







前言
Natural Earth 数据集是一个公共领域的地图数据集,提供全球范围内的自然地理和文化地理数据。它以1:10m、1:50m和1:110m的比例尺提供矢量(SHP)和栅格(TIF+TFW)数据。这个数据集旨在为制图人员提供出版所需小比例尺地图的数据支持,解决在大量混乱、属性不明的数据中寻找适合制作小比例尺地图的数据的问题。
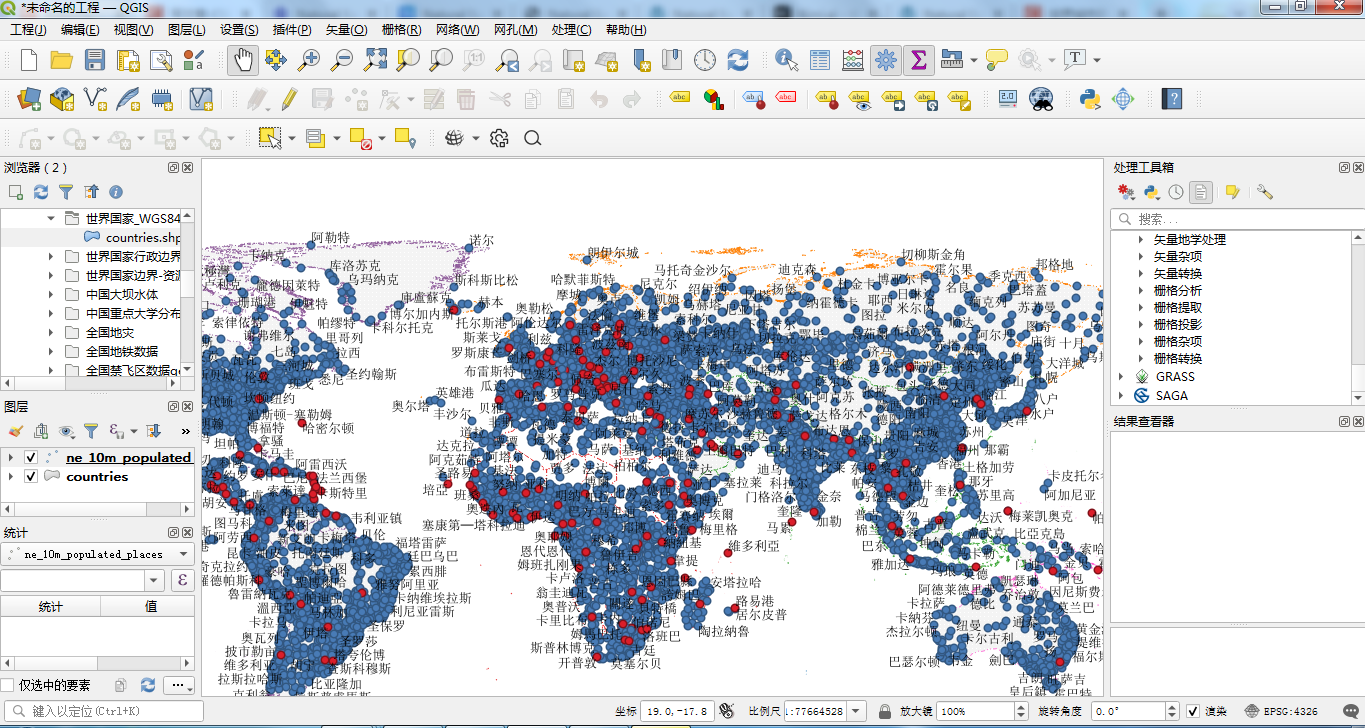
整体效果图
ne_10m_populated_places.shp 是 Natural Earth 数据集中的一个矢量数据文件,包含了全球范围内人口大于或等于1万的城市和市镇的位置和相关信息。这个数据集的特点包括:
-
点符号与名称属性:数据集包含所有行政0级(国家首都)和许多行政1级(省会或州首府)的首都,主要城市和城镇,以及在人口稀少地区抽样的小城镇。在选择地点时,更倾向于地区重要性而非人口普查数据。
-
人口估计:大约90%的城市提供了基于LandScan的人口估计。LandScan数据集由橡树岭国家实验室维护和分发,这些数据从栅格转换为矢量,并去除了每平方公里少于200人的像素,因为它们被分类为农村地区。
-
人口值范围:提供了一系列人口值,这些值考虑了总的“大都市区”人口而非行政边界内的人口。从版本1.1开始,对于世界上约500个人口最大的城市,popMax(最大人口数)被限制为联合国估计的大都市区人口,这影响了中国、印度和非洲部分地区的城市,因为Landscan计数方法通常会高估这些地区的人口。
-
人口排名:使用一个通用的VB公式计算最大和最小人口排名(rank_max 和 rank_min),这个公式可以在ArcMap Field Calculator中使用。
-
