







1 python 语法规范
1.1 输入输出
1.1.1 输出语句的两个参数及转义字符
end = "\n" #结束符
sep = "空格" #多对象分隔符
+ #连接
* #复制
# 输出 你好,世界
# 语句隐藏参数 end = "\n" ,省略时语句输出后,自动换行
print ("你好, 世界", end = "\n")
# 输出 你好, 世界1 你好, 世界2
print ("你好, 世界1", end = "\t")
print ("你好, 世界2")
# 输出 你好 中国
# 语句隐藏参数 sep = " " , 省略时多对象分隔符默认用空格
print ("你好","中国", sep = " ")
# 输出 你好,中国
# 语句参数 sep = "," , 指定多对象分隔符为逗号
print ("你好","中国", sep = ",")
# 语句复制多次
# 输出 你好,世界你好,世界你好,世界
print ("你好,世界" * 3)
# 语句字符串连接
# 123456
print ("123" + "456")
# 字符串中存在斜杠,语句前加r输出原始语句
# 输出路径 C:\abc\def\npq.xls
print (r"C:\abc\def\npq.xls")1.1.2 输入
语法:input("提示信息")
使用输入语法的时候注意要把input用户输入的内容赋值给一个变量。
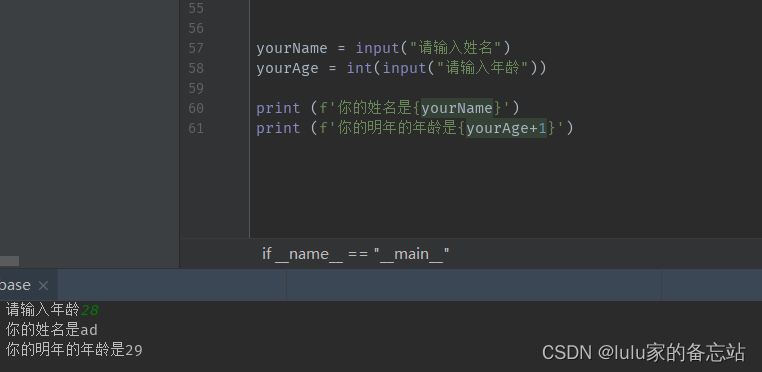
yourName = input("请输入姓名")
yourAge = int(input("请输入年龄"))
print (f'你的姓名是{yourName}')
print (f'你的明年的年龄是{yourAge+1}')在控制台进行输入,回车执行下一句。
注意input语句接收的都为字符串类型,如果后面需要进行数字运算,需要先转格式。
1.2 换行与缩进
python 语法总结
(1) 一条代码作为一行
(2)对齐和缩进:同一级别的代码保持对齐,不同级别的代码进行缩进以区分代码执行的逻辑。
1.3 模块导入
import 模块.子模块
使用时以 模块.方法 的形式调用
from (模块) import 子模块
使用时以 子模块.方法 的形式调用
1.4 注释
单行注释 #
多行注释 3个单引号或者3个双引号
""" '''
内容 内容
""" '''
多行注释快捷键: 选中代码块,ctrl+/
1.5 变量
1.5.1 变量定义和赋值
变量命名要求:变量由数字、字母及下划线任意组合而成、唯一的约束是变量的第一个字符必须是字母或下划线,而不能是数字。
赋值不需要类型声明,变量可以存储任何值。
每个变量在内存中创建,都包括变量的标识、名称和数值这些信息。
变量赋值:用等号 =
变量不仅仅可以赋值各种类型,还可以随意改变类型。
a = 100
print (type(a)) #打印出a 为int 型
a = 3.11
print (type(a)) #打印出a 为float 型
a = "john"
print (type(a)) #打印出a 为str 型
多变量赋值
变量1,变量2,变量3 = 1, 2, 3
变量1 = 变量2 = 变量3 = 2
交换变量赋值
x = 5
y = 2
print (x) # x = 5
print (y) # y = 2
x,y = y,x
print (x) # x = 2
print (y) # y = 5语法 f'{变量表达式}'
name = "Allen"
age = 19
print (f'我的名字叫{name}, 今年年龄{age}岁')
print (f'我的名字叫{name}, 明年年龄{age+1}岁')
1.5.2 局部变量和全局变量
局部变量:对某一部分代码产生作用,这一部分代码结束会被回收。
全局变量:对整个文件产生作用,程序结束才会被回收。
一般定义在文件开头,不能放在某个函数中,这样的话才能被其他文件或函数调用,调用时通过 global+变量的方式引用全局变量。
全局变量的值可以被函数所改变,并以最后一次改变的值作为最终的值。万不得已不要修改全局变量。
