







生成模型的研究中,文本到图像的生成一直是一个充满挑战的任务。传统的扩散模型虽然在生成质量上取得了显著的成果,但其生成过程往往需要大量的迭代步骤,这不仅导致计算成本高昂,而且生成速度缓慢,难以满足实时或近实时应用的需求。随着技术的发展和应用场景的不断扩展,如何在短时间内生成高质量、高分辨率的图像样本,已成为该领域亟待解决的关键问题。
在这样的背景下,SDXL-Lightning模型的出现,为文本到图像的生成任务带来了革命性的突破。SDXL-Lightning是一种基于扩散蒸馏方法的模型,它通过结合渐进式和对抗性蒸馏技术,在保持图像质量的同时显著减少了生成所需的步骤。这一创新不仅大幅度提升了生成效率,同时也在模式覆盖和图像细节上取得了平衡,为用户提供了更为丰富和真实的视觉体验。

SDXL-Lightning的优势在于其能够在单步或少步骤内完成1024px高分辨率图像的生成,这一点在现有的生成模型中是前所未有的。相比于传统的扩散模型,SDXL-Lightning在以下几个方面展现出其独特的优势:
效率提升:通过优化的蒸馏过程,SDXL-Lightning大幅减少了生成高质量图像所需的推理步骤,从而加快了生成速度,降低了计算资源的消耗。
质量保证:即便在减少推理步骤的情况下,SDXL-Lightning依然能够保持甚至提升生成图像的质量,这得益于其先进的对抗性蒸馏技术,能够在每一步生成中实现更加精细和逼真的细节。
模式覆盖:SDXL-Lightning在设计中特别考虑了模式覆盖的问题,确保了生成的图像不仅质量上乘,而且在风格和内容上具有多样性。
通用性和兼容性:该模型具有良好的通用性,能够适应不同的数据集和模态,同时与现有的LoRA模块和控制插件兼容,为用户提供了更大的灵活性和创造性空间。
SDXL-Lightning模型的开源,为学术界和工业界提供了宝贵的资源,促进了生成模型技术的发展和应用创新。
方法 (Method)
在传统的模型蒸馏过程中,均方误差(MSE)损失函数被广泛用于衡量学生模型预测与教师模型预测之间的差异。然而,在少步骤生成的场景中,学生模型往往因为模型容量的限制,无法精确捕捉教师模型的复杂概率流。这种容量不匹配导致在MSE损失下,学生模型倾向于产生模糊的结果,而非清晰、细节丰富的图像。具体来说,当模型在多步骤生成中堆叠使用时,由于其Lipschitz常数的增加和非线性特性的增强,能够近似更复杂的分布;但在少步骤生成中,学生模型缺乏足够的容量来准确近似相同的分布。
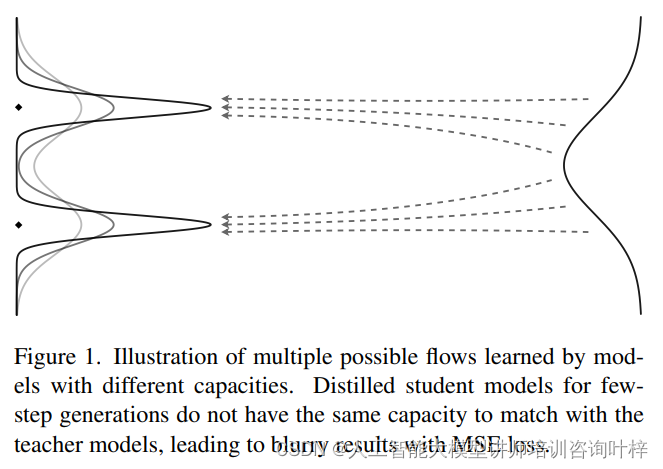
为了解决MSE损失带来的问题,SDXL-Lightning采用了对抗性目标。通过引入一个对抗性鉴别器,该鉴别器的任务是区分由教师模型和学生模型生成的样本。鉴别器D的输出表示给定条件下,样本是由教师模型生成的概率。通过非饱和的对抗性损失,学生模型被训练以最小化鉴别器判断错误的能力,从而鼓励学生预测更加接近教师预测。
鉴别器的设计采用了预训练的扩散模型的U-Net编码器作为后端。这种设计的优势在于,预训练的编码器已经对目标数据集有了深刻的理解,并且能够直接在潜在空间中操作,支持所有时间步的噪声输入,并且能够处理文本条件。鉴别器通过将教师和学生的预测作为输入,学习到底层的概率流,迫使学生模型遵循相同的流以欺骗鉴别器。
尽管对抗性目标鼓励学生模型生成尖锐且保持概率流的预测,但学生模型仍然可能因为容量限制而无法完美匹配教师模型的突变。这种不匹配可能导致“Janus”伪影的出现,即学生模型在尝试保持图像锐度和布局时牺牲了语义正确性。为了解决这个问题,SDXL-Lightning在训练后期放宽了对模式覆盖的要求,允许学生模型在一定程度上偏离教师模型的概率流,以减少伪影并保持图像的语义正确性。

