







独热编码(one-hot code):
只有一个比特为1其它全为0的一种码制,本质是对离散性分类进行数据化。
距离0-9的数字进行独热编码,5的编码为:0000010000
作用就是来处理非连续型数值特性,例如性别[男、女、其它]可以独热成[100,010,001];也可以计算之间的欧氏距离(推荐算法等用来求相似度);方便特征组合。
过于稀疏的矢量也会带来新的问题:数据量庞大、计算量溢出。
奥卡姆剃刀定律:
切勿浪费较多东西去做用较少的东西同样可以做好的事情翻译到ML领域就是:只要能搞定,模型越简单越好
由奥卡姆剃刀定律给我们的灵感,将模型的复杂度带入cost function中,这种原则就是正则化。也就是说训练的优化过程不仅要考虑到“预测与实际值之间的损失项”,还要考虑到“模型的复杂度”,其中后者是以系数λ的形式参与进来的。
L2正则化:权重的平方和。

越大的w对模型的影响越大,越小的w对模型的影响微乎其微,所以我们尽量想给小权重更多的机会,打压大权重。
引入L2正则化后的cost function如下:
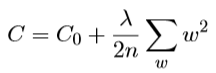
λ过大,使训练集数据失去意义,会出现欠拟合;λ过小,使剃刀失去意义,变成了一个普通的损失函数,会出现对训练集的过拟合。
讲到了L2就不得不说下L1,L1是w的绝对值求和,所以对L2求导后是2|w|,而L1求导后是常量。所以引入λ后L2是成比例的下降,但是永远是趋于0但不会降到0;而L1是按常数下降,最终会降为0。所以使用L2是为了解决过拟合,使用L1是为了将高度稀疏的矢量中将部分权重降为0从而从模型中移除,减少计算开销,也能减少模型中的噪点。
分类不平衡数据集:
如果某数据集90%的结果为1,10%的结果为0,那么我只要一股脑的全都预测1我的准确率也有90%,但是这明显是不科学的。所以对于这种分类不平衡的数据集需要引入其它参数来体现预测的好坏。
准确率:预测正确的概率,这个很好理解。
精准率:预测为真时的正确率。预测10次真,有3次是真的真,有7次是假的,那么精确率是30%。
召回率:真正是真被识别出来的概率。假如有10个真,我们预测了4个真6个假,那么召回率是40%。
召回率和精准率是一对矛盾的,此消彼长,他们矛盾的地方就是对模棱两可的数据要预测成1还是0呢?如果预测的激进一点,很容易将不是1的预测成1,那么精确率就会下降。如果预测的保守一点,很容易将原本是1的预测称0,造成召回率下降。
ROC曲线下的面积被称为AUC,AUC越大模型的判断越好。
Softmax:
Softmax虽然可以配合对数可以解决深层网络的梯度消失问题,但是应用场景有限制:
如果要被预测的结果在业务场景上允许同时出现多个结果则不能使用SoftMax。
推荐系统:
我现在掌握的推荐系统有2个大方向,3个小方向的。
大方向是,一种是基于协同过滤的;一种是基于内容的。其中基于协同过滤又可以拆分成基于用户和基于物品的。
假如我们现在要做一个餐馆推荐系统,我们现在有上海市所有的餐馆和用户消费记录,如果有M个餐馆N个用户,我们可以构造一个N*M的矩阵集,只不过不可能每个人都吃过所有的餐馆,所以这个矩阵比较稀疏。
基于用户的协同过滤:每个用户去过的餐馆为一条记录,找到与这个用户消费的餐馆比较相似的用户群,然后从这批用户群中找到该用户还没有吃过哪些餐馆。
基于餐馆的协同过滤:每个餐馆来过的客人为一条记录,找到来与这个餐馆消费客户群相似的餐馆,然后这些相似的餐馆中该客户哪个还没去过就推荐哪个。
基于内容来推荐:就是把所有餐馆的菜品分门别类,北京烤鸭、鱼香茄子、九转大肠、东北拉皮等等,我们来给用户推荐包含他喜欢吃的菜的餐馆。但是基于内容的并不适用于全部场景,例如图片、音频等无法来筛检里面的内容。
以上所有实现方式都涉及到求相似度的问题,需要用到欧氏距离、皮尔逊、余弦相似度等算法。
欧氏距离相似度:
相似度=1/(1+欧氏距离)
皮尔逊相似度:
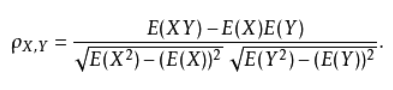
余弦相似度:
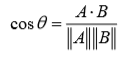
神经网络:
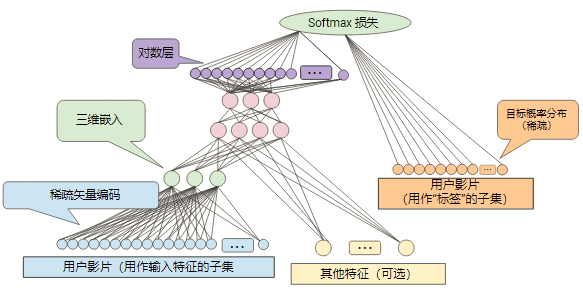
我以前接触到的网络都是标准的一层层的,从这一层到下一层,最近接触到新的神经元更像是树状的,不同的小网络组织成一个大网络,如下:















 6462
6462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









