







GitLab Repo
本文章所做项目为:阿里云天池日常学习赛医疗诊疗对话意图识别挑战赛
本项目基于GitHub上的意图识别算法项目所改进
意图识别问题是什么
意图识别是自然语言处理(NLP)中的一个重要的概念。意图识别是指从用户输入的文本(如对话、问题、指令等)中提取用户的核心目的。
解决意图识别问题
1.首先需要大量用户输入的文本数据,并标注出对应的意图。(在本次研究中我们使用了由复旦大学大数据学院在复旦大学医学院专家的指导下构建的IMCS数据集,该数据集收集了真实的在线医患对话,并进行了多层次的人工标注)。
2.从文本中提取关键信息,如关键词、短语、语法结构等。(在本次研究中我们创建了一个python文件creat_dict.py,首先从训练数据文件IMCS-DAC_train.json中加载数据,然后遍历数据,提取所有对话行为dialogue_act使用 set 去重,得到唯一的对话行为列表,最后创建两个字典分别保存为JSON文件id2word.json 和 word2id.json)。
3.对训练、验证和测试数据进行预处理,生成适合模型训练和预测的数据格式。(在本次研究中我们创建了一个Python文件data_process.py,首先遍历三种数据类型,然后从对应的JSON文件中加载数据使用word2id.json 将对话行为转换为数字标签,最后为每个对话生成历史对话记录,并将其与当前对话整合,将处理后的数据保存为新的 JSON 文件)。

4.使用模型对标注数据进行训练。(在本次研究中我们创建了一个Python文件train.py,首先定义数据集类 DatasetClassify 和数据项类 DataItem,用于加载和处理数据,定义评估函数 eval,用于在验证集上评估模型性能,定义 collator_fn 函数,用于将数据转换为模型输入格式,然后加载chinese-roberta-wwm-ext模型和分词器,最后加载训练数据和验证数据进行训练循环)。

5.进行预测。(在本次研究中我们创建了一个Python文件predict.py,首先加载测试数据,使用 DatasetClassify 类将数据封装为 PyTorch 数据集,使用 DataLoader 加载数据,并通过 collator_fn 函数将数据转换为模型输入格式,然后加载预训练的模型,对测试数据进行预测,将预测结果从数字标签转换为对应的对话行为,最后将预测结果保存为新的JSON文件)。