#全局变量
a = 1
def fun():
global a #声明a是一个全局变量
print (a)
if __name__ == "__main__":
fun()
print(a)
def fun2():
global a #声明a是一个全局变量
a = 3 #修改全局变量
if __name__ == "__main__":
fun2()
print(a) # a =31.6 运算
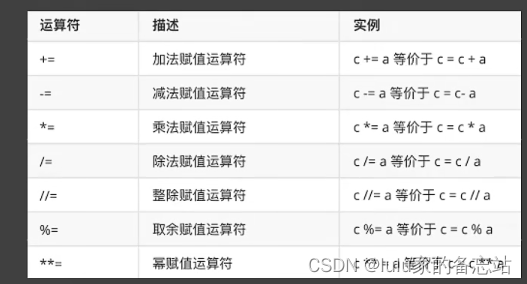
1.6.1 算术运算

复合运算
1.6.2 关系运算
关系运算优先级低于算术运算。
返回True和False

1.6.3 逻辑运算

1 and 4 返回4,4 and 1 返回1, 0 and 1 返回0
4 or 3 返回4,3 or 4 返回 3, 4 or 0 返回 4, 0 or 0 返回0
1.6.4 计算优先级
运算优先级原则
(1)括号内优先运算
(2)幂运算(指数) **
(3) 正负号 + -
(4)算术运算 *,/,//,%,+,- 先乘除后加减,从左往右依次运算
(5)比较运算 <、<=、>、>=、==、!=
(6)逻辑运算 not、and、or 先not后and最后or
1.7 数据类型转换
int() 转整型、float()转浮点型、str() 转字符型
序列之间的数据转换:
我们将字符串、列表、元组统称为序列
list(序列名) #将序列转化为列表
tuple(序列名) #将序列转化为元组
set(序列名) #将序列转化为集合,有自动去重的作用
2 数据结构
可变类型和不可变类型
可变类型:当变量值改变时,id内存地址不变。包括列表、字典、集合
不可变类型:当变量值改变时,id内存地址改变了。包括整型、浮点型、字符串、元组
所谓可变与不可变:数据能直接进行修改的就是可变,否则就是不可变的
使用id(变量名)可以查询id内存地址。
有序序列和无序序列
有序序列:有序,意味着有下标,可以用下标进行索引。可以进行下标操作、切片操作。列表、元组、字符串。
无序序列:无序,不能进行下标操作。字典、集合。

enumerate(可遍历对象, start = 0)
start参数用来设置遍历数据的下标的起始值,默认为0
2.1 列表
定义list 变量名=[元素1,元素2,元素3,...]
定义空列表: list=[]
由于列表是可变数据,增删改后,原列表的数据变了。
【增】
list.append(元素) : 在列表结尾追加单个数据。
list1.extend(list2) :在列表结尾追加多个数据。调用列表1的扩展方法加入列表2,并将列表2的元素放在列表1元素的后面。
list.insert(索引位置, 元素) :在指定位置追加数据。
list1 + list2 : 直接通过列表相加方式将list2 合并到list1 后面。
【删】
list.remove(元素) :移除列表中的第一个匹配项
用关键字del删除:
del 变量名 删除整个列表变量,不是清空
del list[下标] 删除列表里指定元素
list.pop(下标) :删除指定下标的数据,不指定则默认最后一个,并返回删除的数据
list.clear() :清空列表,返回空列表[]
【改】
list[n] = 元素 :
list.reverse() : 把整个列表倒序排列
list.sort(reverse= False/True) : 排序 reverse=False 默认升序,降序则指定参数reverse=True
【查】
list.index(元素, 开始位置下标, 结束位置下标) :查找指定元素的是否在列表指定范围中,在则返回元素下标,不在则报错
list.count(元素) :统计指定元素在当前列表中出现的次数
len(list) : 计算list列表的长度
【复制列表】
list.copy() : 复制列表
【遍历列表】
for i in list:
print(i)
2.2 元组
元组可以存储多个数据(可以重复),且里面的数据不能被修改(只读)。一个元组中存储的数据可以是不同类型。
定义tuple 变量名=(元素1,元素2,元素3,...)