SDXL-Lightning还解决了常见的扩散时间表问题。在训练过程中,模型被训练以在时间步T处接受纯噪声作为输入,而在推理时则使用旧的α时间表来避免奇异性。这种方法在现有软件生态系统中的采样过程变化最小,同时确保了训练和推理过程中模型对纯噪声的一致性处理。
蒸馏过程首先从128步蒸馏到32步,使用MSE损失,然后切换到对抗性损失,进一步蒸馏到8步、4步、2步和1步。在每个阶段,首先使用条件目标训练以保持概率流,然后使用无条件目标训练以放宽模式覆盖。LoRA模块首先用于训练,然后合并LoRA并训练整个UNet以进一步提高性能。
为了提高一步和两步蒸馏的稳定性,SDXL-Lightning采用了多种技术。这些技术包括在多个时间步上训练学生网络、在多个时间步上训练鉴别器,以及将一步模型从预测噪声转换为直接预测数据样本。这些技术的采用显著提高了训练过程的稳定性,并有助于生成更高质量的图像。
评估 (Evaluation)
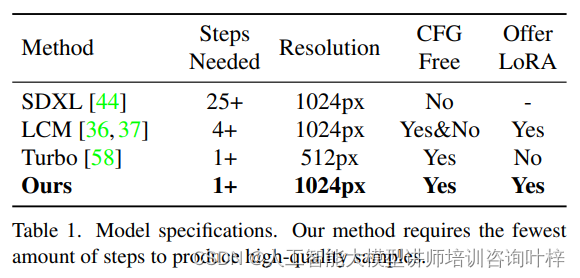
在规格比较环节,作者将其蒸馏模型SDXL-Lightning与现有的其他模型进行了详尽的对比。这一比较涵盖了生成步骤数、分辨率、是否需要分类器自由引导(Classifier-free Guidance, CFG)等关键参数。SDXL-Lightning在这些关键指标上展现出显著的优势,尤其是在减少生成步骤的同时,能够保持或甚至提升图像的分辨率和质量。
通过一系列示例图像,作者展示了SDXL-Lightning在整体质量和细节上相较于其他开源蒸馏模型的明显优势。这些示例不仅展示了SDXL-Lightning在生成高保真图像方面的能力,还突显了其在保留原始模型风格和布局方面的卓越性能。定性评估结果表明,SDXL-Lightning在各种不同的文本提示下均能生成高质量且与描述高度一致的图像。

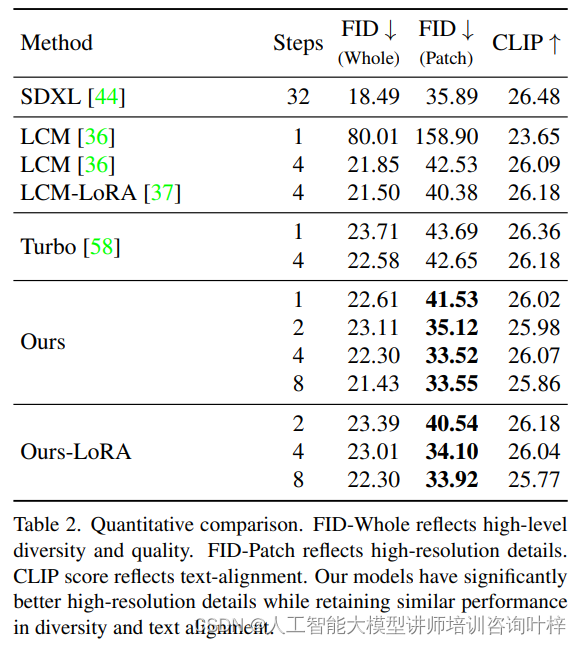
为了更客观地评估模型性能,作者采用了Fréchet Inception Distance (FID)和CLIP分数这两个定量指标。FID分数用于衡量生成图像与真实图像之间的差异,而CLIP分数则评估图像与文本描述的一致性。SDXL-Lightning在这些指标上均取得了优异的成绩,证明了其在生成高质量、高分辨率图像方面的领先地位。
消融研究 (Ablation)
作者展示了SDXL-Lightning的LoRA模型能够适应多种不同的基础模型,包括卡通、动漫和现实风格的基础模型,并在适应过程中保留了各自风格的特点和布局,这证明了LoRA模型的通用性和灵活性。

尽管SDXL-Lightning的蒸馏过程仅针对正方形图像,但消融研究显示,该模型在不同分辨率和长宽比下依然能够进行有效的推理。这一发现表明,尽管特定于正方形图像的训练可能在一定程度上限制了模型的泛化能力,但SDXL-Lightning仍然能够在一定程度上处理各种形状的图像。

作者还测试了SDXL-Lightning与ControlNet的兼容性,ControlNet是一种能够为图像生成模型提供额外条件控制的网络。测试结果表明,SDXL-Lightning能够很好地与ControlNet协同工作,即使在推理步数减少导致质量有所下降的情况下,模型仍然能够正确地遵循给定的条件,生成符合要求的图像。

尽管取得了显著的成果,此方法也有其局限性。与支持多种推理步骤设置的单一蒸馏检查点的方法不同,此方法为每个推理步骤设置生成了单独的检查点。这种设计虽然在特定应用场景下提供了灵活性,但在需要动态调整推理步骤的应用中可能会带来额外的复杂性。
而且尽管UNet架构在多步生成中表现出色,为图像的细节和结构提供了强有力的保障,但它可能并不是单步生成的最佳选择。UNet架构的设计初衷是为了在多步骤的迭代过程中逐步优化和细化生成结果,而在单步生成中,这种逐步优化的空间被大大压缩,从而可能限制了模型性能的发挥。
但这些局限性并不是不可克服的障碍。通过进一步的研究和优化,比如开发新的网络架构专门针对单步生成进行优化,或是探索更灵活的蒸馏策略以减少检查点的数量,都可以在未来进一步提升模型的效率和应用范围。
模型地址:https://huggingface.co/ByteDance/SDXL-Lightning
论文地址:https://arxiv.org/abs/2402.13929















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