多语言支持:数据集包含了不同语言的城市名称,方便全球用户使用。
-
详细信息:除了基本的名称、国家、行政区域、经纬度和海拔高度信息外,还包括人口密度、市中心点、城市类型(如首都、省会、县治等)等详细信息。所有数据都是从官方数据源(如国家统计局、联合国等)收集和整理而来。
-
数据规模:ne_10m_populated_places数据集包含了全球超过7000余个人口大于或等于1万的城市和市镇。
Natural Earth 数据集以其精确对齐的数据层、精心概括的线条和重要的GIS属性而闻名,这些属性对于快速地图制作非常有用,如河流段的宽度属性用于创建渐变效果。
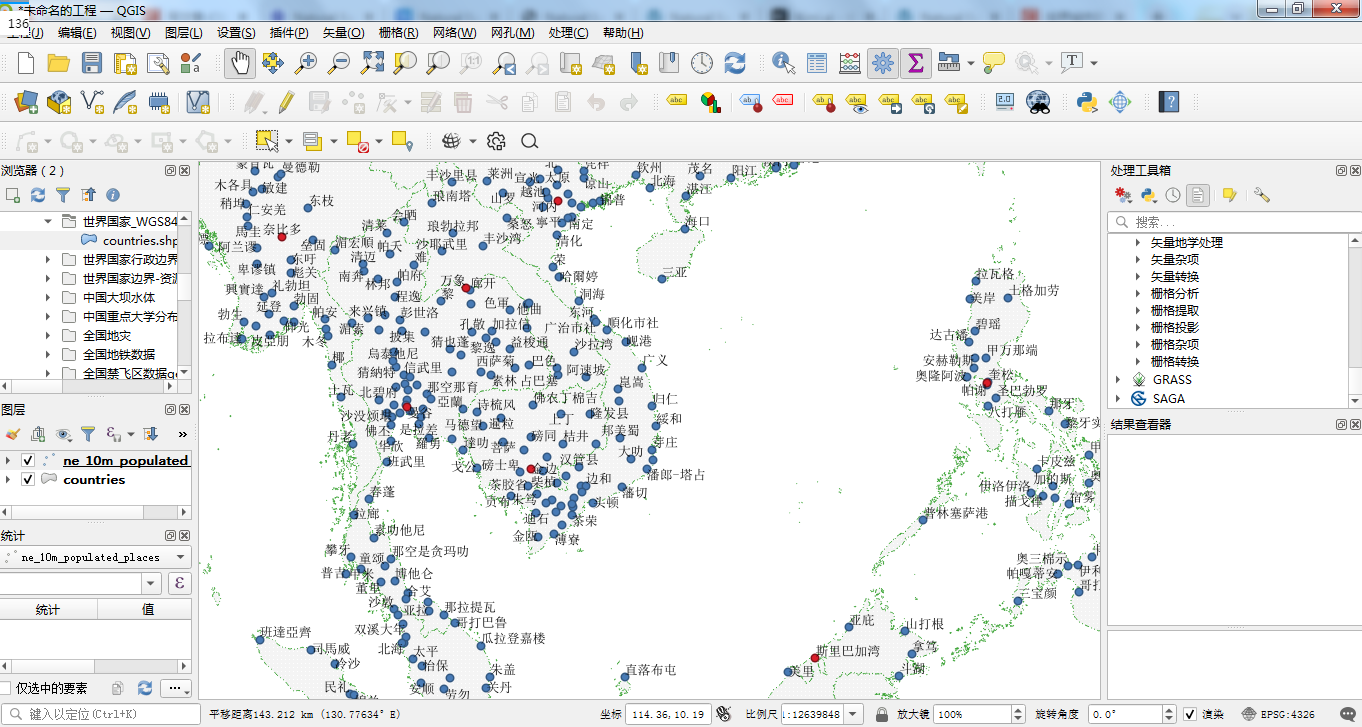
南亚城市信息局部信息图
ne_10m_populated_places.shp 文件作为其中的一部分,为全球城市和市镇的地理信息系统(GIS)应用和分析提供了宝贵的数据资。这是一份包含全球的重要城市的空间矢量数据。在国内有我们有很详细的城市信息以及空间坐标,但是在国外,尤其是一些不太发达的国家而言。这是一份难得的空间数据。
本文即重点介绍这份全球的重要城市信息,在这里我们采用Qgis软件进行矢量数据的读取和分析,对这份数据的相关参数、空间参考、属性表格以及具体的属性字段进行深入结合,最后结合Qgis的空间制图来看一下全球的城市分布规模。为下一步进行全球城市的分析奠定空间基础。
一、数据集的来源
首先我们需要对涉及的数据集进行简单的介绍,让大家知道这份数据源可以到哪里去下载,如果想要最近的数据和想过的说明,可以从什么渠道进行获取等等。
1、官网网站
数据是从Natural Earth网站中进行查询和下载的,可以通过其官网上提供的连接跳转到下载界面,也可以从github的官方仓库中获取相应的数据。Natural Earth 网站。在浏览器搜索相应的网站名称也可以点击进入其官网网站。
