







機器學習基石 (Machine Learning Foundations) 学习要点小结:
课程来自coursera:
https://class.coursera.org/ntumlone-002/lecture
第5节 Training versus Testing
上面几节课告诉我们:
如果hypothesis set是有有限种选择,训练样本data够多,那么不管学习算法A怎么选择,样本的判别结果都会与总体的一致。如果此时,我们从找到H中找到一个g,使得Ein很小,那么我们就可以说可以通过learning学到东西。
因此hypothesis set的大小M非常重要,如果M太小,可供选择的hypothesis就太少,很可能找不到接近f的g;如果M太大,那么Ein就很可能变大,使得找到的g不接近f。
那么M取多少呢?
其实,M是满足一个成长函数的规律(Grow Function),对于不同的h(x),其Grow Function不同。
我们既然想用Grow Function去取代原来无限的M,但是,经过分析,M可能是多项式级别的,这对我们来说是好消息,但是,M也可能是指数级别的,这对我们来说是坏消息,因为这样我们就无法保证Ein和Eout在data大小N越大的情况下充分的接近。

继续实验,发现对于2D的PLA,Grow Function对于3个点可以区分2^3=8个所有情形,对于4个点就无法区分2^4=16个所有情形了,这时,我们把4叫做PLA的break point。然而,对于convex set的Grow Function为2^N,不存在一个break point。我们因此也就可以猜想:
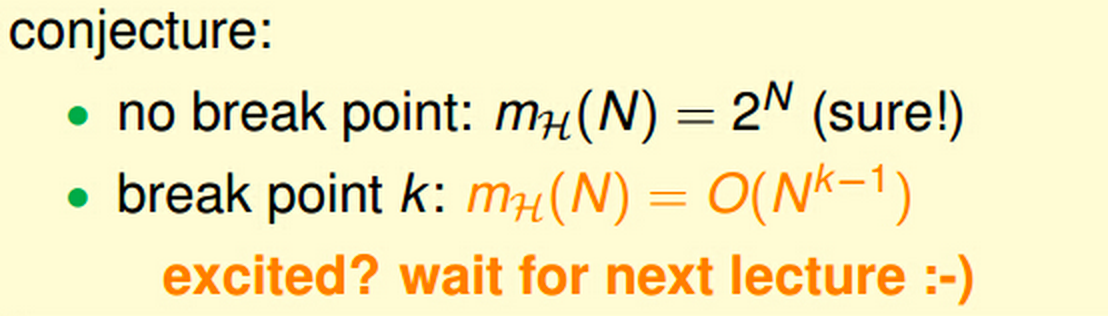
第6节 Theory of Generalization
上面我们定义了break point(“漏出一线曙光的点”):
即一个grow function如果在data大小为N的时候,无法产生2^N个所有情形,就说这个grow function的break point在N。
接着推导发现:如果grow function的break point在k,那么当N>k时,会极大的限制grow function的最大值。
下面我们就需要计算一个grow function在存在k的前提下的最大值。如果最大值是一个多项式的话,我们就可以说Ein-Eout在某种情况会接近,即learning是可以做到的。
经过推导,我们得到了grow function的上限函数bounding function的上限:

接着,用bounding function替换hoeffding’s equality中的M:

例如,对于2D的PLA,break point k = 4,bounding function= O(N^3)。当资料N足够大的时候,Ein 接近 Eout的概率很大,可以达到learning的效果。
第7节 The VC Dimension
定义VC dimension为the formal name of maximum non-break point,即dvc = minimum k - 1;

