







对自己近一个月来学习map、reduce过程做些总结,以备后期查看。(基于hadoop1.x)
首先是官方的经典过程图:
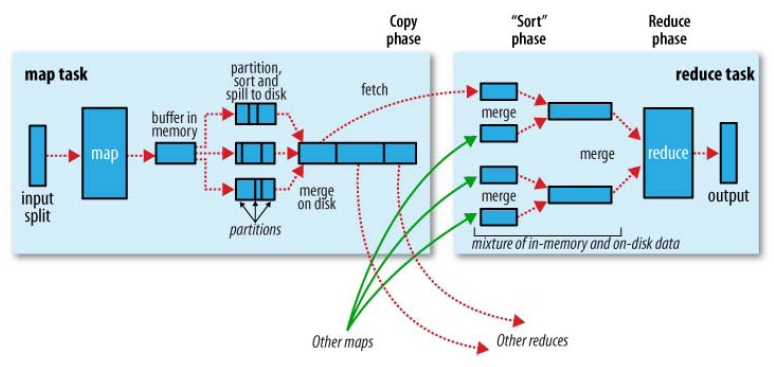
这个过程中我们会依次接触六大类:InputFormat,Map,Combine,Partition,Reduce,OutputFormat
1. InputFormat:
我们先来看一下InputFormat的抽象类需要继承类实现的方法:
@Override
public List<InputSplit> getSplits(JobContext context) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
return null;
}
@Override
public RecordReader<Key, Value> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
return null;
}可以看到它完成了2个工作:
(1)对输入数据集分片,返回若干个分片。
(2)提供RecordReader,它规定了如何处理每一个分片的每一行数据。
经过上面处理,我们获得了KeyValue对,下面要经过Map类。InputFormat类到此结束。
2. Map:
@Override
public void map(KEYIN key,VALUEIN value,Context context)
throws IOException,InterruptedException{
System.out.println("进入Map");
context.write(KEYOUT, VALUEOUT);
} 这里KEYOUT,VALUEOUT就是map的输出。
之后,Map的输出到Reduce的输入中间经过了一个复杂的过程:
map的每个输出都会先写入缓存(buffer in memory,默认100MB,可以在job提交前通过io.sort.mb修改),该100MB的缓存有个阈值80MB(默认0.8,可以通过io.sort.spill.percent修改)。注意,这里引入了第三个类Partition。
3. Partition:
在map函数中的context.write(key,value)将keyvalue对写到了缓存中,在写入时同时写入的信息还有partition(即这条数据会发往哪一个reducer进行处理)。我们可以自定义Partition的实现类,来细粒度地控制该条记录的最终归属,比如在全排序中会用到。
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
// TODO Auto-generated method stub
return 0;
}我们继续Map的后续工作:
到缓存中数据量大于阈值后,会锁定这80MB的数据,启动一个spill(溢写)线程将这80MB数据写入一个单独的磁盘文件中,在写入前,会先对着80MB的数据进行快排(排序的算法是先按keyvalue记录的partition排序后按key的compare方法),之后如果JobClient有明确设置Combiner,会进行combine。注意,这里引入了第四个类Combine。
4. Combine(实际上就是Reducer)
接上面,如果JobClient有明确设置Combiner(job.setCombinerClass(Class<? extends Reducer>)),会进行combine过程,即将相同的KeyValue对的value合并,以减少spill到磁盘的文件的大小。Combiner会优化MapReduce的中间结果,所以它在整个MapReduce过程中会多次用到。
我们继续Map的后续工作:
每一次buffer达到阈值都会spill,每一次spill后磁盘上都会多一个spill后的文件,这些文件最后要合并成一个文件作为map的输出文件(每个map task只有一个输出文件)。归并的过程叫:merge,归并的方法类似多路归并算法,因此最后的输出是有序的!又因为是多个溢写文件合并,因此若设置了Combiner,它同样会将相同Key的KeyValue对的value合并。
至此,一个map task的一个输出文件诞生了(它保存在本地磁盘中,又称中间文件,map端工作结束)。它里面的每条数据都标记了partition、有相同partition的数据是有序排列的。
5.Reduce
在map过程中强调数据在本地计算,即优先数据在哪就把map任务分配到哪。而reducer是需要从所有map的输出文件中把属于自己的copy过来,所以会占用网络带宽。
从不同task tracker拿到的文件也是先写入buffer(原理同map的写入buffer),当buffer中的数据达到阈值,就写入磁盘。存数据的过程叫merge,merge过程可以发生在:
(1)内存到内存的merge。默认关闭,如果开启表示最后如果内存有数据,不会先全部写入磁盘再回头跟磁盘上的其它数据一起merge,而是直接在内存中merge,再与磁盘中的其它数据merge。
(2)内存到磁盘的merge。与map端的spill类似。
(3)磁盘到磁盘的merge。最后将所有(2)之后的文件进行最终merge,注意(1)的情况。
之后开始reduce的过程,即merge的最终输出是reduce的输入,reduce的输出默认是输出到HDFS上。输出格式由OutputFormat类确定。
6. OutputFormat
默认使用TextOUtputFormat类,得到<Key,value>对,即输出样式为:key+“”+value。我们可以自定义输出类,控制以什么格式输出,输出到哪里等方面。
以上是这个阶段的学习小结,以备忘记时回顾。初学hadoop,难免有误,如有错误,请不吝指教。















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









