







 本文详细指导如何在满足Linux、Nvidia驱动和docker环境的基础上,使用LLaMA-Factory项目进行语言模型微调,涉及Dockerfile和docker-compose文件的本地化适配,以及模型部署、配置和使用过程。
本文详细指导如何在满足Linux、Nvidia驱动和docker环境的基础上,使用LLaMA-Factory项目进行语言模型微调,涉及Dockerfile和docker-compose文件的本地化适配,以及模型部署、配置和使用过程。
在根据本篇文章实践以前,请确保你满足了以下基础条件,如果你没有满足,请自行解决,本篇文章教的是如何搭建语言模型的微调平台,不教如何安装Linux 显卡驱动以及docker
本教程使用的是著名的开源项目“LLaMA-Factory”
基础环境
1.Linux 系统,Nvidia驱动
2.docker环境
3.显卡显存最少24G,本地运行内存最少64G
安装项目
从github上下载项目,运行如下命令
git clone https://github.com/hiyouga/LLaMA-Factory下载完成后,进入项目,直接使用项目中的docker compose文件进行部署。但是由于在国内环境,所以需要对docker部署文件进行一些修改。需要修改的是Docker file 以及docker-compose 文件
关于项目中的docker部署文件内容不清楚的,可以借助这个GLM4智能体来理解Docker文件字段的含义,这个智能体也是作者自己做的,内部包含有大量的Dockerfile样例以及官方的文档作为基础知识库,精确度高,请放心使用
项目部署文件本地化适配
修改Dockerfile文件的内容如下,主要是修改了python源的地址,改成了清华的地址。
Dockerfile文件 的修改内容
FROM nvcr.io/nvidia/pytorch:24.01-py3
WORKDIR /app
COPY requirements.txt /app/
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
COPY . /app/
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .[deepspeed,metrics,bitsandbytes,qwen]
VOLUME [ "/app/hf_model", "/app/data", "/app/output" ]
EXPOSE 7860
CMD [ "python", "src/train_web.py" ]"/app/hf_model" 是模型存放的路径
"/app/data" 数据集存放的路径
"/app/output" 微调模型后文件存放的路径
以上这些路径都是在容器中创建,用来存放宿主机映射数据文件的。
docker-compose.yml文件的修改内容
services:
llama-factory:
build:
dockerfile: Dockerfile
context: .
container_name: llama_factory
volumes:
- ./hf_cache:/app/hf_model
- ./data:/app/data
- ./output:/app/output
- /etc/localtime:/etc/localtime
environment:
- CUDA_VISIBLE_DEVICES=0
ports:
- "7860:7860"
ipc: host
deploy:
resources:
reservations:
devices:
- driver: nvidia
#count: "all"
device_ids: ['0']
capabilities: [gpu]
restart: unless-stopped
device_ids: ['0'] 当服务器有多张显卡以后,需要修改成该字段,该字段的意思是映射第0号显卡进入容器中,当然如果你有其他显卡,这个数字可以是1,也可以是2
- ./hf_cache:/app/hf_model 把宿主机的模型文件目录映射到容器中
配置完成以上内容后,就可以运行容器了,在项目根目录中运行命令,然后等待容器自动部署完成即可。
运行时,注意检查7860端口是否被占用。如果占用,请更改容器的映射端口。
docker compose up -d部署完成后,需要从HF或者魔搭上下载模型文件,然后再上传到宿主机中hf_cache,
模型文件地址如下:
https://huggingface.co/THUDM/chatglm3-6b
模型下载完成后,模型文件目录内容如下

平台配置
现在我们开始登录页面 ,页面地址:http://你的服务器IP:7860,登录成功后,我们理论上就可以开始微调模型了,但是在微调模型之前,我们还需要对平台进行一些配置
模型路径,要填写模型文件夹所在的绝对路径(容器中的路径),否则是无法加载模型的
为什么要这么配置呢?因为国内没办法使用hugingface,所以你得自己想办法下载,项目里的默认路径就没办法用了,下载完成后手动上传到服务器,需要手动上传到服务器,所以模型路径就只能填写容器内的绝对路径了(填写内容根据自己的实际情况填写,不用抄我的)

然后选择数据集

然后配置学习率(这里基本上使用默认配置即可)

