






- unicode字符集的编码范围是0X000000到0X10FFFF的,每个平面的范围都是0000到FFFF,共17个编码平面,编码平面用于存放不同类型的字符。
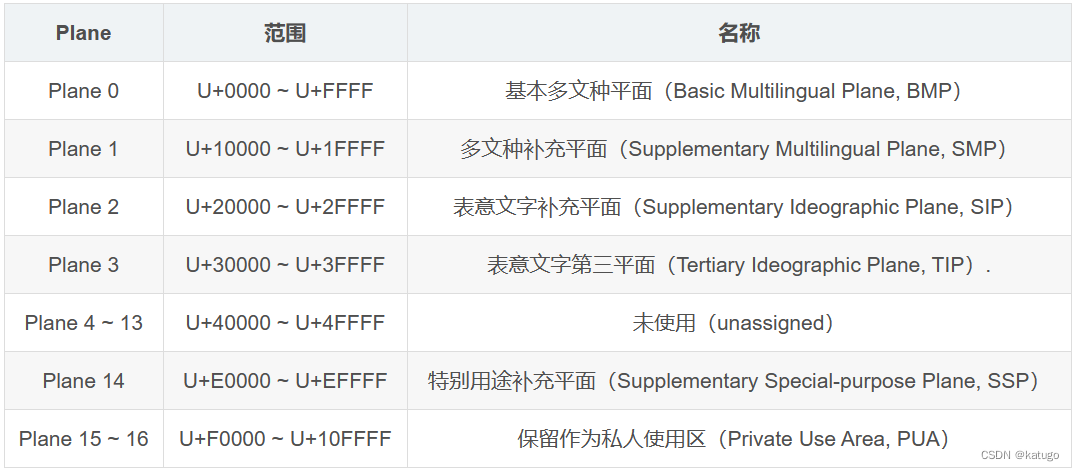
- unicode编码表更像是一个字典,而编码方式则分为UTF-8编码和UTF-16编码、UTF-32编码。
- 目的是更加利于储存和传输
- 目的是提高电脑资源的利用效率,如UTF-8按原码点的话每个都需要三个字节来表示
- 码点:每个字符对应字符集的编码值(码点在Unicode字符集范围从U+000000到U+FFFFFF)
- UTF-8编码:被定义为将码点编码为1至4个字节,具体编码字节数取决于码点数值的有效二进制的数量。
- UTF-8编码方式:


- UTF-8编码方式:
4. UTF-16编码:将字符编码成2字节或者4字节(UTF-8一个代码单元为一个字节,UTF-16一个代码单元为两个字节)
| 字节序列 | 码点位数 | 码点起值 | 码点终值 | Byte1 | Byte2 | Byte3 | Byte4 |
|---|---|---|---|---|---|---|---|
| 1 | 16 | U+0000 | U+FFFF | xxxxxxx | xxxxxxx | ||
| 2 | 24 | U+10000 | U+10FFFF | 110110xx | xxxxxxx | 110111xx | xxxxxxx |

5. 关于BOM:
- 字节序经常根据其在内存的存放顺序被分为两类,大端存储和小端存储
1. 字节序目的是为了解决一个多字节码元 code unit 中各字节的(地址)序
2. Big-Endian(大端):高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
3. Little-Endian(小端):低位字节排放在内存的低地址端,高位字节排放在内存的高地址端
4. 字节高低:靠近左边的是高位,靠右边的是低位
5. 内存地址高低:最高内存地址 0xFFFFFFFF - UTF字节序问题:最小编码单元是多字节才会有字节序的问题存在,UTF-8 最小编码单元是一字节,所以它是没有字节序的问题
- BOM(字节序标记)常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记
参考:














 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









