cmd=get_album_info&page='+str(page_num)+'&pagesize=20&sort=1'
logging.info(base_url)
time.sleep(10)
page = requests.get(base_url, headers=headers_file.request_headers())
html = page.content
# 替换掉开头结尾,用于json和字典的转换
html2 = html.replace('MusicJsonCallback(', '')
html3 = html2.replace('})', '}')
html_dict = json.loads(html3)
album_list = html_dict['data']['albumlist']
# 获取关键字album_mid的内容,拼接成专辑的链接
for album in album_list:
link_id = album['album_mid']
# print link_id
album_link = 'https://y.qq.com/n/yqq/album/'+str(link_id)+'.html'
album_links.append(album_link)
return album_links
# 获取专辑的详细信息
def getAlbumInfo(self, url):
logging.info(url)
album_dict = {} # 创建字典储存所有信息
try:
time.sleep(20)
info_page = requests.get(url, headers=headers_file.request_headers())
info_html = info_page.text
# print info_html
soup = BeautifulSoup(info_html, 'html.parser')
album_name = soup.find_all('h1', class_='data__name_txt')[0].get_text(strip=True) # 专辑名称
album_dict['album_name'] = album_name
# 有的也没有歌手,没有歌手信息的,以下5个小信息对应的key不同。
# 多出来的演奏,译名舍掉,key值存为空
singer = soup.find_all('a', class_='js_singer data__singer_txt') # 歌手
if len(singer) == 0:
info_all = soup.find_all('li', class_='data_info__item') # 演奏,发行时间,发行公司,译名,类型。
album_dict['singer'] = "null"
album_dict['music_genre'] = "null"
album_dict['language'] = "null"
# 有的也没有类型
if len(info_all) == 4:
pub_time = info_all[1].get_text(strip=True) # 发行时间
pub_company = info_all[2].get_text(strip=True) # 发行公司
album_dict['pub_time'] = pub_time
album_dict['pub_company'] = pub_company
# album_type = info_all[3].get_text(strip=True) # 类型
album_dict['album_type'] = 'null'
# 这个条件下有的info_all长度只有3, 只有发行公司、发行时间、类型
elif len(info_all) == 3:
pub_time = info_all[0].get_text(strip=True) # 发行时间
pub_company = info_all[1].get_text(strip=True) # 发行公司
album_dict['pub_time'] = pub_time
album_dict['pub_company'] = pub_company
album_type = info_all[2].get_text(strip=True) # 类型
album_dict['album_type'] = album_type
else:
pub_time = info_all[1].get_text(strip=True) # 发行时间
pub_company = info_all[2].get_text(strip=True) # 发行公司
album_dict['pub_time'] = pub_time
album_dict['pub_company'] = pub_company
album_type = info_all[4].get_text(strip=True) # 类型
album_dict['album_type'] = album_type
else:
singer2 = singer[0].get_text(strip=True)
album_dict['singer'] = singer2
info_all = soup.find_all('li', class_='data_info__item') # 流派,语种,发行时间,发行公司,类型等信息在一起
# 有的没有发行公司,长度为4,完整的5个都有,长度为5
# 突然发现,有的也没有类型。。。。
if len(info_all) == 4:
music_genre = info_all[0].get_text(strip=True) # 流派
language = info_all[1].get_text(strip=True) # 语种
pub_time = info_all[2].get_text(strip=True) # 发行时间
unknown = info_all[3].get_text(strip=True)
if '发行公司' in unknown:
pub_company = unknown
album_dict['pub_company'] = pub_company # 发行公司
album_dict['album_type'] = "无"
if '类型' in unknown:
album_type = unknown
album_dict['album_type'] = album_type # 专辑类型
album_dict['pub_company'] = "无"
album_dict['music_genre'] = music_genre
album_dict['language'] = language
album_dict['pub_time'] = pub_time
else:
music_genre = info_all[0].get_text(strip=True) # 流派
language = info_all[1].get_text(strip=True) # 语种
pub_time = info_all[2].get_text(strip=True) # 发行时间
pub_company = info_all[3].get_text(strip=True) # 发行公司
album_type = info_all[4].get_text(strip=True) # 专辑类型
album_dict['music_genre'] = music_genre
album_dict['language'] = language
album_dict['pub_time'] = pub_time
album_dict['pub_company'] = pub_company
album_dict['album_type'] = album_type
album_intro = soup.find_all('div', class_='about__cont')[0].get_text(strip=True) # 专辑简介
album_dict['album_intro'] = album_intro
# 有的专辑简介为空
if len(album_intro) == 0:
album_intro = "null"
album_dict['album_intro'] = album_intro
# 专辑内的所有歌曲信息
song_list = []
songs = soup.find_all('span', class_='songlist__songname_txt') # 歌名
for i in songs:
song = i.get_text(strip=True)
song_list.append(song)
artist_list = []
artists = soup.find_all('div', class_='songlist__artist') # 演唱者
for i in artists:
artist = i.get_text(strip=True)
artist_list.append(artist)
time_list = []
song_time = soup.find_all('div', class_='songlist__time') # 时长
for i in song_time:
time_minute = i.get_text(strip=True)
time_list.append(time_minute)
album_info = zip(song_list, artist_list, time_list)
album_info2 = []
for item in album_info:
songs_list = dict()
songs_list['song'] = item[0]
songs_list['who_sing'] = item[1]
songs_list['time'] = item[2]
album_info2.append(songs_list)
album_dict['album_info2'] = album_info2
# print album_dict, url
return album_dict
except Exception as e:
logging.info(e)
# 有的页面会请求失败,一个是版权无法查看,一个是找不到该页面,此时返回空字典,value全部为null
album_dict['album_name'] = "null"
album_dict['singer'] = "null"
album_dict['music_genre'] = "null"
album_dict['language'] = "null"
album_dict['pub_time'] = "null"
album_dict['pub_company'] = "null"
album_dict['album_type'] = "null"
album_dict['album_intro'] = "null"
album_dict['album_info2'] = "null"
return album_dict
2 music_thread.py
# -*- coding: utf-8 -*-
import threading
import Queue
from qq_music import *
q = Queue.Queue()
lock = threading.Lock()
qm = QQMusic()
class MusicThread(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self):
while True:
if self.queue.qsize() > 0:
url = self.queue.get()
f = open('qqMusic0.json', 'a+')
try:
content = qm.getAlbumInfo(url)
lock.acquire()
f.write(json.dumps(content)+'\n')
lock.release()
f.close()
except Exception as e:
logging.error(e)
continue
else:
logging.warn('none')
break
def main():
for url in qm.getAlbumLinks():
# print url
q.put(url)
ts = []
for i in range(20):
t = MusicThread(q)
t.setDaemon(True)
t.start()
ts.append(t)
for t in ts:
t.join()
if __name__ == '__main__':
main()
3 headers_file.py
用来轮换user_agent
昂,有一个错误:

这是在服务器上跑数据,日志中写入的错误。应该是请求过快了,设置睡眠也无济于事,只好在本机上自己跑数据了。
有没有知道这该怎么处理的小伙伴呐,多谢指教。啦啦啦啦~~~















 1778
1778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