平台初体验
配置完成后,我们就可以体验一下微调大语言模型了
点击开始学习,正常运行后,就会出现以下结果
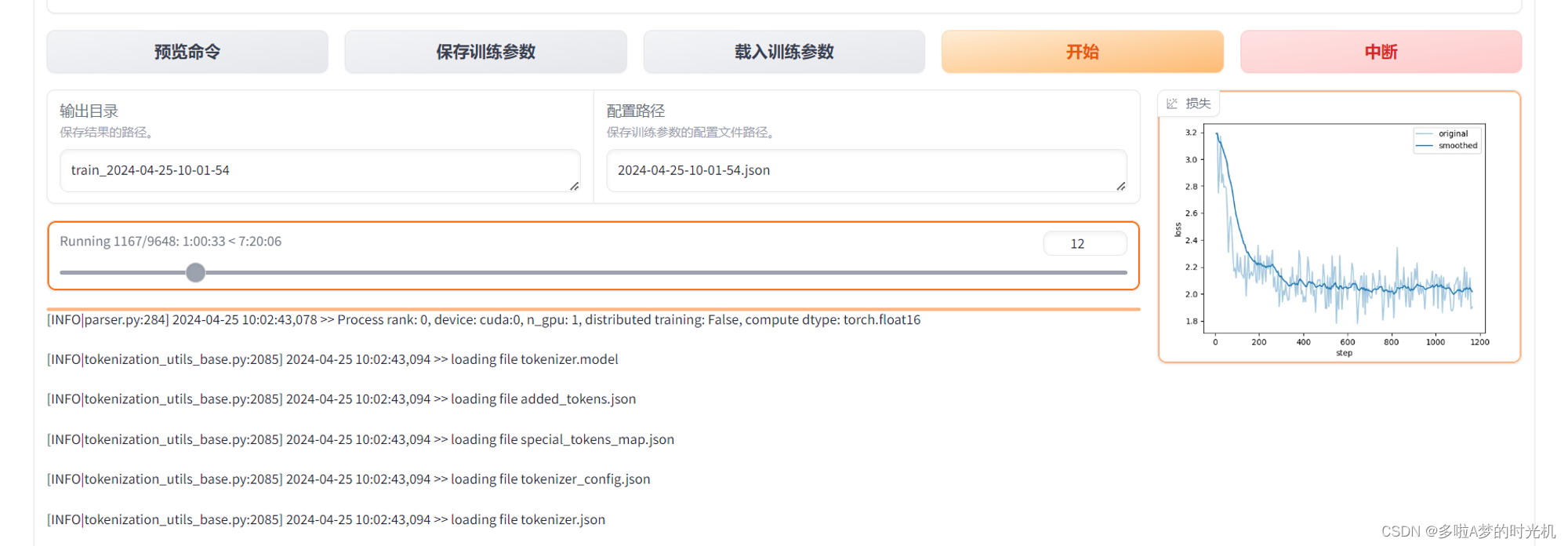
学习完成后输出的模型文件在“/app/saves/ChatGLM3-6B-Chat/lora”中,这个目录并不是在文档中所说的Output文件夹中,这点需要注意。
使用后训练后的模型
推理引擎一定使用huggingface,这个容器内vllm无法安装,然后点击加载模型,等待模型加载完成即可使用微调后的模型了

加载模型成功时,后台会显示如下信息

微调后模型如何输出,导出目录直接填写output,然后点击导出,这样模型就导出到了项目目录下的output路径中,该路径是映射到宿主机的。
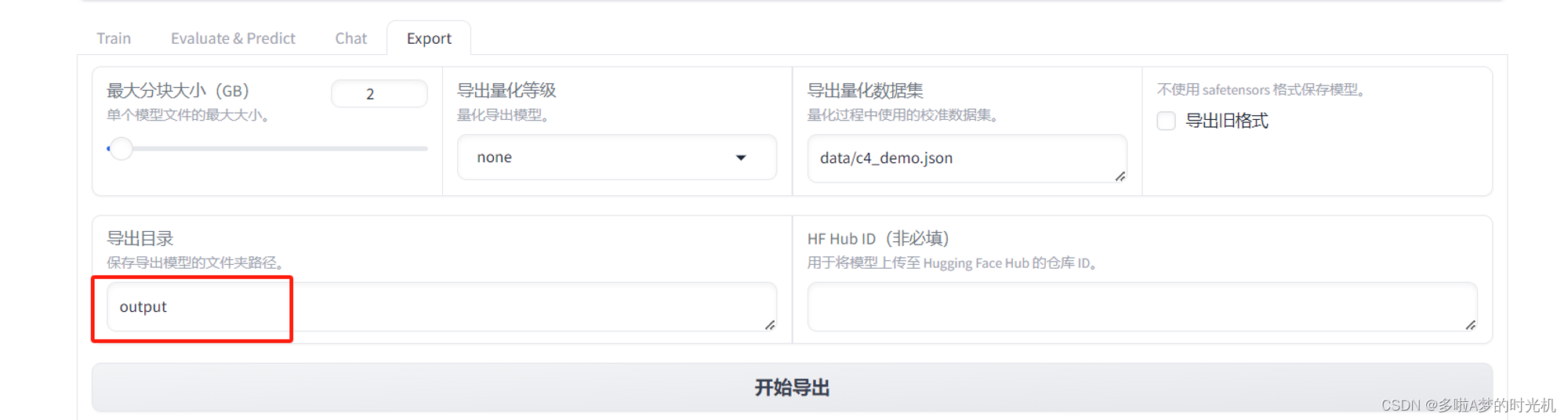
导出后的文件是这样的,这些就是我们日常见到的模型文件了

到此,LLama-facory微调平台的部署以及初步的使用就结束了。















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