定义空元组: tuple=()
定义一个元素的元组: tuple=(1,) ,一定要带逗号,不加就是元素的类型,不是元组
元组的查询和列表类似。因为元组不能被修改,所以没有增改清空的方法。
删除元组也可以用del 关键字。

2.3 字典
字典是按key和value的方式成对出现,也叫键值对。
字典里的数据和顺序无关,不支持下标,字段通过键来作为索引的,不是下标。
定义字典: 变量名= {键:值, 键:值, 键:值,键:值...}
空字典:变量名={}
【增】
dict[键] = 值
如果键存在则修改对应的值,如果键不存在,则新增这个键和值。
dict.update(dict2): 将dict2中的元素追加到dict中,如果有重复的键,则会替代已有的键。
【删】
del 关键字 或者 del() :
del(dict["键"]) 键值一起删除
del dict 删除整个字典
dict.clear(): 清空字典
【查】
只能用键查询,不能用值查询。键是唯一的。如果键存在,则返回值,否则报错。
dict[键]
dict.get(键, 键不存在时返回的指定默认值) :
如果键存在,则返回值,否则返回默认值,如果没有设置默认值,则返回None。
dict.values(): 返回字典中所有的值
dict.items(): 返回可迭代对象(里面的数据是元组),迭代就是重复反馈的过程。
dict = {"Alice": 10, "Bob": 14, "Dude": 20, "Ellen": 35}
print(dict.values()) #输出dict_values([10, 14, 20, 35])
print(dict.items()) #输出dict_items([('Alice', 10), ('Bob', 14), ('Dude', 20), ('Ellen', 35)])
#遍历字典的键和值
for i,j in dict.items():
print(f'{i}:{j}')
#输出
#Alice:10
#Bob:14
#Dude:20
#Ellen:35
遍历字典的键:
for 键 in dict.keys():
print(键)
遍历字段的值:
for 值 in dict.values():
print(值)
遍历字典的元素:
for 元素 in dict.items():
print(元素)
遍历字典的键和值:
for 键, 值 in dict.items():
print(f'{键} = {值}')
2.4 集合
集合里没有重复的数据,顺序是随机的,不支持排序,不支持下标。用{}。
定义集合: 定义有元素的集合 set = {元素1, 元素2, 元素3,,元素4...} 如果有重复数据,只保留一个自动去重。
创建空集合: set=set() 不能用set={} 因为这是创建空字典的方法。
【增】
set.add(数据) :集合指定去重,增加相同的元素时不进行任何操作。
set.update(数据序列): 追加的数据序列可以是列表、字符串(追加字符串的字符)、元组、字典(追加字典的key)。追加时也会去重。
set = {1,2,3,4,5}
set.update((1,2,4,7,8))
print(set) #{1, 2, 3, 4, 5, 7, 8}
set.update({1,2,4,7,8,9,0,3})
print(set) #{0, 1, 2, 3, 4, 5, 7, 8, 9}
set.update("hello")
print(set) #{0, 1, 2, 3, 4, 5, 'o', 7, 8, 9, 'h', 'e', 'l'}
set.update({"a":1,"b":2,"c":"long","ketty": 909})
print(set) #{0, 1, 2, 3, 4, 5, 'o', 7, 8, 9, 'ketty', 'h', 'e', 'a', 'l', 'c', 'b'}
set.update(["david","pop","you"])
print(set) #{0, 1, 2, 3, 4, 5, 7, 8, 9, 'b', 'h', 'l', 'a', 'pop', 'ketty', 'e', 'o', 'david', 'you', 'c'}
【删】
set.remove(数据): 如果数据不存在,报错
set.discard(数据):如果数据不存在,不报错
set.pop() : 随机删除集合中的某个数据,并返回这个数据。可用于记录删除的数据。
【查】
in :判断数据是否在集合序列中,返回True or False
not in :判断数据是否不在集合序列中,返回True or False
3 语句
3.1 条件语句
if 条件:
