






本文没有基础知识讲解,如果是需要了解基础知识,可以直接关闭,本文是要讨论在微调模型过程中遇到的问题,并把我实践出来的结果分享出来。
在前面的文章中我们已经教大家如何搭建llama-factory微调平台,现在我们开始使用该平台对Chat-glm3-6b进行LORA微调。
本地的微调使用的GPU是A30 24G,本文的数据集全部来之huggingface
在微调本地的大语言模型的过程中,到底多少条数据会对大模型微调以后产生影响呢?
是数据质量的问题?
是数据数量的问题?
跑完微调以后应该怎么验证?
不同数量的数据集,应该怎么设置训练的参数?
下面我们来逐一实践,用实践出来的答案来回答问题。
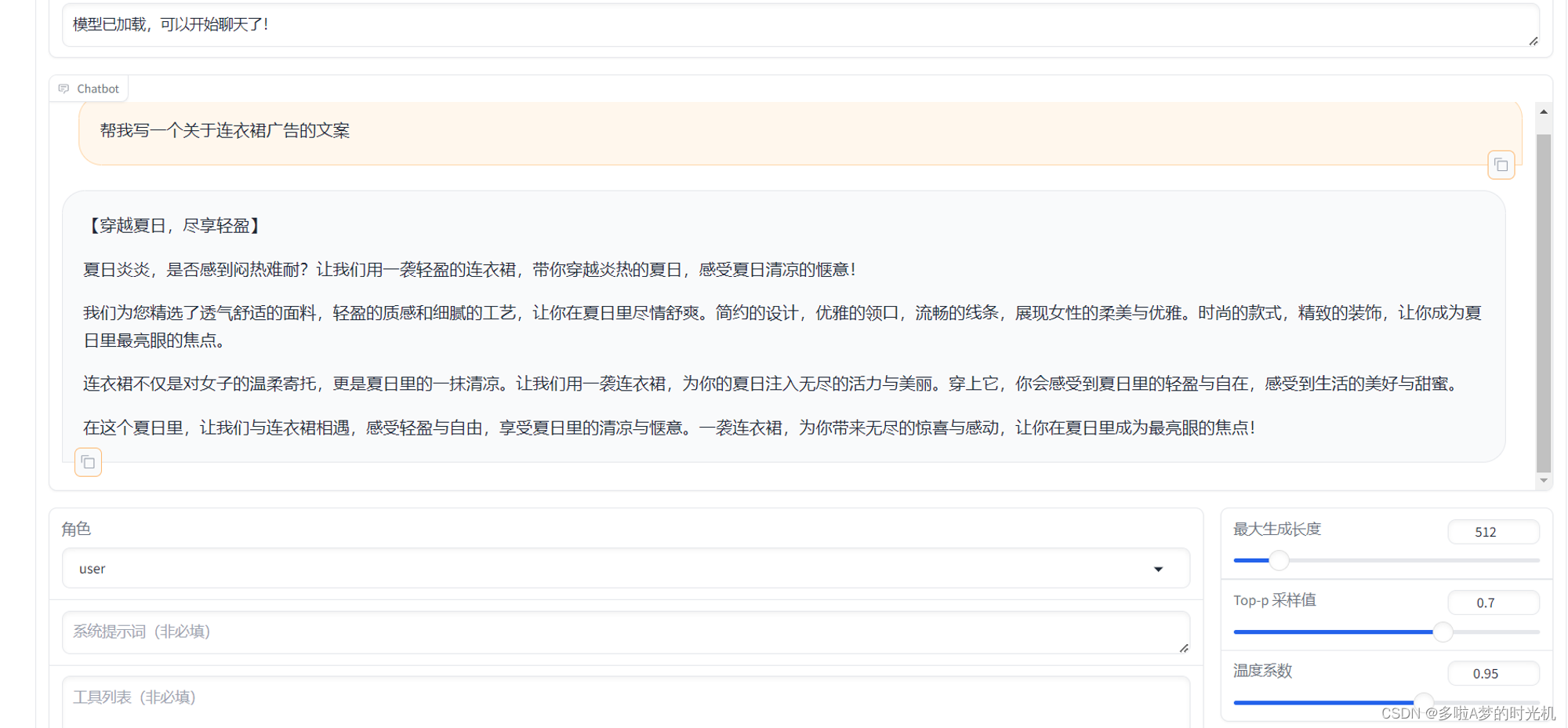
这是使用GLM3给出的广告数据集微调以后得出的答案,官方给的广告数据大约有12W条左右。在使用SFT-LOR训练3论以后,生成的效果如下,个人感觉效果是有,但不是很明显,要么就是GLM3-6B新版的模型已经把这个样例的数据集给包含进去了

