







 本文分析了2016年全球主要国家的人口与GDP情况,探讨了人均GDP水平,并列举了部分发达国家的经济表现。特别关注了人口超1亿的国家以及人均GDP超过特定阈值的国家。
本文分析了2016年全球主要国家的人口与GDP情况,探讨了人均GDP水平,并列举了部分发达国家的经济表现。特别关注了人口超1亿的国家以及人均GDP超过特定阈值的国家。
世界人均gdp 以 土耳其为分界线,低于土耳其的,低于世界平均水平, 大概1万美元(世界排名60)
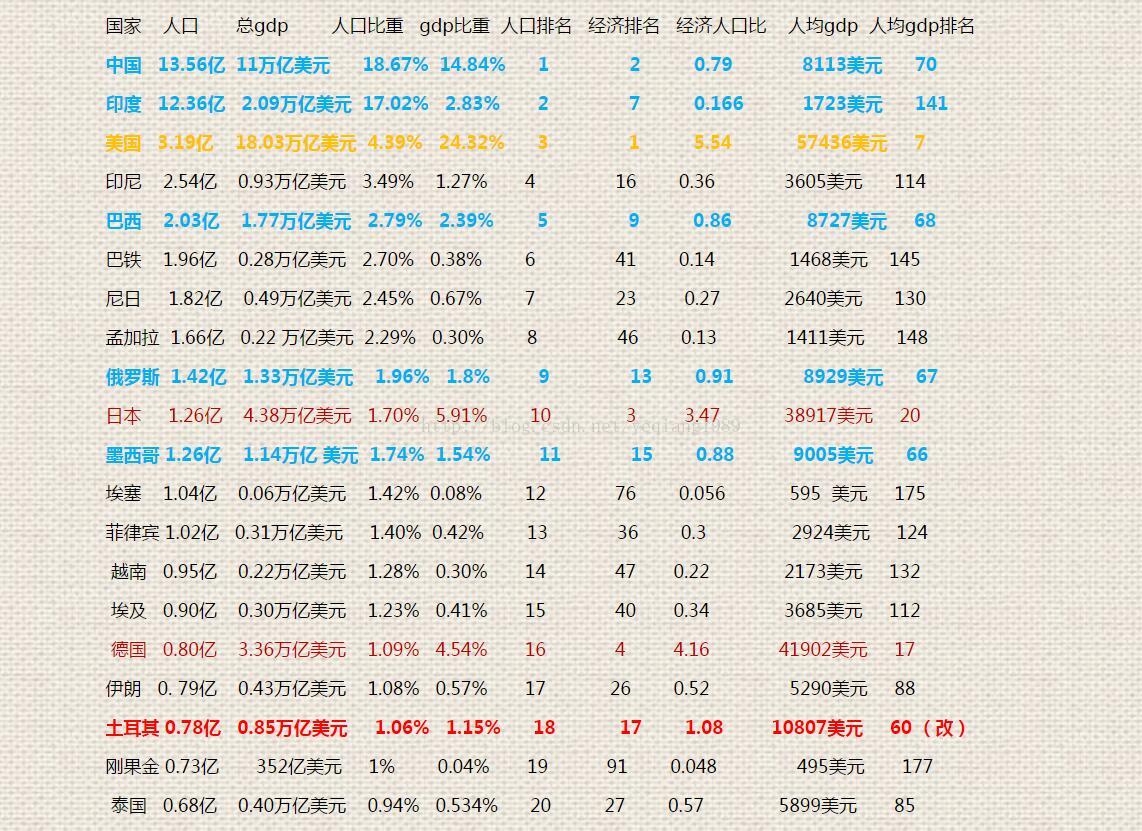
先以世界人口前30统计,世界上超过1亿的国家13个。超过两亿的5个 超过十亿的2个。亚洲是人口比重最大的地区约占60%
世界各国人口前20的国家 人口, gdp 人居gdp 以及相关排名(大国都以2016年的为基准)
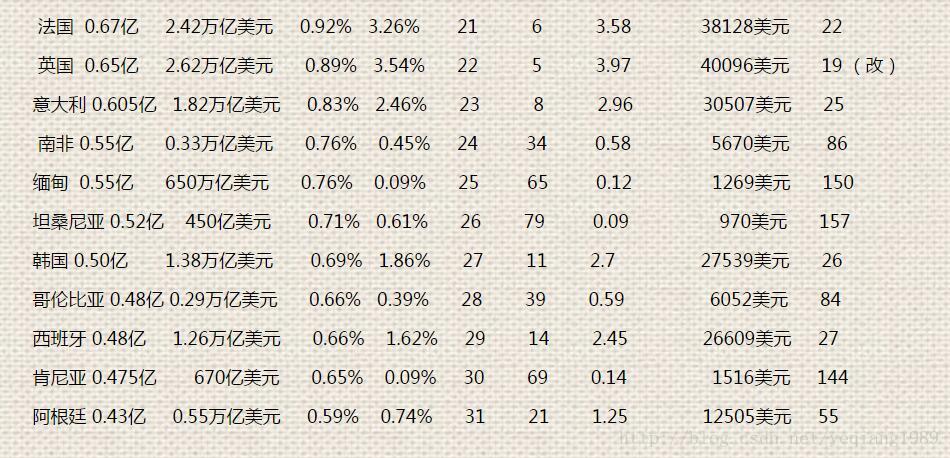
世界各国人口21-30的国家 人口, gdp 人居gdp 以及相关排名(大国都以2016年的为基准),其中英国的gdp 修正了下。不再以某机构发布的2.8万亿美元作为基准,那个计算属于异动值。
