







目录
0x01 安装
0x02 简单认识docx库
Document对象
Paragraphs切片
输出内容
Run对象
表格
0x03 正则表达式
findall()
sub()
match()
search()
group()
常见语法及实例
0x04 读取Word中的文字、标题
输出标题
0x05 写入和插入word文字和段落
添加标题文字
添加段落
添加分页符
添加文字块
指定段落插入段落
0x06 插入与删除图片
在段落中插入图片
在表格中插入图片
0x07 表格的添加查看和定位
0x01 安装
pip install python-docx
0x02 简单认识docx库
from docx import Document
doc = Document('学习强国.docx')
print(doc.paragraphs)
Document对象
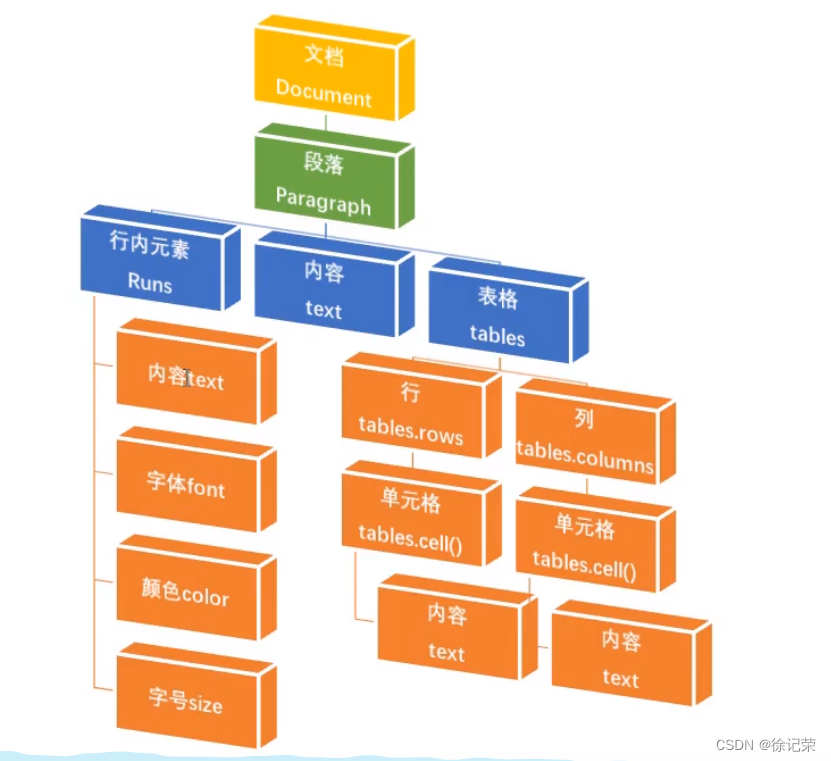
Document对象表示整个文档,
每一个文字段落代表一个Paragrapha对象(在输入文档,每一次回车产生新段落)
Run对象:一个Run对象所指的是Paragraph对象中相同样式的连续文字
运行结果为一个列表:
[<docx.text.paragraph.Paragraph object at 0x000001F6BCFE7790>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE7640>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE7850>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE76A0>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE78E0>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE7940>, <docx.text.paragraph.Paragraph object at 0x000001F6BCFE79A0>]
每段都被当成了一个Paragrapha对象
<docx.text.paragraph.Paragraph object at 0x000001F6BCFE7790>
Paragraphs切片
from docx import Document
doc = Document('学习强国.docx')
print(doc.paragraphs[0:2])
运行结果:
[<docx.text.paragraph.Paragraph object at 0x00000182E7AA77F0>, <docx.text.paragraph.Paragraph object at 0x00000182E7AA76A0>]
输出内容
from docx import Document
doc = Document('学习强国.docx')
for para in doc.paragraphs:
print(para.text)
运行结果:

Run对象

我们看第一段的文字,
连续格式一样的文字是一个Run对象
from docx import Document
doc = Document('学习强国.docx')
para = doc.paragraphs[0]
print(para.runs)
运行结果:
[<docx.text.run.Run object at 0x000001F625557910>, <docx.text.run.Run object at 0x000001F625557880>, <docx.text.run.Run object at 0x000001F625557970>, <docx.text.run.Run object at 0x000001F6255579D0>, <docx.text.run.Run object at 0x000001F625557A30>, <docx.text.run.Run object at 0x000001F625557BE0>, <docx.text.run.Run object at 0x000001F625557AC0>, <docx.text.run.Run object at 0x000001F625557CA0>, <docx.text.run.Run object at 0x000001F625557640>, <docx.text.run.Run object at 0x000001F625557B80>, <docx.text.run.Run object at 0x000001F625557D60>, <docx.text.run.Run object at 0x000001F625557C40>, <docx.text.run.Run object at 0x000001F625557E50>, <docx.text.run.Run object at 0x000001F625557D00>, <docx.text.run.Run object at 0x000001F625557EE0>, <docx.text.run.Run object at 0x000001F625557DC0>, <docx.text.run.Run object at 0x000001F625557FA0>, <docx.text.run.Run object at 0x000001F625557E80>]
表格

from docx import Document
doc = Document('学习强国.docx')
for table in doc.tables:
print(table)
运行结果:
<docx.table.Table object at 0x0000018E0BFDD3F0>
<docx.table.Table object at 0x0000018E0BFDD450>
Tbale对象跟Paragraphs对象类似
Paragraphs对象指的是文字段落
Table对象指的是一个单独的表格
如上,word文档中有两个表对象
一个表下面还有行和列
行是row
列是column
单元格是cell
逐行输出所有单元格的内容
from docx import Document
doc = Document('学习强国.docx')
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)