条件1成立执行的代码
elif 条件2:
条件2成立执行的代码
elif 条件3:
条件3成立执行的代码
else:
以上条件都不成立执行的代码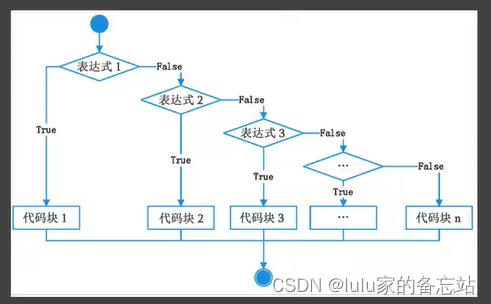
条件语句的嵌套
if 条件1:
条件1成立执行的代码
if 条件2:
条件2成立执行的代码
else:
条件2不成立执行的代码
else:
条件1不成立执行的代码三目运算
条件成立执行的表达式 if 条件 else 条件不成立执行的表达式
用于比较简单的条件判断。
c = a if a>b else b
3.2 for循环语句
for语句
for 临时变量 in 序列:
重复执行的代码块
break 终止循环
continue 退出本次循环,继续执行下一次循环
for....else语句
for 临时变量 in 序列:
重复执行的代码块
else:
循环正常结束后要执行的代码
break 终止循环,循环没有正常结束,不会执行else的代码
continue 循环正常结束,会执行else的代码
常用的for使用场景
(1) #获取可遍历对象(元组、列表、字符串)的下标和对应元素
for tag,data in enumerate(可遍历对象):
print(f’下标是{tag},数据是{data}‘)
(2) #创建一个由0-10组成的列表
list=[]
for i in range(11):
list.append(i)
# 创建[0,2,4,6,8,10]
方法1: list = [ i for i in range(0,11,2)] 遍历0-11之内的偶数,利用range函数指定步长
方法2: list = [i for i in range(0,11) if i%2 == 0] 利用整除2获取偶数
(3) #将两个列表快速合并成一个字典
语法: dict = {list1[i]: list2[i] for i in range(len(两个list中长度最短的那个))}
已有list1, list 2,合并成dict,键值分别来自两个列表的元素
list1 = ['华为', '小米','苹果', '三星']
list2 = [520,100,233,298]
dictMerge = {list1[i]: list2[i] for i in range(len(list1))}
print(dictMerge) # {'华为': 520, '小米': 100, '苹果': 233, '三星': 298}(4) 提取字典中的目标数据
dictNew = {i:j for i,j in dict.items() if j > 250}
已有字典dict,要求提取值大于250的字典数据
dict = {'华为': 520, '小米': 100, '苹果': 233, '三星': 298}
dict = {'华为': 520, '小米': 100, '苹果': 233, '三星': 298}
dictNew = {i:j for i,j in dict.items() if j > 250}
print(dictNew) #{'华为': 520, '三星': 298}3.3 while循环语句
while循环是不断地运行,直到指定的条件不满足为止。
while 条件:
条件成立时执行的代码块,执行完后再判断条件,为真继续执行下一次代码,为假结束
break 终止循环,不是正常结束
continue 退出本次循环,继续下一次循环,正常结束
else:
循环正常结束之后要执行的代码
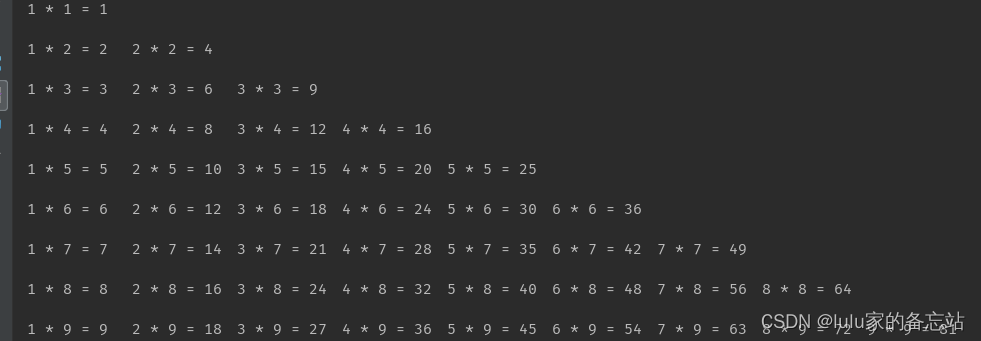
示例:打印九九乘法表
n = 1
while n <= 9:
m = 1
while m <= n:
print(f'{m} * {n} = {m * n}', end='\t')
m = m + 1
print('\n')
n = n +1运行结果:
4 字符串基础及处理
1、特殊字符串的输出
例如想输出 I'm ad
print("I\'m ad")
2、下标,又叫索引
从0开始,标点、一个英文字母、一个中文都算一位
3、切片(支持字符串、列表、元组)
语法: 变量名[开始位置下标:结束位置下标:步长]
注意:
(1)下标范围含头不含尾
开始位置下标:包含开始位置下标对应的数据
结束位置下标:不包含结束位置下标对应的数据,
(2)省略起始值,默认从0开始;省略结束值,默认到最后
(3)下标正负整数均可,负数表示倒数,-1表示倒数第一个数据
(4)步长
a. 如果步长为正,表示从前往后取(从开始下标到结束下标),这个时候开始下标对应的元素必须在结束下标对应的元素的前面,否则结果是空