这是用原始模型得出的答案

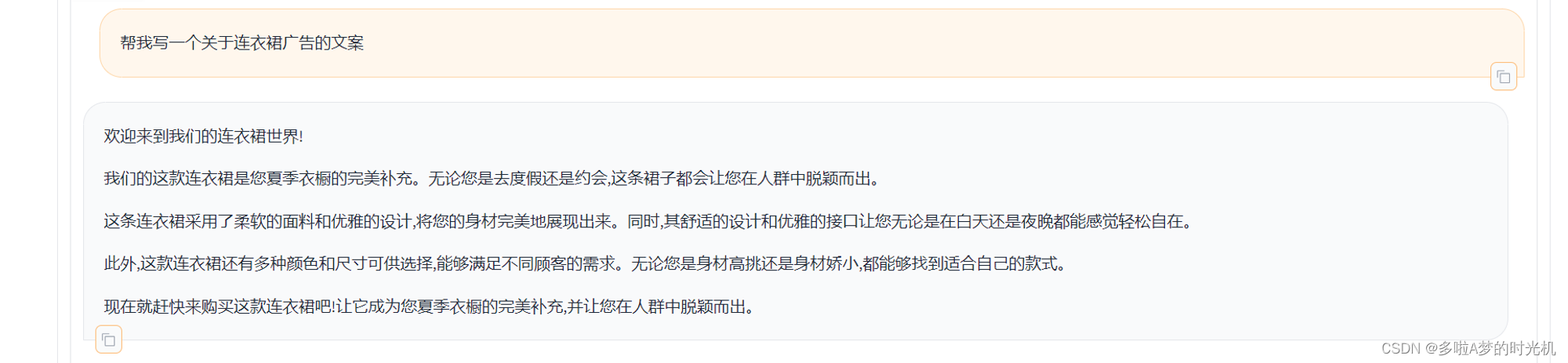
从上面的结果来看,在数据量很少的情况下微调其实没什么效果。
下面我们换数据集,这是医疗数据集的参数量,大概100W条,训练参数如下

训练市场大概需要20个小时,效果未知。loss的数值如下,看上去似乎还可以。

现在我使用1000W的医疗数据参数微调GLM3-6B模型,发现不同的学习率以及样本数会以及训练轮数都会影响微调大语言模型的微调结果,所以对于6B这类模型来说,参数集数量与学习率,训练轮数的关系,需要根据实际情况进行不断的调整。指望一次就能训练出你想要的模型是不现实的。