0x03 正则表达式
findall()
查找
findall(正则表达式,对象,匹配的模式)
sub()
替换
sub(被替换的字符,替换的字符,对象,替换次数(默认为0(无限次)))
match()
match从字符串的第一个字符开始匹配,如果未匹配到返回None,匹配到则返回一个对象,就是
仅匹配开始处
import re
a = '83C72D1D8E67'
r = re.match('\d',a)
print(r) # 返回对象所在位置
print(r.group()) # 返回找到的结果,例如8
print(r.span()) # 返回一个元组表示匹配位置(开始,结束)
运行结果:
<re.Match object; span=(0, 1), match='8'>
8
(0, 1)
search()
Search与match类似,search是搜索整个字符串然后将第一个匹配到的字符返回,未匹配到则返回None
import re
a = 'A83C72D1D8E67'
r = re.search('\d',a)
print(r)
print(r.group())
运行结果:
<re.Match object; span=(1, 2), match='8'>
8
group()
import re
a = "123abc456"
r = re.search("([0-9]*)([a-z]*)([0-9]*)",a)
print(r.group(0)) #123abc456,返回整体
print(r.group(1)) #123
print(r.group(2)) #abc
print(r.group(3)) #456
运行结果:
123abc456
123
abc
456
常见语法及实例
| 符号 | 释义 |
|---|---|
| [] | 匹配方括号内任意字符,中括号内每个字符是或(or)的关系 |
| [^] | 非,匹配除了方括号里的任意字符 |
| {n,m} | 匹配num个大括号之前的字符(n<=num<=m) |
| * | 匹配0次或无限次,重复在*号之前的字符 |
| + | 匹配1次或无限次,重复在+号之前的字符 |
| ? | 匹配0次或1次,重复在?号之前的字符 |
| ^ | 从字符串开始位置开始匹配 |
| $ | 从字符串末端开始匹配 |
| . | 句号匹配任意单个字符除了换行符 |
| 特殊字符 | 释义 |
|---|---|
| \d | 匹配数字,相当于[0-9] |
| \D | 不匹配数字,相当于[^0-9] |
| \w | 匹配中文,下划线,数字,英文,相当于[a-zA-Z0-9] |
| \W | 与\w相反,匹配特殊字符,如$、&、空格、\n、\t等 |
| \s | 匹配空白字符(包括空格、换行符、制表符等),相当于[\t\n\r\f\v] |
| \S | 与\s相反,相当于[^\t\n\r\v] |
| (xyz) | 字符集又称作组,匹配与xyz完全相等的字符串,每个字符是且(and)的关系 |
| 匹配模式 | 释义 |
|---|---|
| re.I | (IGNORECASE):忽略大小写 |
| re.M | (MULTILINE):多行模式,改变^和$的行为 |
| re.S | (DOTALL): 点任意匹配模式,改变.的行为 |
| re.L | (LOCALE):使预定字符类\w\W\b\B\s\S取决于当前区域设定 |
| re.U | (UNICODE):使预定义字符类\w\W\b\B\s\S\d\D取决于unicode定义的字符属性 |
| re.X | (VERBOSE):详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释 |
1️⃣提取字符串中的数字
import re
a = '孙悟空7猪八戒6沙和尚3唐僧6白龙马'
r = re.findall('[0-9]',a)
print(r)
运行结果:
['7', '6', '3', '6']
2️⃣提取字符串中的非数字
import re
a = '孙悟空7猪八戒6沙和尚3唐僧6白龙马'
r = re.findall('[^0-9]', a)
print(r)
运行结果:
['孙', '悟', '空', '猪', '八', '戒', '沙', '和', '尚', '唐', '僧', '白', '龙', '马']
^在[]内中时,代表的是非的意思
3️⃣字符串中,匹配符号中间字母的单词
import re
a = 'xyz,xcz,xfz,xdz,xaz,xez'
r = re.findall('x[de]z',a)
print(r)
运行结果:
['xdz', 'xez']
4️⃣匹配多个连续字符
import re
a = 'ExcelVBA 12345Word23456PPT12Lr'
r = re.findall('[a-zA-Z]{3,5}',a)
print(r)
运行结果:
['Excel', 'VBA', 'Word', 'PPT']
这里
{3,5}就是符合正则表达式,且连续三个字符以上,五个字符以下匹配
5️⃣模糊匹配(*,+,?)
*号前面的字符出现0次或无限次
import re
a = 'exce0excell3excelabc3'
r = re.findall('excel*',a)
print(r)
运行结果:
['exce', 'excell', 'excel']
注意这里模糊指的是
l这个字符出现0次或无限次,exce还是必须要有的
+号前面的字符至少出现1次
import re
a = 'exce0excell3excelabc3'
r = re.findall('excel*',a)
print(r)
运行结果:
['excell', 'excel']
?号匹配0次或1次
import re
a = 'exce0excell3excelabc3'
r = re.findall('excel?',a)
print(r)
运行结果:
['exce', 'excel', 'excel']
在这里插入代码片
6️⃣匹配位置(^,$)
import re
tel = '13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
运行结果:
['13811115888']
这里意思就是
开始结尾都是数字
且是8-11位
如果是这样,就匹配不上了
import re
tel = 'a13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
运行结果:
[]
开始或结尾任一处不满足正则要求就不匹配
7️⃣组()
import re
a = 'abcabcabcxyzabcabcxyzabc'
r = re.findall('(abc){2}',a)
print(r)
运行结果:
['abc', 'abc']
这里就是连续为两个
abc,也就是abcabc才会输出
8️⃣忽略大小写的匹配模式
import re
a = 'abcFBIabcCIAabc'
r = re.findall('fbi',a,re.I)
print(r)
运行结果:
['FBI']
9️⃣多模式匹配
import re
a = 'abcFBI\nabcCIAabc'
r = re.findall('fbi.{1}',a,re.I|re.S)
print(r)
运行结果:
['FBI\n']
.默认是不匹配\n的,但使用re.S之后,匹配字符包括换行符
1️⃣0️⃣替换字符
import re
a = 'abcFBIabcCIAFBIabc'
r = re.sub('FBI','BBQ',a,1)
print(r)
运行结果:
abcBBQabcCIAFBIabc
将
FBI替换为BBQ,且替换一次
0x04 读取Word中的文字、标题
输出标题
from docx import Document
doc = Document('学习强国.docx')
for para in doc.paragraphs:
if para.style.name == 'Heading 1':
print(para.text)

0x05 写入和插入word文字和段落
1️⃣添加标题文字
from docx import Document
doc = Document('练习3.docx')
doc.add_heading('sdsdsdsd',level=1)
doc.save('练习4.docx')
运行结果:

2️⃣添加段落
from docx import Document
doc = Document('练习3.docx')
doc.add_paragraph('112233445566')
doc.save('练习4.docx')
运行结果:

3️⃣添加分页符
from docx import Document
doc = Document('练习3.docx')
doc.add_page_break()
doc.add_paragraph('112233445566')
doc.save('练习4.docx')

4️⃣添加文字块
from docx import Document
doc = Document('练习3.docx')
a = doc.add_paragraph('我是正文在我后面添加的文字会被设置格式:')
a.add_run('加粗').bold = True
a.add_run('普通')
a.add_run('斜体').italic = True
doc.save('练习4.docx')
运行结果:

5️⃣指定段落插入段落
原文档:

from docx import Document
doc = Document('练习9.docx')
para = doc.paragraphs[1] # 获取第二个段落
para.insert_paragraph_before('这是添加的新的第二个段落') # 在第二个段落处插入
doc.save('5.docx')
运行结果:

0x06 插入与删除图片
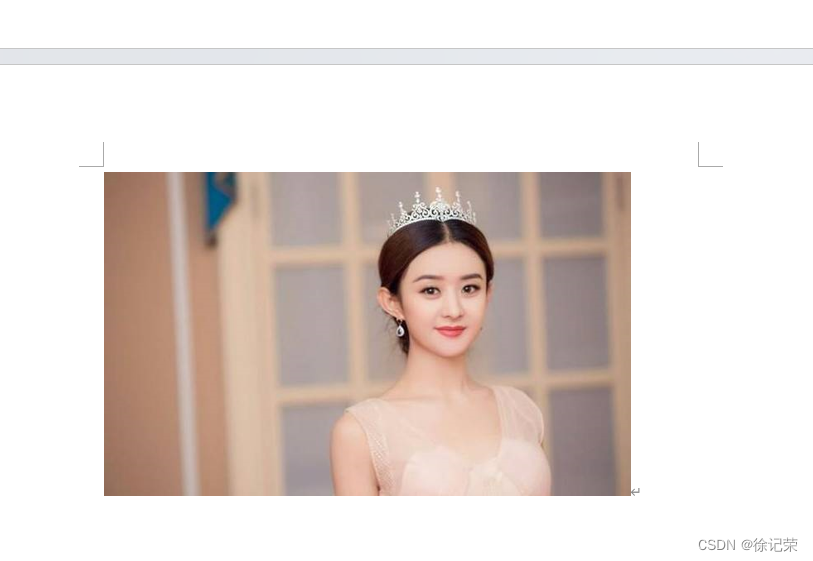
1️⃣在段落中插入图片
from docx.shared import Cm
from docx import Document
doc = Document('练习4.docx')
doc.add_picture('赵丽颖.jpg', width = Cm(13), height = Cm(8)) # Cm是厘米
doc.save('5.docx')
运行结果:
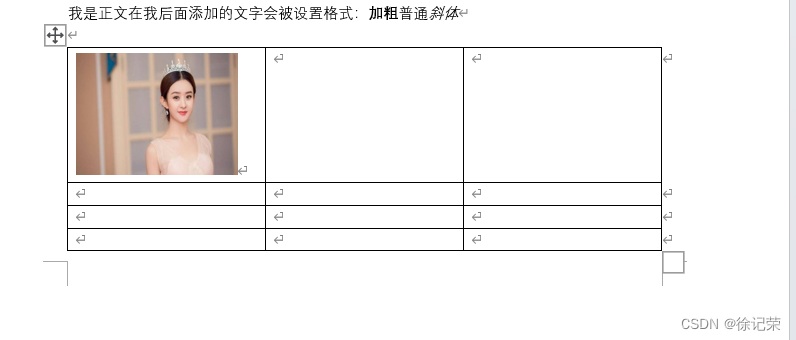
2️⃣在表格中插入图片
from docx.shared import Cm
from docx import Document
doc = Document('练习4.docx')
run = `在这里插入代码片`doc.tables[0].cell(0,0).paragraphs[0].add_run()
run.add_picture('赵丽颖.jpg', width = Cm(4), height = Cm(3)) # Cm是厘米
doc.save('5.docx')
运行结果:
0x07 表格的添加查看和定位















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