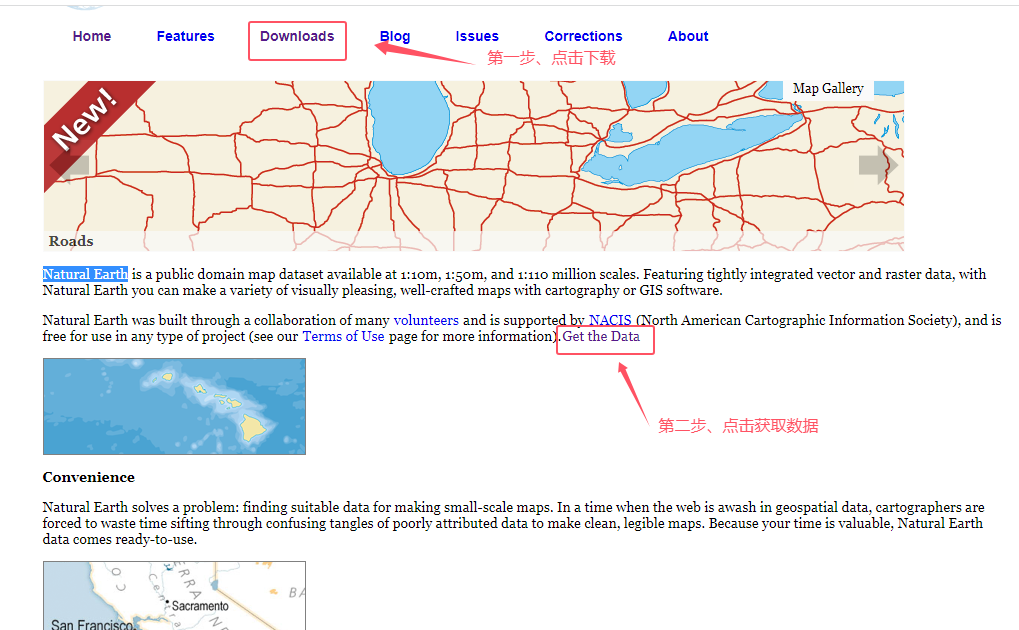
想要获取数据的话,点击页面的导航downloads,然后点击页面中的Get the Data超链接,具体操作如下图所示:
点击过后进入到以下的信息界面中,可以看到共享数据的下载界面,当然还有其他的数据也是一起放在这个页面上的。

然后根据不同的数据精度,比如1:10米的大比例尺,1:50米的中比例尺还有1:110米的小比例尺的数据,请根据实际的工作需要,选择不同的按钮来进行下载相应的数据,如下图所示:

2、数据压缩包
我们可以下载完整的数据包,整体的大小大概是560MB,这里我已经将矢量下载好,在本地的磁盘服务器中可以看到如下的文件。如下图所示:
在这里我们将10m_cultural的文件从压缩包中解压出来,10m_cultural中就包含我们今天需要的讲解的数据包。 在本地磁盘中打开后可以看到有许多的文件。
这里的文件很多,这里不进行一一叙述,先对我们的重点目标对象进行介绍,让大家对其有一定的了解。它就是我们的主角-ne_10m_populated_places.shp。下面我们就使用QGIS软件对ne_10m_populated_places.shp进行一个简单的介绍和讲解。
二、深入介绍目标数据集
在前面的内容中,我们简单介绍哪里可以找到这个数据集,同时介绍了如何在官方网站上如何下载这个数据集,对下载后的数据集也有一个简单的说明。先让大家有一个简单的基本认识。本节来对ne_10m_populated_places.shp进行一个较深入的介绍。
1、空间参考和要素信息