chinese-roberta-wwm模型
chinese-roberta-wwm-ext 是一个针对中文优化的预训练语言模型,它基于 RoBERTa(Robustly Optimized BERT Pretraining Approach)架构进行了扩展和改进。这个模型由哈工大讯飞联合实验室(HFL)发布,旨在为中文自然语言处理任务提供更好的性能。
chinese-roberta-wwm-ext 基于 RoBERTa 架构,这是一种改进的 BERT模型,通过调整训练策略和数据预处理方法来提高模型的性能。
wwm采用了 Whole Word Masking 策略,这是一种改进的掩码语言模型预训练方法,旨在更好地处理中文中的词边界问题。
ext 表示该模型使用了扩展的数据集进行预训练,这可能包括更多的中文文本类型和领域,以提高模型的泛化能力。
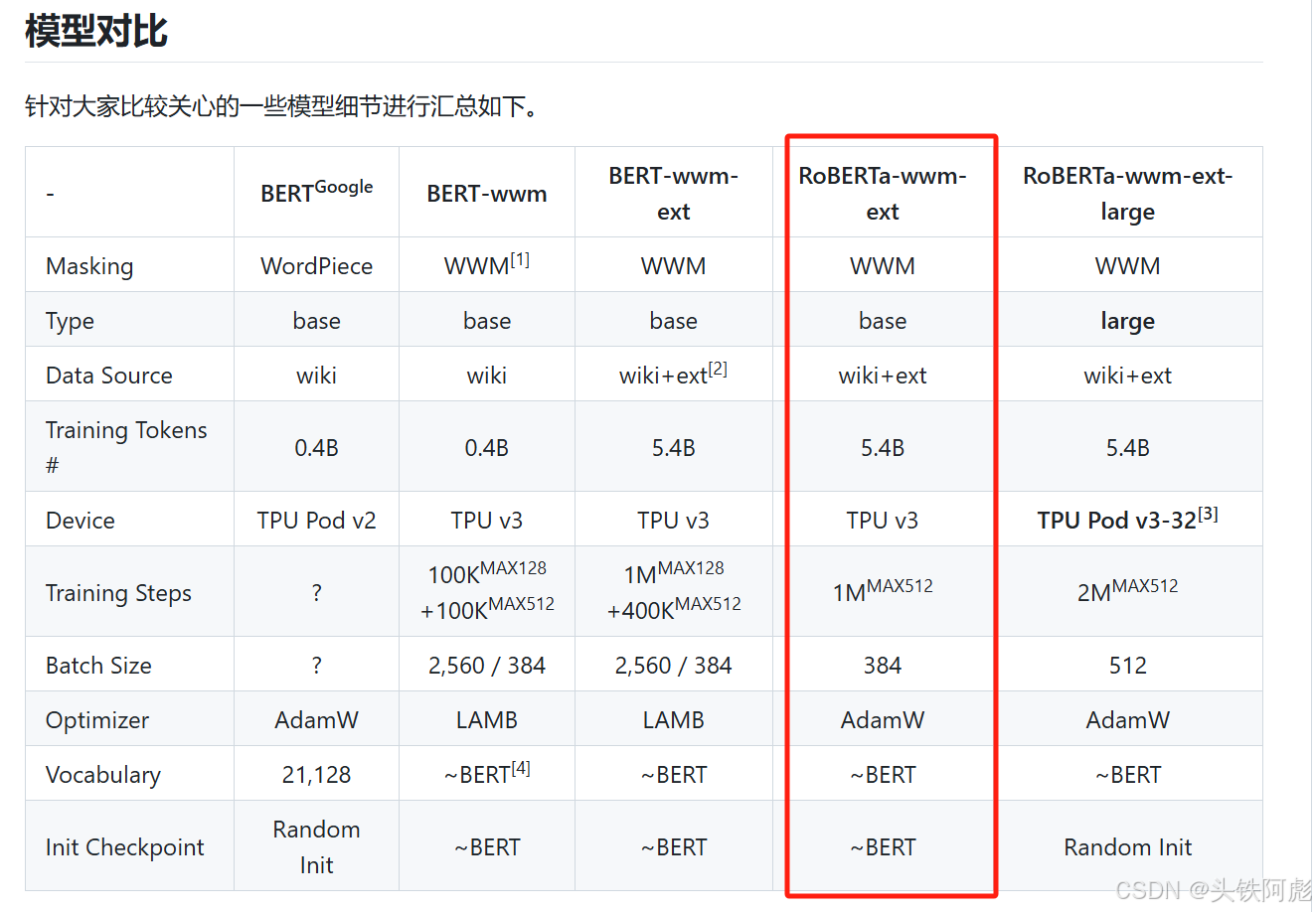
下图为不同版本的BERT模型的细节汇总,在本次研究中我们所使用的为chinese-roberta-wwm-ext模型。模型的下载访问Hugging Face社区,Hugging Face 是一个专注于自然语言处理(NLP)的公司,它提供了一个流行的开源库和模型库,主要用于构建和训练NLP模型。Hugging Face 的库和资源在机器学习社区中广受欢迎,特别是其 transformers 库,它提供了大量预训练模型,支持多种NLP任务,如文本分类、问答、命名实体识别、文本生成等。(国内访问Hugging Face社区如有网络问题可以通过国内的魔塔社区来下载模型)。
后续调整
目前模型的准确率为83%,尝试将epoch调整为20,Mini Batch Size调整为32,经测试发现数据量偏大训练时间太长且数据在训练集上效果很好在验证集上很差,推测可能存在过拟合现象。