b. 如果步长为负,表示后后往前取(从开始下标到结束下标),这个时候开始下标对应的元素必须在结束下标对应的元素的后面,否则结果是空
str = "0123456"
示例:
print(str[1:4]) 输出"123" print(str[::2]) 输出"0246"
print(str[1:4:1]) 输出"123" print(str[:-1]) 输出"012345"
print(str[:6]) 输出"012345" print(str[-4:-1]) 输出"345"
print(str[1:]) 输出"123456" print(str[::-1]) 输出"6543210"
print(str[:]) 输出"0123456" print(str[::-3]) 输出"630"
print(str[-6:-1:-2]) 输出"" 结果为空,因为从后往前取,开始下标在结束下标之前
print(str[-1:-6:-2]) 输出"642"
4.1 字符串的转换
python内置函数str()可以将任何类型的数据转化成字符串。
需要注意的是只转换数据类型,并不会改变数据打印出的结果
4.2 字符串的合并
字符串的合并使用“+”即可合并字符串。
python会根据“+”两侧的数据类型决定是连接操作还是运算,而不同类型的数据是无法合并的。
因此如果两侧数据存在非字符串类型的数据,需要先用str()转化成字符串类型。
join() :合并。用一个指定的字符或子串将元素连接起来,生成一个新的字符串。
语法:指定用于连接的字符或子串.join(seq)
seq: 代表要连接的元素序列,可以是字符串、元组、列表、字典(其中字典只连接key值,不连接value值,且如果有相同key出现,则只连接第一个,其他忽略)等。元素必须为string型,是其他类型则会报错。
os.path.join(Path1,Path2,Path3,...): 把path1、path2、path3...等用 \ 连接起来,组成文件路径。
Python中的join函数-腾讯云开发者社区-腾讯云 (tencent.com)https://cloud.tencent.com/developer/article/1694327
4.3 字符串的查找
str.find(): 查询某个子串是否包含在这个字符串中,如果在返回这个字串开始位置下标,否则返回-1
语法 字符串.find(子串, 开始位置下标, 结束位置下标)
find()是字符串从左往右查, rfind()是从右往左查
str.index(): 查询某个子串是否包含在这个字符串中,如果在返回这个字串开始位置下标,否则报错不继续执行程序(和find()的区别)
语法 字符串.index(子串, 开始位置下标, 结束位置下标)
index()是字符串从左往右查, rindex()是从右往左查
str.count() :返回某个子串在字符串中出现的次数,没有则返回0
语法 字符串.count(子串, 开始位置下标, 结束位置下标)
示例:
str2 = "hello, you are excellent"
print(str2.find("el"))
print(str2.index("el"))
print(str2.index("uu"))
print(str2.count("el"))运行结果:

4.4 字符串的截取
索引截取
即前面说到的切片的形式,依赖字符的索引进行截取。
str.split()截取
split():分割。使用字符串自带的split()函数将数据分割成一段一段(分割符号为原来字符串里自带的符号),并以元素的形式放入列表之中,然后再通过索引截取相应的字符串。
语法:字符串.split(分割字符,分割次数)
分割次数:不写则按分割字符出现的次数分割。
分割后分隔符是会被去掉的。分割后原字符串不变。
这种方式适合有固定格式的多个字符串组成的长字符串。
str5 = "a=abc,b=123,cddd,(1,2)"
afterSplit = str5.split(",",2)
print(type(afterSplit))
print(afterSplit)
print(afterSplit[2])
#如果想取得abc,可以进行多次分割
print(afterSplit[0].split("=")[1])运行结果:

正则表达式截取
4.5 字符串的替换
replace() :替换
语法:字符串.replace(旧子串, 新子串, 替换次数)
如果指定替换次数,则从左至右按照顺序和次数替换。
替换次数如果超过了子串的出现次数,就替换所有子串,省略替换次数就是全部替换。
如果匹配不到要替换的子串,不会报错,返回原来的字符串。
str3 = "你好,世界!^你好,中国!^我们一起学习中国话!^中国加油!"