既然是作为空间矢量数据,那么我们重点的关注就是空间参考和要素信息。比如这份数据采用什么坐标系统,一共有多少条要素等等。在这里,我们首先使用熟悉的Qgis软件来对这份数据进行一个简单的学习。
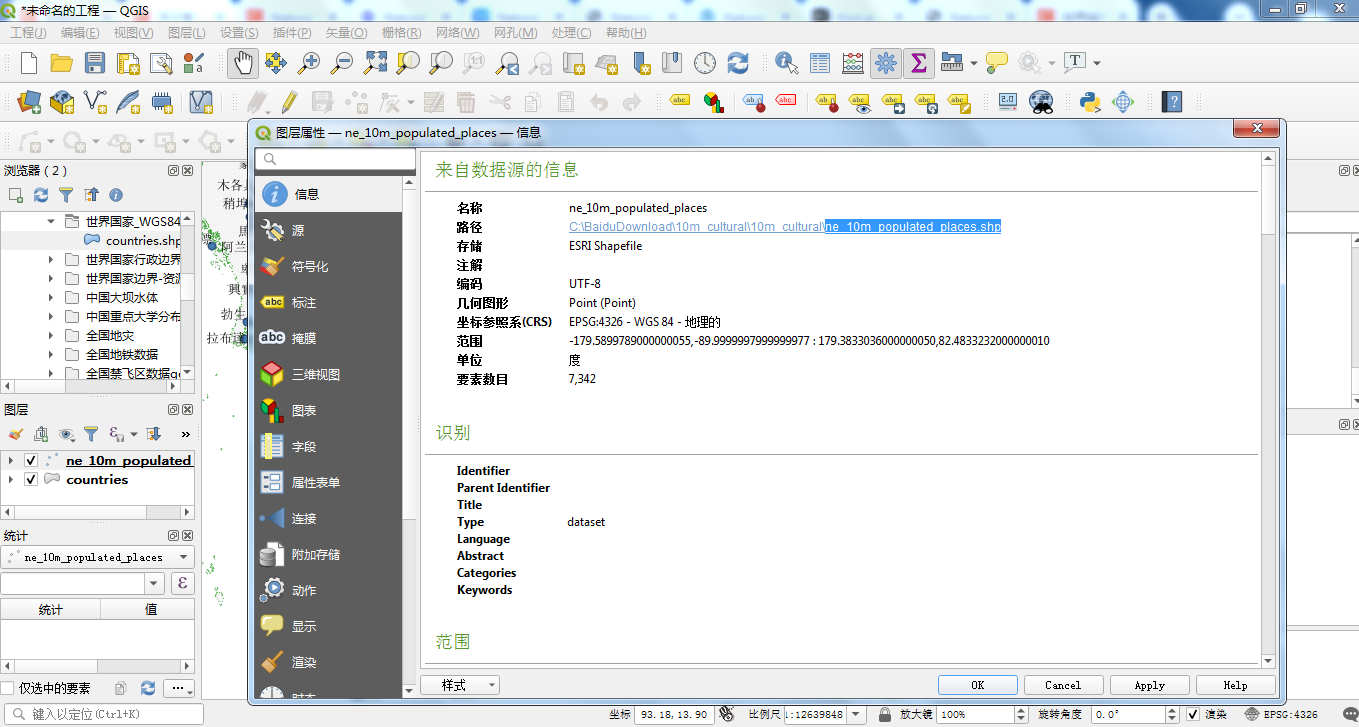
通过上面这张图,基本我们可以得到以下的信息表格:
| 序号 | 参数 | 说明 |
| 1 | 编码 | UTF-8 |
| 2 | 空间对象类型 | Point (Point) |
| 3 | 坐标参照系(CRS) | EPSG:4326 - WGS 84 - 地理的 |
| 4 | 空间范围 | -179.5899789000000055,-89.9999997999999977 : 179.3833036000000050,82.48332320000000 |
| 5 | 要素的数目 | 7342 |
2、空间字段说明
在矢量数据中,除了最重要的空间范围属性,属性信息也是非常重要的信息。因此在介绍空间参考等信息后,我们来对空间的属性字段来进行一个简单的说明。 依然在Qgis当中,直接打开属性信息表。可以看到以下的信息:
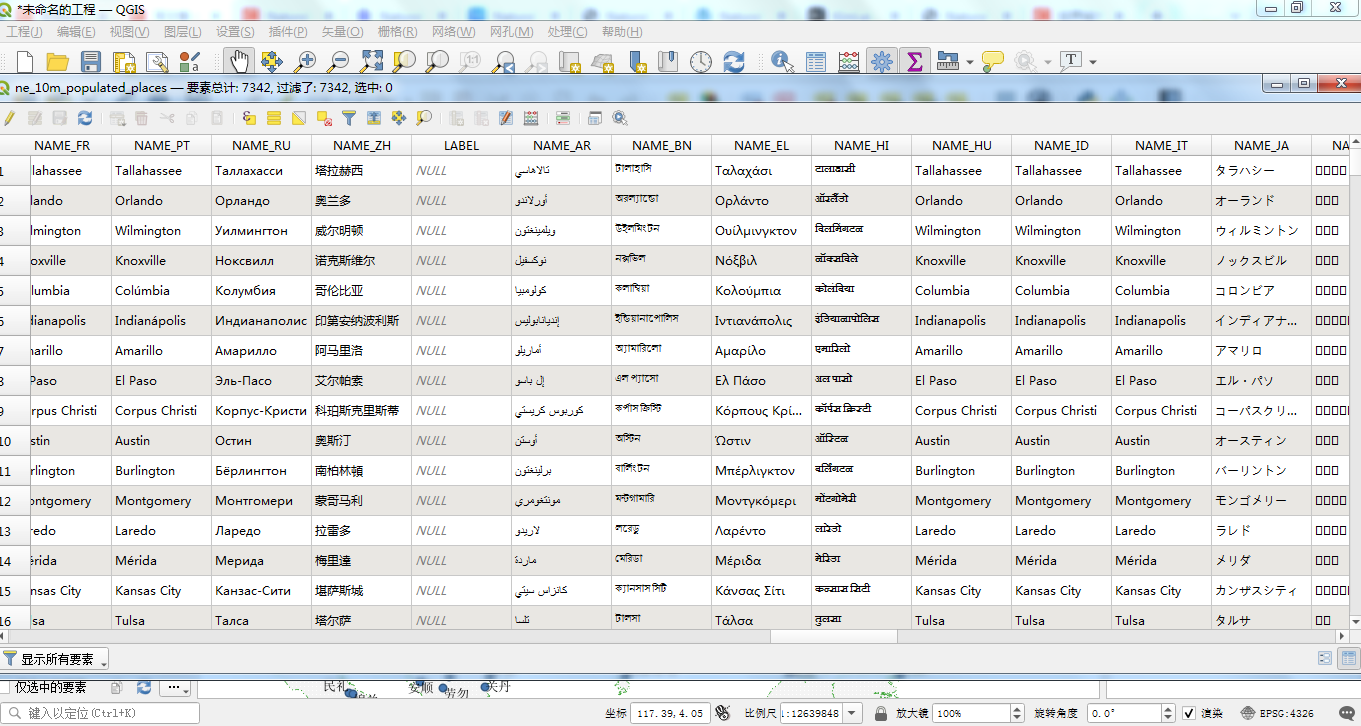
这是具体的属性表格信息,可以看到这个属性信息表有很多关于城市名称的多语言支持,这是非常好的,避免了我们自己去翻译,同事很多其它国家的文字表示,不是所擅长的。这里数据集都十分完善的直接提供了,这样为城市分析实现全球化的支撑提供了良好的基础。打开属性表格,可以看到如下的信息:
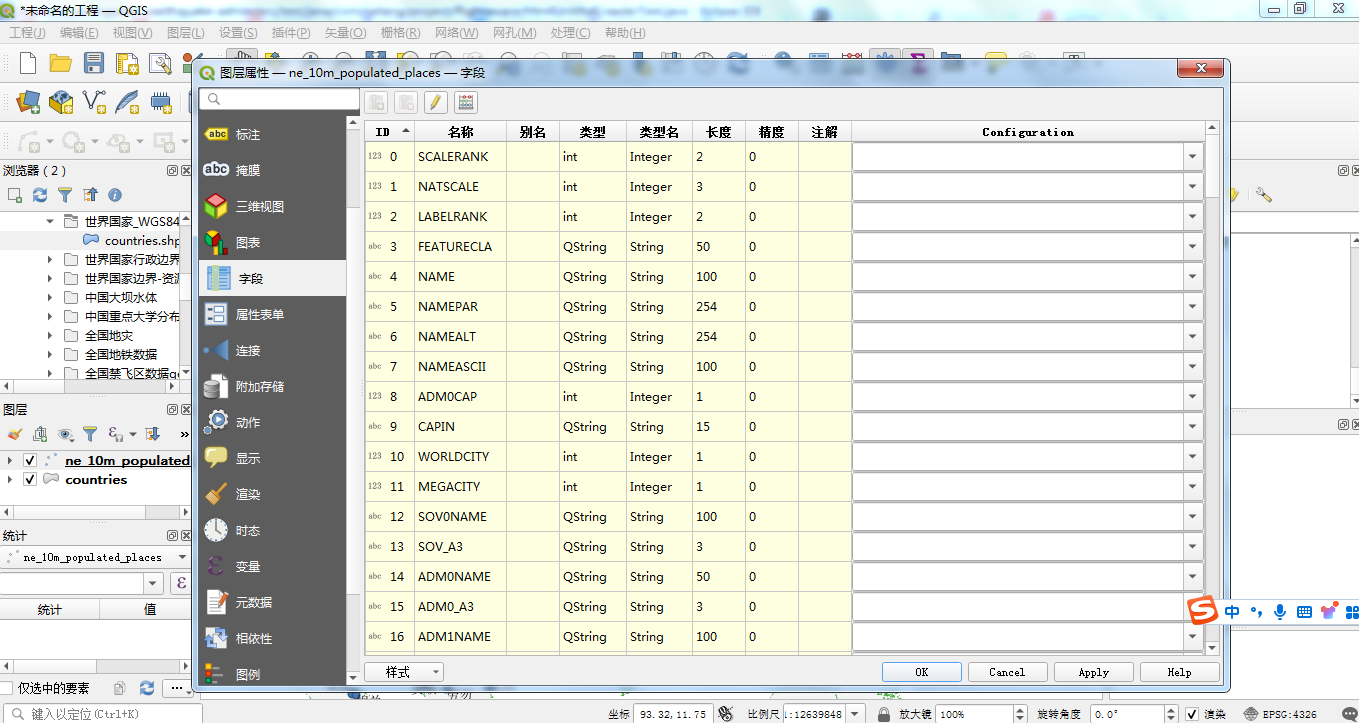
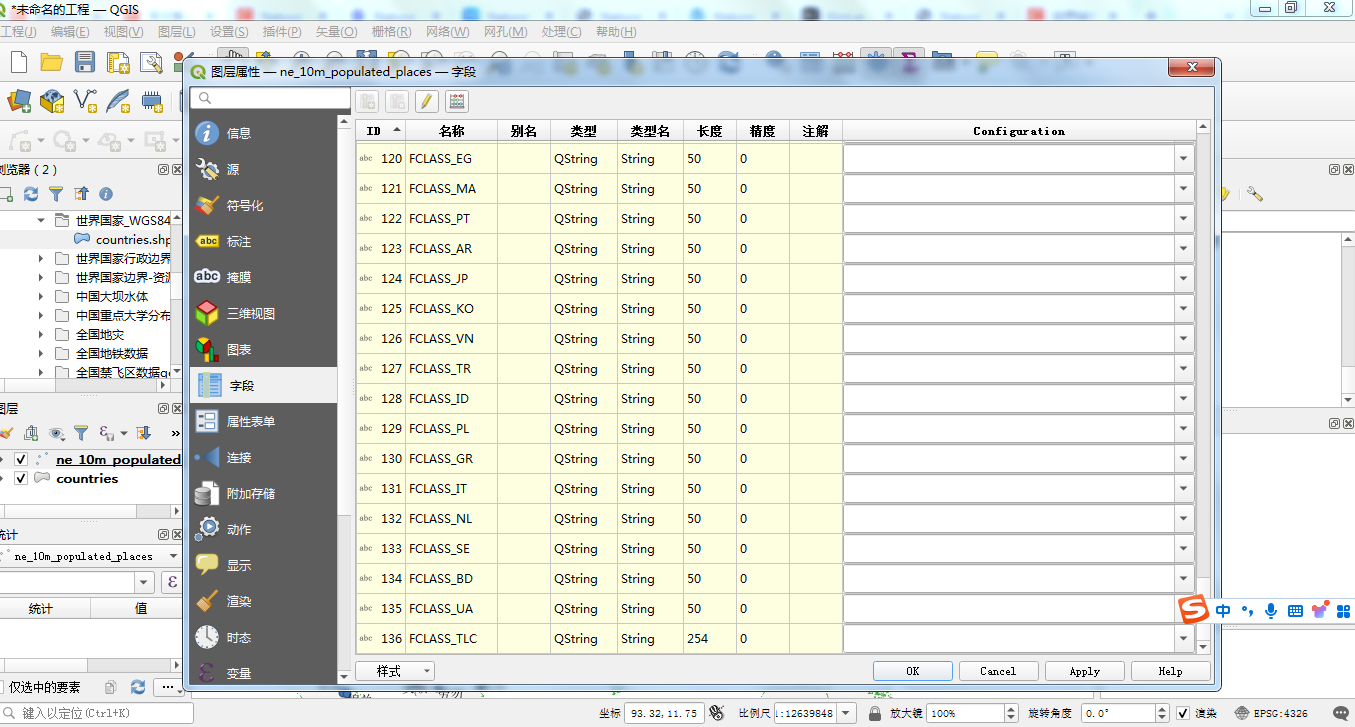