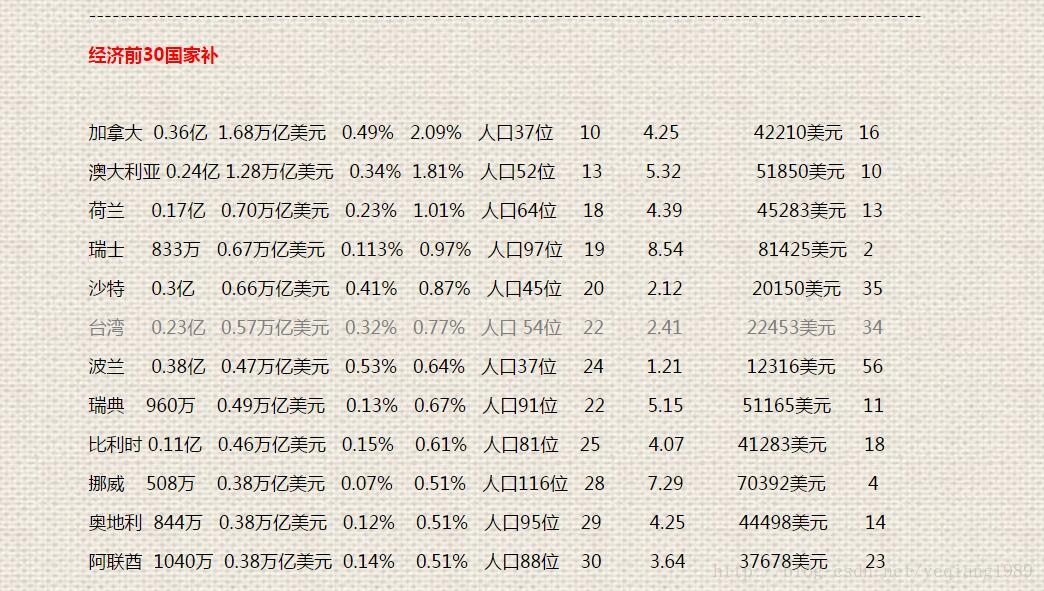
本来最初想以gdp前30开始统计这些数据,但是这种统计最容易错过一些发展中的大国家;
下面补上2016年gdp总量排进前30的国家,但是人口不是前30名的。这里面澳大利亚,加拿大,荷兰,瑞士,挪威,瑞典,阿联酋也是高度发达的国家。像瑞士,挪威,美国,澳大利亚的经济强国人均都进了前10的。
说到了人均,那么上面统计的42个国家和地区,确定是没涵盖所有的人均gdp前三十的国家
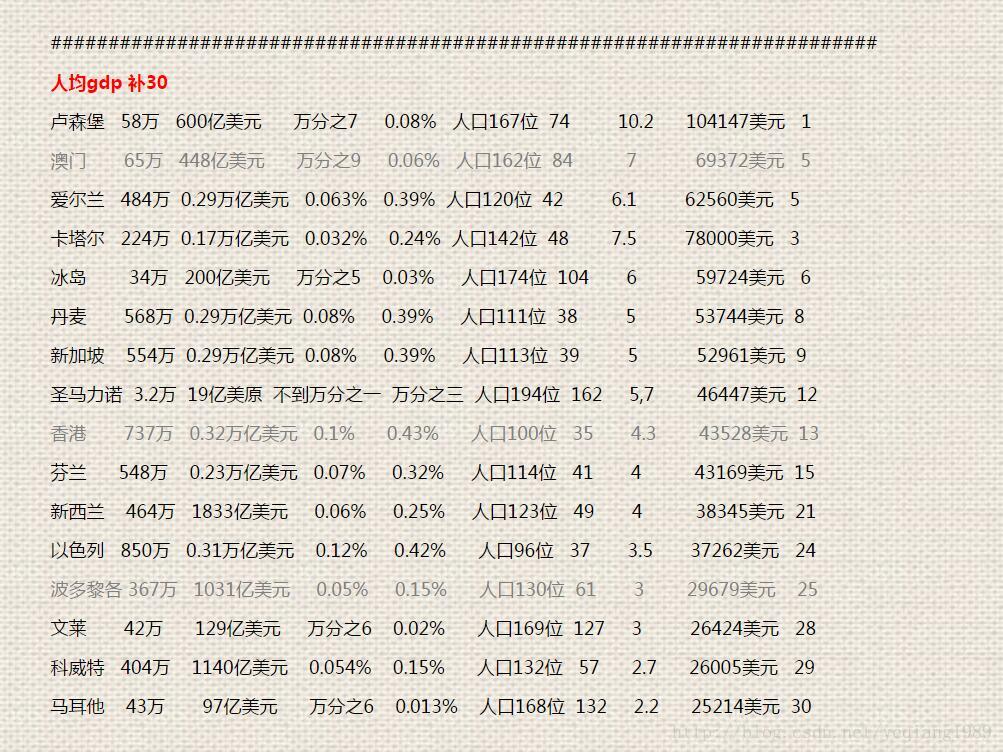
这些国家人口几乎都是100名之后的,但是几乎都来自欧洲,亚洲3个国家2个地区,大洋洲1个国家,其余的都来自于欧洲。
最新的发达国家划分39个,欧洲三十国 亚洲4国,北美2国,大洋洲的老大老二。基于部分地区人口或者其他维度没达标,虽然人均gdp很高,但是没拍进发达国家的名单。

其中 人均没进前三十或者遗珠的国家
安道尔 大于4.2万美元 前15 由于没有最新的数据没统计到