str4 = str3.replace("你好","你们好",2)
print(str3) #你好,世界!^你好,中国!^我们一起学习中国话!^中国加油!
print(str4) #你们好,世界!^你们好,中国!^我们一起学习中国话!^中国加油!注意:replace()函数只是替换其副本,并不会改变原来的字符串的值(内存地址不一样),因为字符串类型是不可变类型。需要得到替换后的字符串,可以将替换后的副本赋值给新的变量。
4.6 字符串的判断
startswith() : 检查字符串是否以子串开头,是则返回True,否则返回False
语法:字符串变量.startswith(子串, 开始位置下标, 结束位置下标)
endswith() :检查字符串是否以子串结尾,是则返回True,否则返回False
语法:字符串变量.endswith(子串, 开始位置下标, 结束位置下标)
若省略开始位置下标, 结束位置下标,则是判断范围是整个字符串
5 函数
函数必须先定义再调用。
5.1 定义函数
#定义函数
def 函数名(形参):
"""函数说明文档位置"""
代码块
5.2 函数的形参类型
1、位置参数:在定义函数时,参数的名字和位置已被确定
def 函数名(姓名, 年龄, 性别):
print(f‘您的姓名是{姓名},性别是{性别},年龄是{年龄}')
调用:函数名(“Alice”,20,’女‘)
2、关键字参数:传入实参时,通过“键=值”的形式加以指定,参数之间不存在先后顺序。如果同时有位置参数,位置参数必须在关键字参数的前面。
def 函数名(姓名, 年龄, 性别):
print(f‘您的姓名是{姓名},性别是{性别},年龄是{年龄}')
调用:函数名(“Alice”,性别=’女‘,'年龄'=20)
3、默认参数(缺省参数):参数指定默认值,调用时不传实参,就用默认值
def 函数名(姓名, 年龄, 性别=’女‘):
print(f‘您的姓名是{姓名},性别是{性别},年龄是{年龄}')
4、位置可变参数:接收所有的位置参数,返回一个元组
def 函数名(*args):
print(args)
调用:函数名("Alice",’女‘,20) 打印args为('Alice','女',20)
5、关键字可变参数:接收所有关键字,返回一个字典
def 函数名(**kwargs):
print(kwargs)
调用:函数名(name = "Alice", gender = ’女‘,age = 20) 打印kwargs为{'name': 'Alice', 'gender': '女', 'age': 20}
5.3 函数返回值return
遇到 return 退出当前函数,后面的语句不再执行。多条return只执行第一个。
return 后面可以连接列表,元组 或字典、表达式,也能返回多个返回值。
元组拆包:
多个返回值写成return a,b 返回的是一个元组(a,b),可以把返回值按照顺序复制给多个变量。
#函数返回值之元组拆包
def mulReturn():
return 520,1314
a1,a2 = mulReturn()
print(a1) #520
print(a2) #1314字典拆包:
#函数返回值之字典拆包
dictEE = {'name': 'Bob', 'age': 20, 'city': 'Beijing'}
def mulReturnDict():
return dictEE
b1, b2, b3 =mulReturnDict()
print(b1) #name
print(b2) #age
print(b3) #city
print(dictEE[b1]) #Bob
print(dictEE[b2]) #20
print(dictEE[b3]) #Beijing5.4 递归
递归:函数内部自己调用自己,必须留有出口。

5.5 函数式编程
5.5.1 lambda表达式