ne_10m_populated_places.shp 这份数据的属性列非常多,后面会具体的进行介绍,截图就不全部截图出来了。这张表的所有属性字段的长度有137个之多。里面有许多历年的人口信息。大家可以在拿到数据后在进行数据入库时进行属性表的分拆,有的信息没有必要都存放到一张表中。
3、属性表格的中文属性
虽然属性表格的字段有137列,但是其列名都是英文的,对于习惯中文的朋友不是很友好。因此这里我们对这些英文的属性名称进行中文翻译,为了节约大家的时间,这里把内容分享出来,工大家在需要时参考:
the_geom:几何字段,表示地点的地理位置。
SCALERANK:比例尺等级,表示该地点在地图上显示的优先级。
NATSCALE:自然地图比例尺,表示该地点在自然地图上的比例尺级别。
LABELRANK:标签等级,表示该地点在地图上标注的优先级。
FEATURECLA:特征类别,这里为“Populated place”,即人口聚居地。
NAME:地点的标准名称。
NAMEPAR:父级名称。
NAMEALT:替代名称。
NAMEASCII:地点名称的ASCII编码形式。
ADM0CAP:是否为国家首都。
CAPIN:首都类型。
WORLDCITY:是否为世界城市。
MEGACITY:是否为特大城市。
SOV0NAME:国家名称。
SOV_A3:国家代码。
ADM0NAME:国家名称。
ADM0_A3:国家代码。
ADM1NAME:一级行政区名称。
ISO_A2:国家ISO代码。
NOTE:备注。
LATITUDE:纬度。
LONGITUDE:经度。
POP_MAX:最大人口数。
POP_MIN:最小人口数。
POP_OTHER:其他人口数。
RANK_MAX:最大人口排名。
RANK_MIN:最小人口排名。
MEGANAME:特大城市名称。
LS_NAME:地点名称。
MAX_POP10:2010年最大人口数。