塞浦路斯 23352美元 33
捷克 18286美元 37
爱沙尼亚 17633美元 39
希腊 17901美元 38 被危机拖垮了
拉脱维亚 14060美元 51 人均略低
列支敦士登 16237美元 43
立陶宛 14890美元 49
摩纳哥 大于16万美元 1 被遗珠的人均最高的国家,16万美元还是11的数据
葡萄牙 19863美元 36
圣马力诺 大于5.8万美元 6 被遗漏的前5人均国家,这个5.8万美元还是4年前的数据
斯洛伐克 16499美元 40
斯洛文尼亚 21320美元 34
在亚洲人均达到2万美元 几乎进入发达国家行业,欧洲的人均标准低一些1.4万美元是门槛。美洲也是2万美元门槛。但是不知道为啥巴哈马没进入发达国家。非洲没有发达国家,人均最高的是塞舌尔1.5万美元左右。大洋洲也是两万美元的门槛。
数据修正,下面是世界银行的 前61gdp
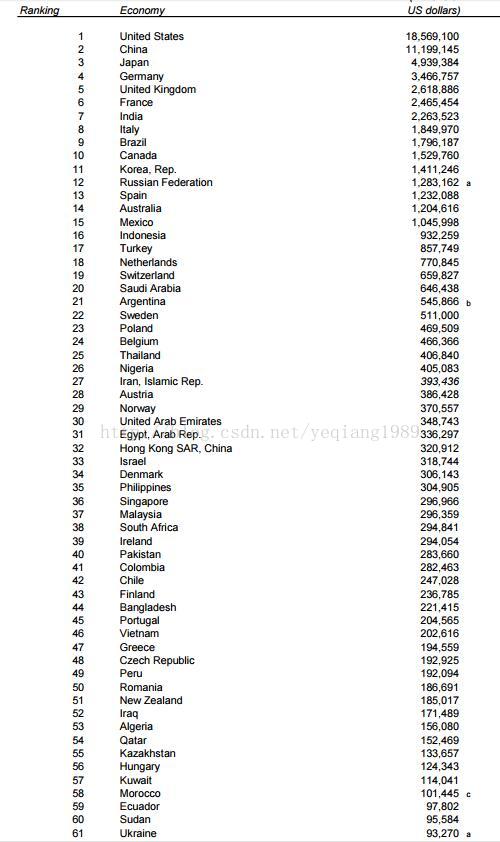

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