什么时候用lambda表达式?当函数有一个返回值,且只有一句代码,可以用lambda简写。
语法:lambda 形参:表达式
注意:
1、形参可以省略,函数的在lambda中也适用
2、lambda函数能接收任何数量的参数,但只能返回表达式的值
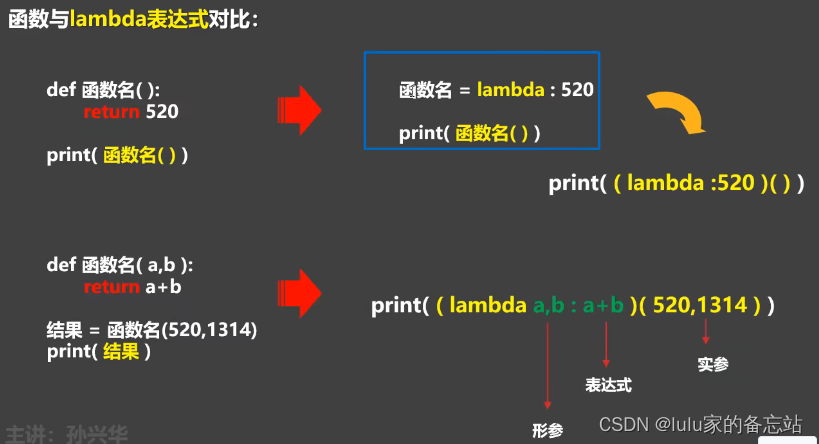
5.5.2 lambda 参数形式
1、无参数
print((lambda :520)())
2、一个参数5.5.
print((lambda a : a*10)(20))
3、默认参数
print((lambda a,b,c=5 : a+b+c)(2,6))
4、可变位置参数
print((lambda *args:args)(1,2,3)) #(1, 2, 3)
5、可变关键字参数
print((lambda **kwargs:kwargs)(姓名='Kelly',年龄 = 20,城市='北京')) #{'姓名': 'Kelly', '年龄': 20, '城市': '北京'}
5.5.3 带条件的lambda表达式
print((lambda a,b : a if a>b else b)(5,1)) #5
5.5.4 列表中的字典数据排序
list3 = [{'name':'A','age':30},{'name':'B','age':23},{'name':'C','age':40}]
list3.sort(key= lambda x : x['age'],reverse= True) #按年龄倒序
print(list3) #[{'name': 'C', 'age': 40}, {'name': 'A', 'age': 30}, {'name': 'B', 'age': 23}]
5.6 高阶函数
5.6.1 filter(函数名, 可迭代对象)
作用:过滤掉 可迭代对象 中不符合条件的元素,输出的是过滤后的结果。
注意:
1、filter 有两个参数,第1个参数可以是函数,也可以是None
当第1个参数是函数的时候,将第2个参数中每个元素进行计算。
当第1个参数是None的时候,直接将第2个参数中为True的值筛选出来。
示例:
#取出列表[1,2,3,4,5,6,7,8,9] 中的偶数
a = filter(lambda x:x%2 == 0, range(1,11))
print(list(a)) #[2, 4, 6, 8, 10]
print(a) #打印的是filter函数返回对象的地址 <filter object at 0x000001A7F57876D0>
#取出列表[1,2,3,4,5,6,7,8,9] 中的奇数,x%2为true,即不等于0
a = filter(lambda x:x%2 , range(1,11)) #[1,3,5,7,9]5.6.2 map(函数名, 可迭代对象)
作用:将可迭代对象的每一个元素作为函数的参数进行运算加工,直到可迭代序列每个元素都加工完毕。输出的是加工后的结果。
print(list(map(lambda x: x**2,range(1,5)))) #[1, 4, 9, 16]
5.6.3 functools.reduce(函数名,可迭代对象)
作用:函数中必需有2个参数,每次函数计算的结果继续和序列下一个元素做累积计算。输出结果是一个值。
示例:计算1+2+3+...+100 (之前我们可以用循环、迭代的方式实现,此时我们可以用functools模块中的reduce()函数实现最简洁。)
import functools
print(functools.reduce(lambda x,y:x+y, range(1,101))) #5050,















 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