MAX_POP20:2020年最大人口数。
MAX_POP50:最大人口数(50万以上)。
MAX_POP300:最大人口数(300万以上)。
MAX_POP310:最大人口数(3100万以上)。
MAX_NATSCA:最大自然地图比例尺。
MIN_AREAKM:最小面积(平方公里)。
MAX_AREAKM:最大面积(平方公里)。
MIN_AREAMI:最小面积(平方英里)。
MAX_AREAMI:最大面积(平方英里)。
MIN_PERKM:最小周长(公里)。
MAX_PERKM:最大周长(公里)。
MIN_PERMI:最小周长(英里)。
MAX_PERMI:最大周长(英里)。
MIN_BBXMIN:最小边界框的最小经度。
MAX_BBXMIN:最大边界框的最小经度。
MIN_BBXMAX:最小边界框的最大经度。
MAX_BBXMAX:最大边界框的最大经度。
MIN_BBYMIN:最小边界框的最小纬度。
MAX_BBYMIN:最大边界框的最小纬度。
MIN_BBYMAX:最小边界框的最大纬度。
MAX_BBYMAX:最大边界框的最大纬度。
MEAN_BBXC:平均边界框的经度。
MEAN_BBYC:平均边界框的纬度。
TIMEZONE:时区。
UN_FID:联合国FID。
POP1950 至 POP2050:从1950年到2050年的人口预测。
MIN_ZOOM:最小缩放级别。
WIKIDATAID:Wikidata ID。
CAPALT:替代首都。
NAME_EN 至 NAME_SE:不同语言的名称。
NE_ID:Natural Earth ID。
NAME_FA 至 NAME_ZHT:更多不同语言的名称。
GEONAMESID:GeoNames ID。
FCLASS_ISO 至 FCLASS_SE:不同国家/地区分类标准
