







一、加法模型
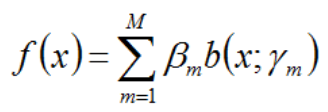
其中,b(x;rm)为基函数,rm为基函数的参数,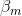
在给定训练数据及损失函数L(y, f(x))的条件下,学习加法模型f(x)称为经验风险极小化即损失函数极小化问题:
 (8.14)
(8.14)
二、前向分步优化算法
上述是一个复杂的优化问题。前向分步算法求解这一优化问题的思路是:
因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近目标函数式(8.14),那么就可以简化优化的复杂度,具体地,每步只需要如下损失函数:
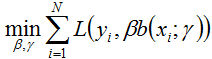
学习加法模型f(x)的前向分步算法如下:
输入:训练数据集T={(x1,y1), (x2,y2),..., (xN,yN)}; 损失函数L(y,f(x));基函数集{b(x,r)};
输出:加法模型f(x)
步骤:
(1)初始化f0(x) = 0;
(2)对m = 1,2,...,M
(a) 极小化损失函数
得到参数
(b)更新
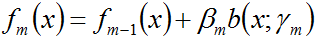
(3) 得到加法模型
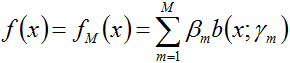
这样,前向分步算法将同时求解从m=1到M所有参数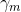
前向分步算法的损失函数是指数损失函数
L(y, f(x)) = exp[-yf(x)]
时,其学习的具体操作等价于AdaBoost算法学习的具体操作。
三、提升树模型
提升方法实际采用加法模型+前向分步算法。以决策树(CART)为基函数的提升方法称为提升树。
简言之:提升树模型 = 线性加法模型+前向分步算法+CART树(基函数)
提升树模型可以表示为决策树的加法模型:
此时树前面没有权重!
1)基函数是分类树(二叉分类树)
对于基函数是分类树时,我们使用指数损失函数,此时正是AdaBoost算法的特殊情况,即将AdaBoost算法中的基分类器使用分类树即可。
2)基函数是回归树
若基函数是回归树,则使用平法误差损失函数。对回归问题的提升树算法来说,只需简单地拟合当前模型的残差即可。
因为需要用到上一步的分类器,故而在每轮都需要计算残差,然后遍历可能的切分点,找出平方损失函数最小的切分点将输入划分为两个子集,然后依次类推,直到不能继续划分。
3.1 回归问题的提升树算法算法过程:
输入:训练数据集T = {(x1,y1),(x2,y2),...,(xN,yN);
输出:提升树fM(x).
(1)初始化f0(x)=0
(2)对m = 1,2,...,M
(a) 按式子计算残差:
![]()
(b)对于特征的每个可能值,选择平方损失函数![]() 最小的切分点,拟合残差rm学习一个回归树,得到
最小的切分点,拟合残差rm学习一个回归树,得到![]()
(c)更新 ![]()
(3)得到回归问题提升树:
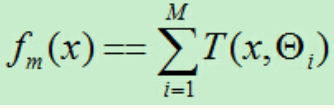
四、梯度提升(GBDT)算法
4.1 Boosting
Boosting是一种模型的组合方式,和随机森林并行训练不同的决策树最后组合所有树的bagging方式不同,Boosting是一种递进的组合方式,每一个新的分类器都在前一个分类器的预测结果上改进。
4.2 GBDT思想:
4.3 GBDT算法步骤:
面试题:
GBDT算法的流程
GBDT如何选择特征
GBDT如何构建特征
GBDT如何用于分类
GBDT通过什么方式减少误差
GBDT的效果相比于传统的LR、SVM效果为什么好一些
GBDT如何加速训练
GBDT的参数有哪些,如何调参?
GBDT的优缺点















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