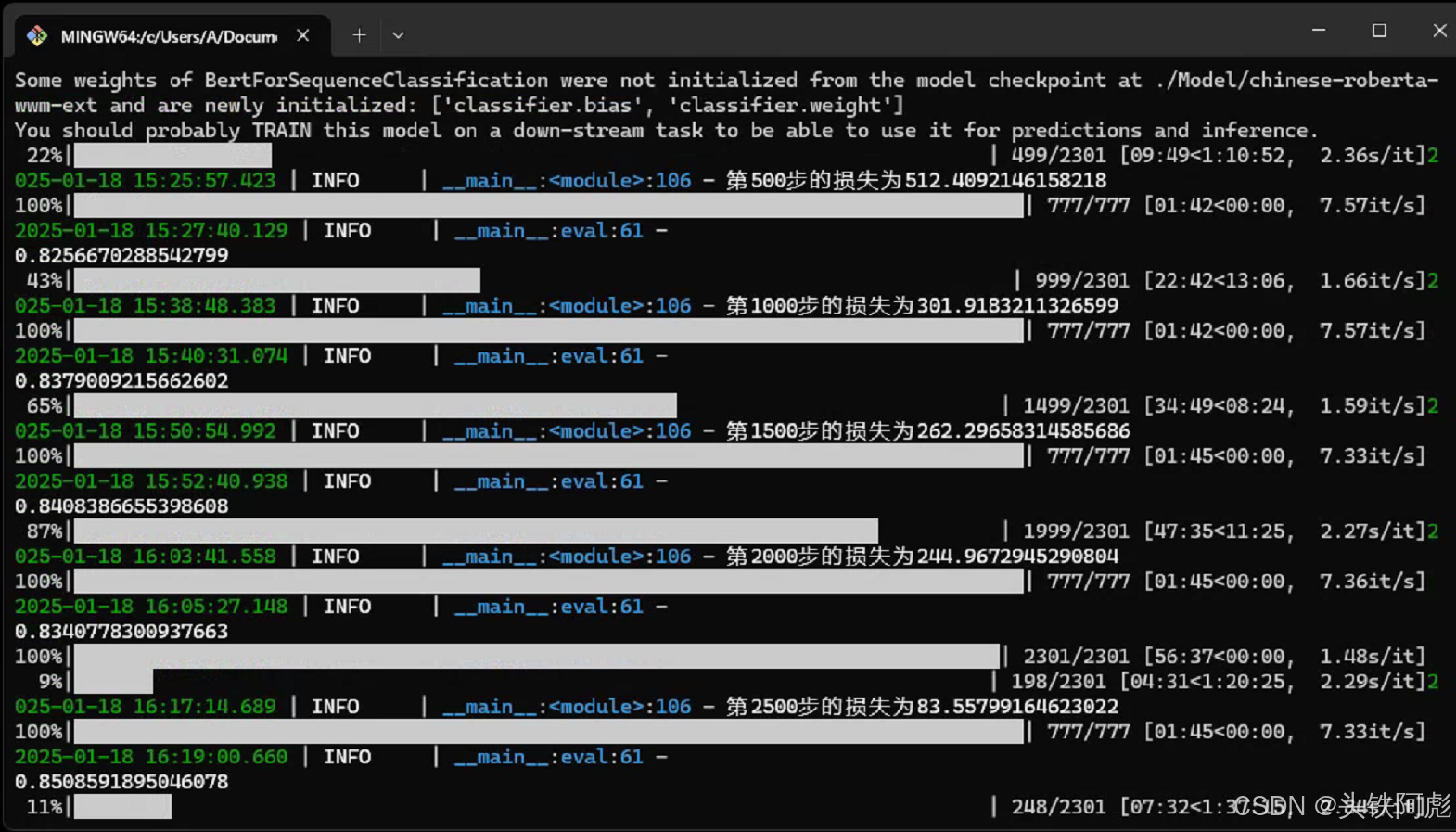

后续决定将epoch和Mini Batch Size恢复原状,使用CosineAnnealingLR 学习率调度器其学习率会按照余弦曲线的形状动态调整。通过动态调整学习率,可以在训练初期快速收敛,同时在训练后期通过较小的学习率进行微调,避免过拟合。
最后可以处理意图识别问题的模型还存在很多需要我们不断的尝试研究,该项目研究持续推进中。

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