以上是本小节的主要内容,主要围绕数据的空间参考等基本信息、空间属性数据实例以及属性列中文解析对数据进行简单的说明。
三、不同语言下的标注展示
在这份详细的数据包中,围绕城市的名称,使用了不同的国家语言来进行标注,因此我们来看一下不同的国家在不同的语言标注是什么效果。
1、中文模式标注
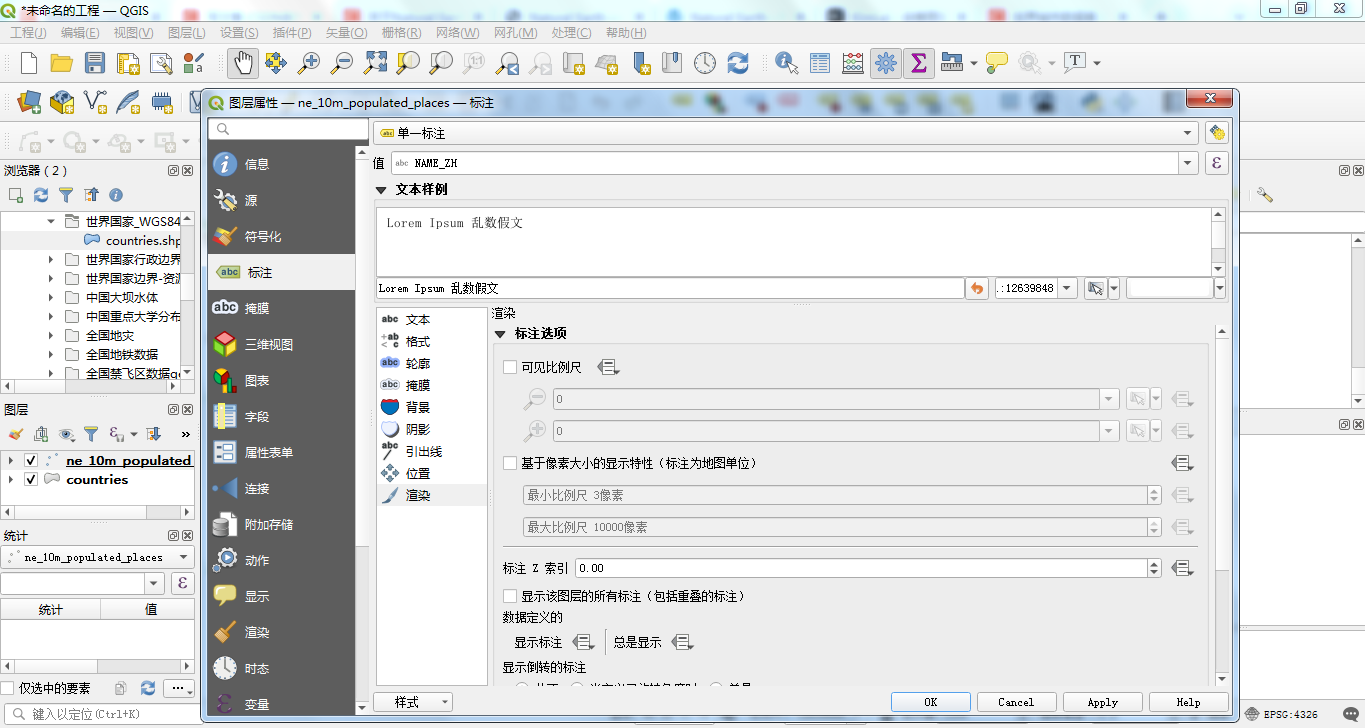
如何在Qgis中进行标注,相信大家都不陌生,这里我们不对Qgis这款软件的操作来进行详细说明,仅说明如何进行标注。点击图层属性,然后点击标注,选择标注的字段为NAME_ZH:
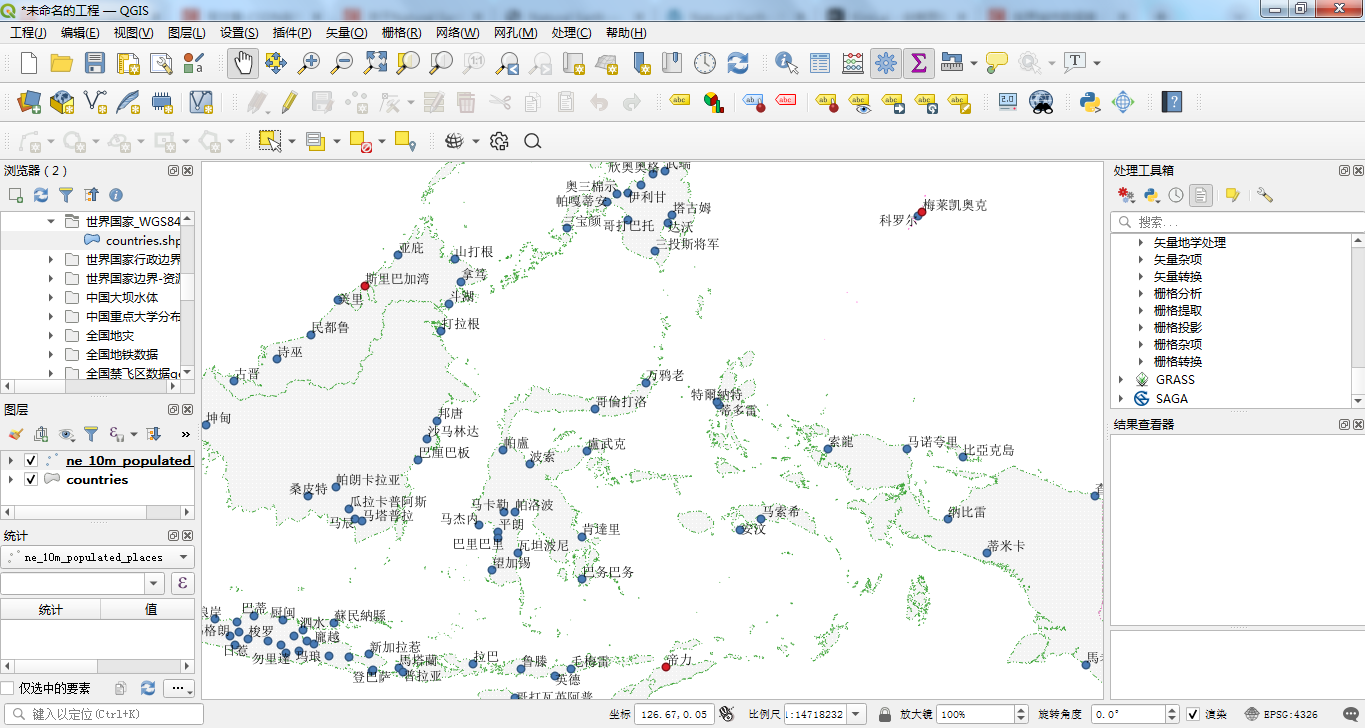
此时我们来看在Qgis界面中,城市信息列表是否按照预定的进行展示。
2、英文的展示
接下来,我们将标注切换成英文,属性字段为:NAME_EN,使用鼠标点应用后,可以看到以下效果:
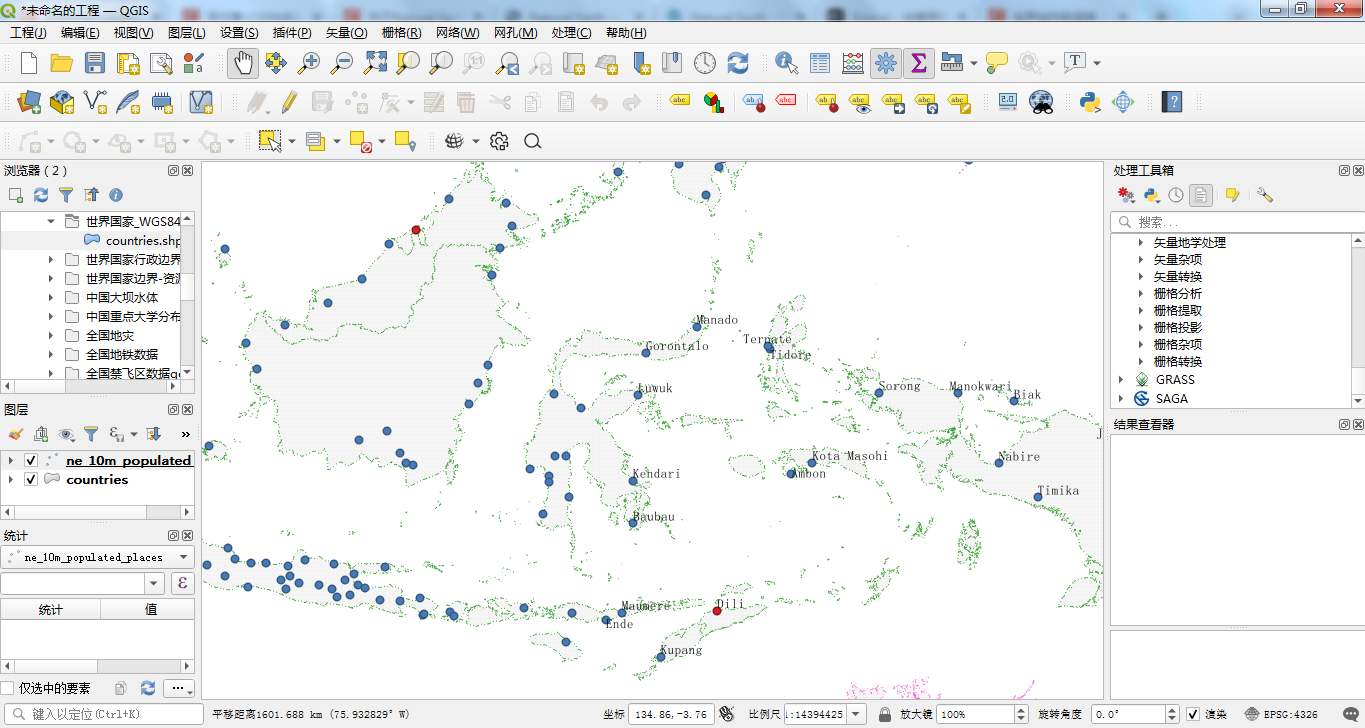
可以发现,之前的中文标注就全部切换到了英文。
3、阿拉伯文标注
按照同样的方法切换到使用阿拉伯文来进行标注,效果如下所示:
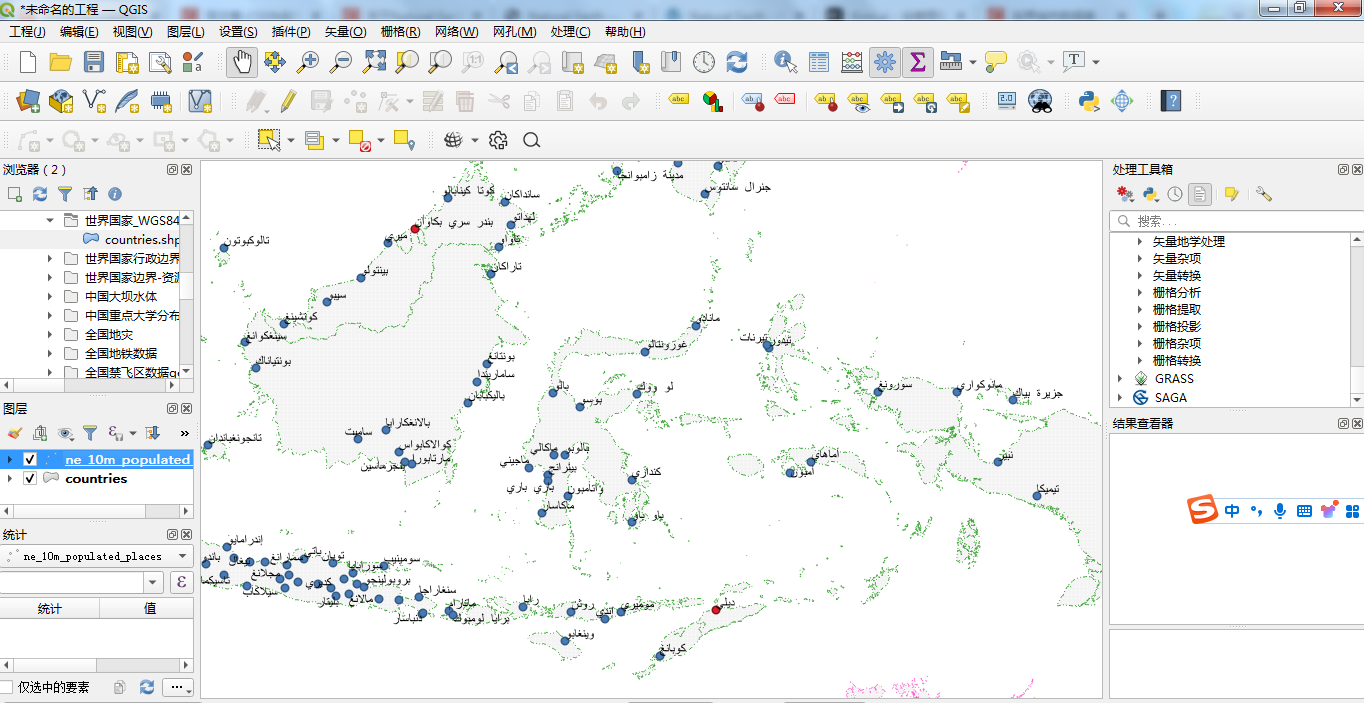
请注意,上面不是遇到了错误,而是使用了我们不熟悉的文字。
4、Qgis聚类展示标注
众所周知,除了使用Leaflet来进行空间数据的聚类,我们还可以在Qgis当中使用聚类来进行数据的展示。在标注是,符号化选择聚类的模式。如下图所示:
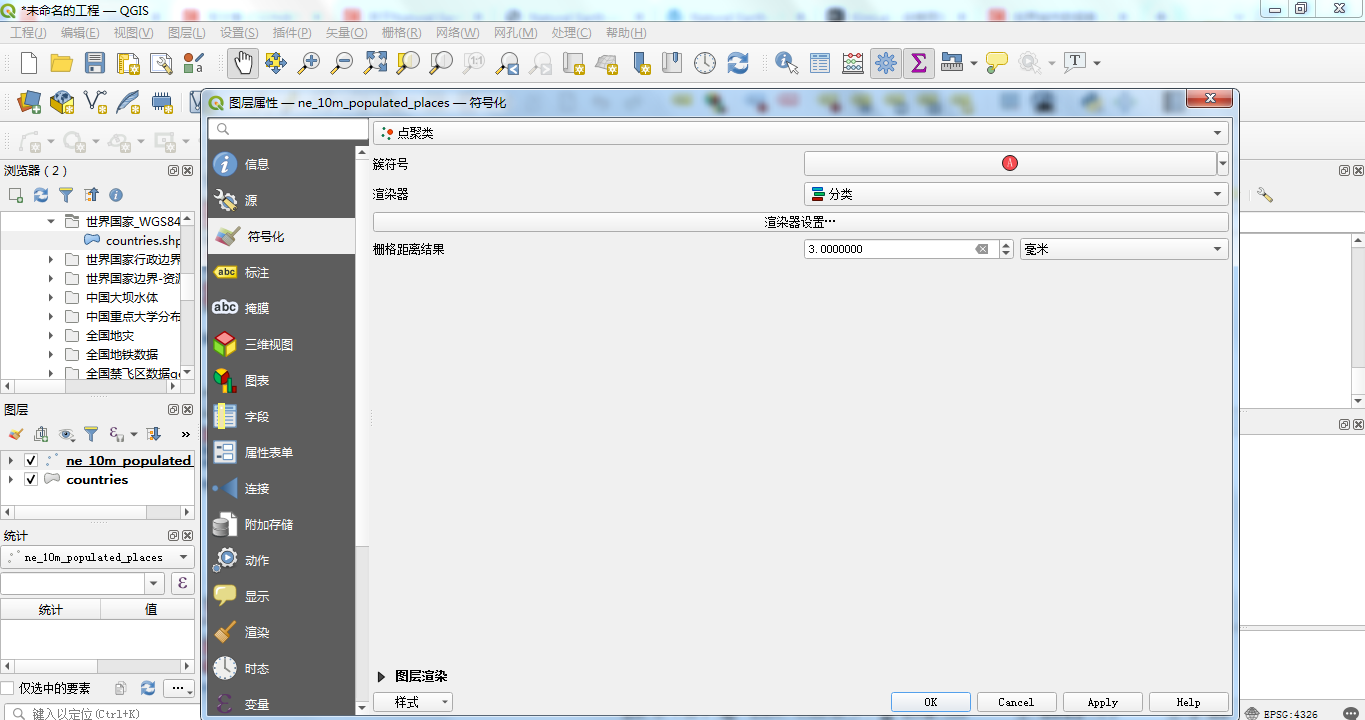
设置好相应的标注参数后,点击应用,在QGIS中来看一下实际的效果。

这样也是在Qgis中实现了点的聚类展示。
