







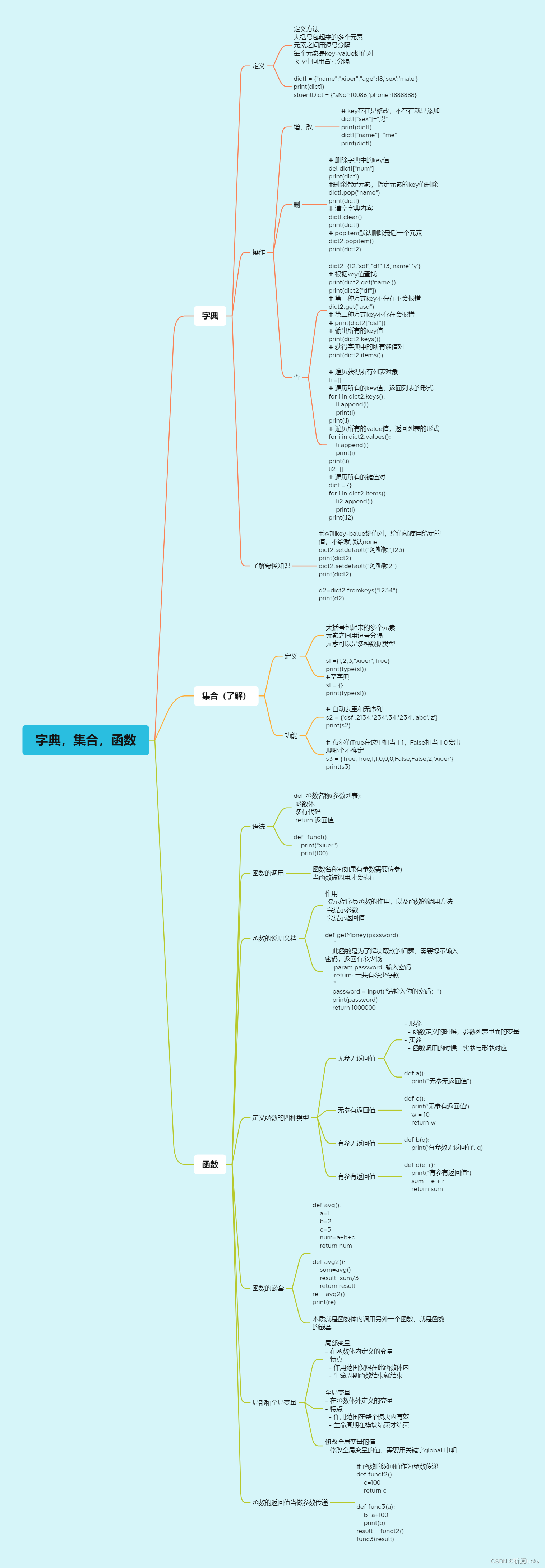
函数
定义
函数的作用?
函数就是将 一段具有独立功能的代码块 整合到一个整体并命名,在需要的位置调用这个名称即可完成对应的需求。
函数在开发过程中,可以更高效的实现代码重用
1,概述
具有特定功能或经常重复使用的代码编写成独立的小单元,并称之为函数。当程序需要时可以任意多次地运行这个函数
2,创建函数
语法:def hello():
print(‘hello,世界’)
3,调用函数
[变量]=函数名称([参数表])
函数使用 步骤
1,定义函数
def 函数名(参数):
代码1
代码2
…
2 调用函数
函数名(参数)
注意:
不同的需求,参数可有可无。
在Python中,函数必须先定义后使用
def sum_num(a, b):
c = a + b
print(c)
sum_num(1, 2)
函数的多种参数
参数,是用来代替一个数地未知数,它们的值是在调用函数地时候定义的,而非在函数本身内赋值。
参数在函数定义的圆括号()内指定,用逗号分割。
函数中的参数名称为形参,而提供给函数调用的值称为实参。
# 定义函数时同时定义了接收用户数据的参数a和b,a和b是形参
def add_num2(a, b):
result = a + b
print(result)
# 调用函数时传入了真实的数据10 和 20,真实数据为实参
add_num2(10, 20)
1,位置参数
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20, '男')
注意:传递和定义参数的顺序及个数必须一致。
2. 关键字参数
函数调用,通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('Rose', age=20, gender='女')
user_info('小明', gender='男', age=16)
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
3,默认参数
定义函数时,通过“name”=“value”的形式定义默认参数。在python调用函数时按照从左向右来进行匹配,所以在调用函数时,一般将默认参数放在后面。
例:def hello(a,b=3)
其中b=3就是默认参数
4,不定长参数
就是传入的参数个数是可变的,可以是1个,两个到任意个甚至可以是0个。python在创建函数时可以让函数不预先设定参数个数,方法是在参数名称加型号*。
语法:函数名称(*参数):
……
例如、def calc(*nums):
……
def user_info(*args):
print(args)
# ('TOM',)
user_info('TOM')
# ('TOM', 18)
user_info('TOM', 18)
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是包裹位置传递。
④参数
可变参数允许传入0个或任意个参数。这些可变参数在函数调用时则自动组装为一个tuple。关键字参数允许传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
语法:def person(a,b,**kw)
……
def func(a,b,c=0,*args,**kw):
print('a=',a,'b=',b,'c=',c,'args=',args,'kw=',kw)
func(1,2)
func(1,2,c=3)
func(1,2,3,'a','b')
func(1,2,3,'a','b',x=99,name='me')
