







1 前言

前面简单梳理的基本的决策树算法,那么如何更好的使用这个基础算法模型去优化我们的结果是本节要探索的主要内容。
梯度提升决策树(Gradient Boosting Decision Trees)是一种集成学习方法,通常用于解决回归和分类问题。它通过串联多棵决策树来构建一个强大的模型。在训练过程中,每棵树(CART树)都试图纠正前一棵树的错误,以逐步改进模型的性能。
在boosting算法家族中,除了adaboost会使用分类决策树为基学习器以外,其余算法如GBDT、XGBoost等,都是建立在CART回归树的基础上,换句话说就是不管处理分类问题还是回归问题,基学习器都是CRAT回归树。
2 梯度提升树
2.1 整体架构
提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree)。
2.1.1 提升树算法
提升树算法采用前向分步算法 :
...
通过经验风险最小化确定参数,
简单来说,前面大众(继承树)没有完成的由后面的人(决策树)继续完成。
2 CART树
1 回归树
输入: 训练数据集D;
输出:回归树;
- 循环遍历每个特征 j ,每个特征的值 c:寻找最佳分割点(左边是c_1, 右边是c_2):
- 选定j,s之后,对数据进行切分,计算切分之后的区域值大小(改区域样本的均值)。
- 4 继续迭代,一直到满足条件为止;
分类树
2 GDBT算法原理
GBDT 无论分类还是回归基本树都是cart,每一颗的树都是去弥补前面树的不足(即残差:真实值与预测值之间的差异),然后一步一步的迭代。
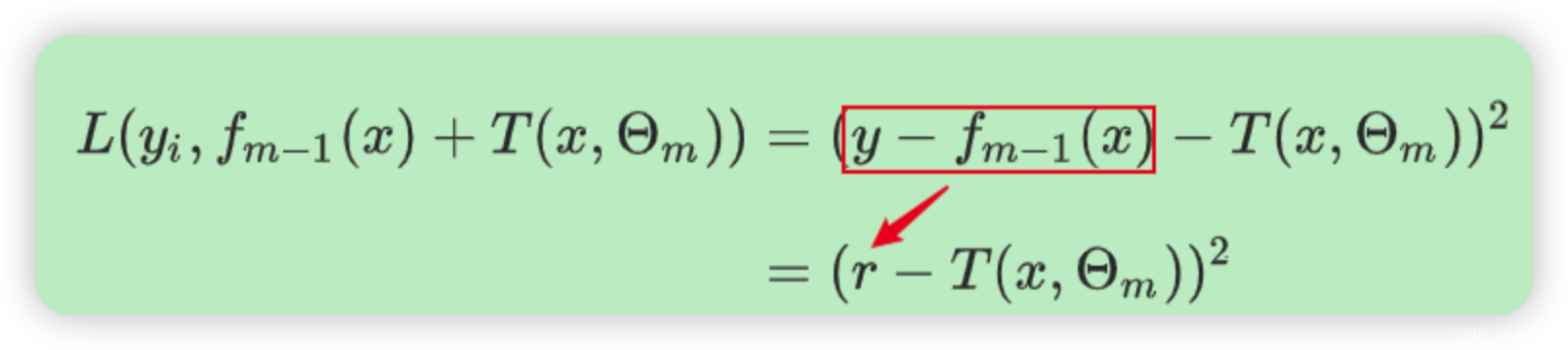
何以梯度能够代表残差呢?如果损失函数是平方损失或者指数损失时候,按照拟合残差的原理每一步优化就很直观,但是其他损失函数呢?
损失函数求导:
二分类

损失函数求导过程:
多分类

多分类我们在训练的时候,是针对样本X每个可能的类都训练一个分类回归树。
总之二分类 一棵树,多分类多棵树。


3 面试常见题目
- gbdt如何选择特征?
遍历每一个点,分裂后误差(损失函数)最小的,就是最优的。 原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点。














 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