四、总结
以上就是本文的主要内容, 本文即重点介绍这份全球的重要城市信息,在这里我们采用Qgis软件进行矢量数据的读取和分析,对这份数据的相关参数、空间参考、属性表格以及具体的属性字段进行深入结合,最后结合Qgis的空间制图来看一下全球的城市分布规模。为下一步进行全球城市的分析奠定空间基础。
Natural Earth 数据集中的 ne_10m_populated_places.shp 文件非常适合用于城市规划和人口研究。该数据集提供了全球超过7000余个人口大于或等于1万的城市和市镇的位置信息,这对于城市规划者来说是基础且重要的信息,可以帮助他们了解城市分布和扩张的潜力。这些数据可以帮助规划者评估不同区域的人口密度和分布,从而进行更合理的城市规划。通过 PopMax 列,规划者可以根据人口规模来设计城市基础设施和服务。
数据集包含了不同语言的城市名称,方便全球用户使用,这对于跨国城市规划尤为重要。大约90%的城市提供了基于LandScan的人口估计,这些数据可以帮助研究者了解全球人口分布和变化趋势。数据集提供了最大和最小人口排名(rank_max 和 rank_min),这对于分析城市人口的重要性和规模非常有用。数据集包含了每个城市的人口密度信息,这对于研究城市化对环境和社会的影响至关重要。虽然数据集不包含历史人口数据,但可以与其他数据源结合,研究人口随时间的变化。总之,这些数据可以帮助规划者和研究者更好地理解城市发展模式、人口分布和城市化的影响。行文仓促,定有许多不足之处,如有不足,还请各位专家在评论区批评指正,不胜感激。


















 4046
4046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