这是2e-4学习率,50轮训练,500最大样本数的训练结果


最终的训练数据,loss 在0.001这个区间
{'loss': 0.001, 'grad_norm': 0.008626515045762062, 'learning_rate': 3.9339915217651014e-10, 'epoch': 49.733333333333334}
llama_factory | 05/03/2024 07:52:37 - INFO - llmtuner.extras.callbacks - {'loss': 0.0009, 'learning_rate': 0.0000e+00, 'epoch': 49.78}
经过粗略的使用测试,模型还是会出现重复叙述一段话的问题,个人感觉,要是数据集质量差,会把原有的模型练成弱智,训练次数太多,会把大模型练到过拟合,只会回答训练集的问题,丧失了模型能力。
以下就是最好的证据
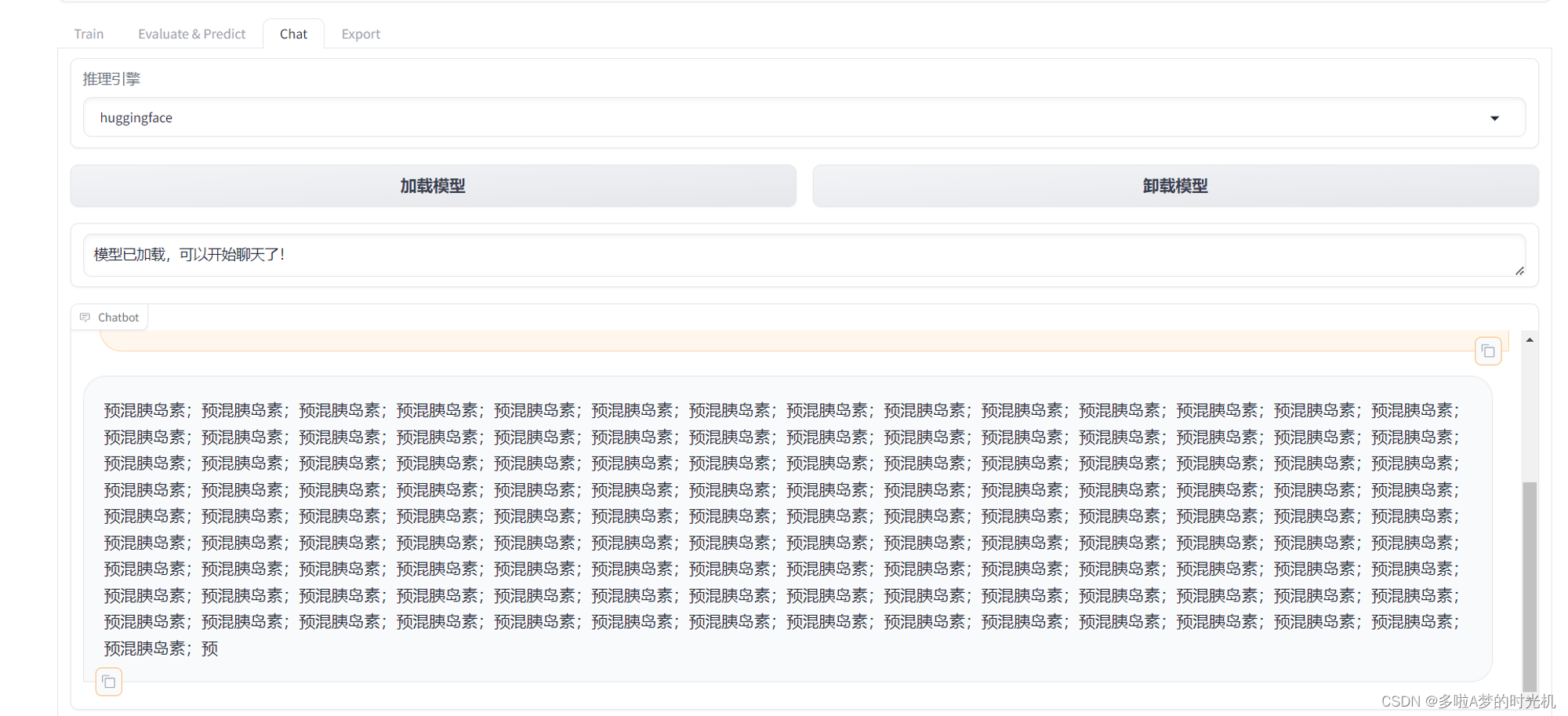
这种数据集质量是很差的
 以上的结果告诉我们一个道理,在你不是很了解模型且非必须场景下,能用RAG知识库解决的问题,就使用知识库,能不要微调的就不要微调。微调模型是最后的手段。
以上的结果告诉我们一个道理,在你不是很了解模型且非必须场景下,能用RAG知识库解决的问题,就使用知识库,能不要微调的就不要微调。微调模型是最后的手段。















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