上图表示:
如果N<=d_vc,则存在某个D会被hypothesis shatter。表示训练数据有可能被hypothesis shatter到,但是不一定;如果N>d_vc,则可以肯定的是它一定不能被shatter到。
对于1维的perceptron,dvc = 2;
对于2维的perceptron,dvc = 3;
对于3维的perceptron,dvc = d+1;
dvc的物理意义:effective ‘binary’ degree of freedom
dvc大致可以想象成为我们有多少可以调的旋钮。
选择一个有合适的dvc的hypothesis set非常重要:
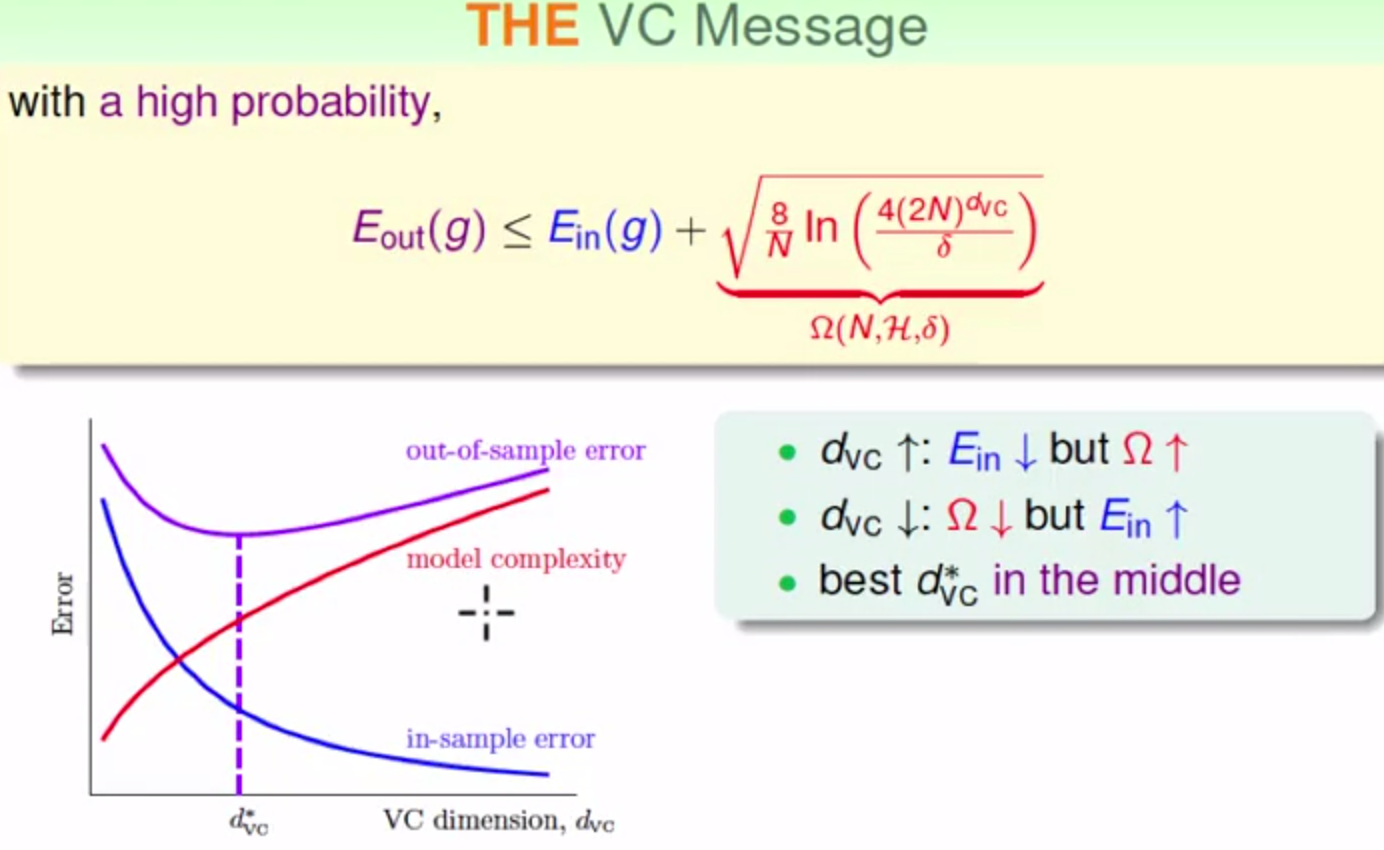
从另一个方面来看dvc,我们希望Ein-Eout发生坏事情的概率足够小,也就是希望发生好事情的概率足够大。

所以dvc也可以用来描述model complexity,dvc越大,model complexity就越大。
除此之外,dvc还可以描述sample complexity,即样本复杂度。
通过计算会发现,理论上需要的训练数据量会是1w倍的dvc;但在实战中,一般只需要10倍dvc的数据量就能达到还不错的效果。
第8节 Noise and Error
我们选择好适合特定应用的error measure: err,然后在训练时力求最小化err,即,我们要让最后的预测发生错误的可能性最小(错误测量值最小),这样的学习是有效的。















 5340
5340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









