







哈希表,也叫散列表,是根据关键字而直接访问在内存存储位置的数据结构。也就是说,它通过把键值经过一个映射函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称作散列函数,存放记录的数组称作散列表。
由哈希表的定义可知,散列函数关系到关键字映射到什么散列表的什么位置,实际上散列表的单元是有限的,但是关键字的个数却往往远大于该单元个数,我们必须又同时保证每个关键字通过映射函数的计算都会对应到散列表的某个位置,这样不可避免的就存在冲突的问题,即多个关键字对应于散列表的同一位置,我们必须解决这个问题。
所以哈希表就有了两个关键点:散列函数和解决冲突。散列函数和解决冲突的方法请参考维基百科,这里不做赘述。
这里的散列函数采用除留余数法,解决冲突采用分离链接法。
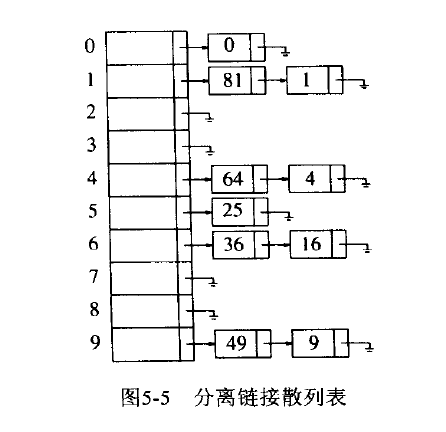
上图来源于《数据结构与算法分析:C语言描述》(维斯)。在上图模型中,链表是带有表头的,带有表头是为了更好的执行删除操作,但同时也会造成空间的浪费。维斯在书中建议如果在散列的诸历程中不包括删除操作,那么最好不使用表头,这估计是考虑到删除头节点的情况,事实上即使不带表头指针,也可以比较方便的删除头节点,我们会在后面的删除操作中讨论。
一、哈希表数据结构
class HashTable;
class Node
{
public:
Node(int _data) :data(_data), next(NULL){}
friend class HashTable;
private:
int data;
Node *next;
};
class HashTable
{
public:
HashTable(int _TableSize);
~HashTable(){
MakeEmpty();
delete[] List;
}
unsigned int Hash(int);
void Insert(int);
void Delete(int);
Node *Find(int);
void MakeEmpty();
private:
int TableSize;
Node **List;
};//返回:N为素数,返回N;N不为素数,返回大于N的最小的素数
static unsigned int nextPrime(int N)
{
int i;
if (0 == N % 2)
++N;
for (;; N += 2)
{
for (i = 3; i*i <= N; i += 2)
{
if (0 == N % i)
{
N += 2;
i = 3;
}
}
return N;
}
}
HashTable::HashTable(int _TableSize)
{
TableSize = nextPrime(_TableSize); //指定哈希表长度为素数
List = new Node*[TableSize]; //分配指针数组空间
for (int i = 0; i < TableSize; ++i) //初始化
List[i] = NULL;
}这里采用的是不带表头的链表,在分配时,直接分配链表节点指针数组空间。
三、散列函数
这里采用除留余数法,返回该数值在哈希表中的索引。
unsigned int HashTable::Hash(int data)
{
return data % TableSize;
}采用拉链法,通过哈希函数将键值转换为数组的索引(0-M-1),然后将键值存入对应数组索引的链表中,但是不可避免的是,由于哈希函数的选择,会有两个或多个键值具有相同的索引值,我们就必须用一种方法来处理这种冲突,这里我们采用的是哈希碰撞冲击。
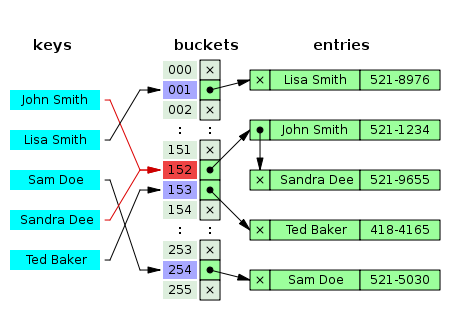
如上图所示“John Smith”和“Sandra Dee”通过哈希函数都指向了152这个索引,该索引又指向了一个链表,在链表中依次存储了这两个字符串。选择足够大的数组,使得所有的链表都尽可能的短小,可以保证查找的效率。
四、查找、插入、删除
4.1 查找,哈希表具有很高效的查找功能,可达到常数时间查找。
//返回指向该值的指针,没有则返回NULL
Node* HashTable::Find(int data)
{
unsigned int Index = Hash(data);
Node *list = List[Index];
while (list != NULL && list->data != data)
list = list->next;
return list;
}//哈希表中数据唯一
void HashTable::Insert(int data)
{
unsigned int Index = Hash(data);
Node *Pos = NULL;
Pos = Find(data);
//调用下面代码可以减少一个散列函数的调用计算
/*
Pos = List[Index];
while (Pos != NULL && Pos->data != data)
Pos = Pos->next;
*/
if (NULL == Pos) //该项不存在表中
{
Node *pNew = new Node(data);
pNew->next = List[Index];
List[Index] = pNew;
}
}当多个键值散列到同一个索引时,我们必须处理这种冲突,这里采用的是哈希碰撞冲击,就是将哈希表退化为一个单链表,然后相应的插入,查找效率都从O(1)退化到了链表的查找操作。
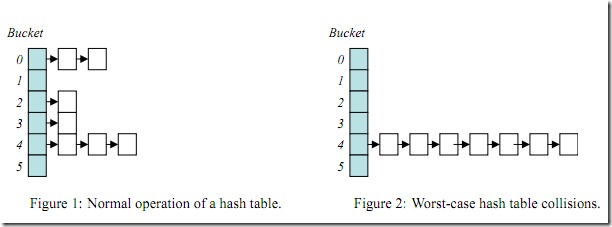
4.3 删除操作相对复杂,事实上哈希表用于查找时,很少用到删除操作。
这里删除需要考虑几种异常情况:
1. 数值不存在表中;
2. 数值对应表头节点,以及哈希表对应索引仅此节点;
3. 数值对应链表中间;
4. 数值对应链表的尾端元素。
void HashTable::Delete(int data)
{
unsigned int Index = Hash(data);
Node *list = List[Index];
if (list != NULL)
{
if (list->data == data) //头节点元素
{
List[Index] = list->next;
delete list;
}
else
{ //找到数值节点的前一个节点
while (list != NULL && list->next != NULL)
{
if (list->next->data == data)
{
Node *temp = list->next;
list->next = temp->next;
delete temp;
}
list = list->next;
}//end while
}//end else
}//end if
}每插入一个非重复节点,就需要开辟一个节点的空间,所以哈希表是一个用空间换取时间的数据结构。
清空哈希表,要删除哈希表中的每个节点数据,包括链表中的数据,既要遍历哈希表数组空间,又要遍历哈希表每个数组空间的链表节点。
void HashTable::MakeEmpty()
{
Node *list = NULL;
for (int i = 0; i < this->TableSize; ++i)
{
list = List[i];
while (list != NULL)
{
Node *temp = list;
list = list->next;
delete temp;
}
List[i] = NULL;
}
}析构函数则在清空哈希表的基础上,释放指针数组空间。
哈希表可以用来以常数平均时间实现 Insert 和 Find 操作。实际上执行一次查找所需要的工作是计算散列函数值所需要的常数时间加上遍历链表所用的时间。















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