结果:
a= 1 b= 2 c= 0 args= () kw= {}
a= 1 b= 2 c= 3 args= () kw= {}
a= 1 b= 2 c= 3 args= ('a', 'b') kw= {}
a= 1 b= 2 c= 3 args= ('a', 'b') kw= {'x': 99, 'name': 'me'}
可变和不可变类型
所谓可变类型与不可变类型是指:如果数据能够直接进行修改就是可变类型,否则是不可变.
可变类型
列表
字典
集合
不可变类型
整型
浮点型
字符串
元组
匿名函数
不再使用def语句这样的标准的形式定义一个函数。python使用lambda来创建匿名函数。
1,特点如下:
(1)lambda只是一个表达式,函数体比def简单很多
(2)lambda的主体只是一个表达式,而不是一个代码块,仅仅能在lambda表达式中封装有限的逻辑进去
(3)lambda函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数
(4)虽然lambda函数看起来只能写一行,却不同于c或C++的内联函数,后者的目的是调用小函数是不占用栈内存从而增加运行速率
2,lambda函数的语法:
# 无参有返回值
def fun2():
return 100
func2 = lambda: print(100)
func2()
# 有参无返回值,lambda后面可以写输出参数
def fun4(b):
print(100)
func4 = lambda b: print(b)
func4(2)
# 有参有返回值
def fun5(a, b):
print(a, b)
return a + b
func5 = lambda a, b: a + b
print(func5(1, 2))
func6 = lambda li:[i for i in li if i %2==0]
print(func6(li=[34, 34, 45, 65]))
#用法二:将lambda当一个变量
def test(a,b,func):
result = func(a,b)
return result
num = test(11,22,lambda x,y:x+y)
print(num)
2,匿名函数优点:
(1)使用python写一些脚本的时候,利用lambda可以省去定义函数的过程让代码更精简
(2)对于一些抽象的,不会被别的地方在重复使用的函数,使用lambda则不需要考虑命名的问题
(3)在某些时候使用lambda,代码更容易理解
高阶函数
变量可以指向函数,函数的参数也可以接收变量,同时函数也可以接收另一个函数作为参数,那么这种函数就称为高阶函数
定义一个函数接收参数,如果参数中有一个为1函数,那么则个函数就是一个高阶函数
1,map函数
map()函数接收两个参数,一个是函数,一个是序列。map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回
def f(x):
return x*x
r=map(f , [1,2,3,4,4,5,6,6,7,98])
print(list(r))
#结果:
[1, 4, 9, 16, 16, 25, 36, 36, 49, 9604]
2,reduce函数
reduce是把一个函数作用在一个序列[x1,x2,x3,……]上,而这个函数则必须接收两个参数,最后reduce把结果继续和序列的下一个元素左累积计算
语法为:reduce(f,[x1,x2,x3,x4])=f(f(f(x1,x2),x3),x4)
from functools import reduce
def fn(x,y):
return x*10+y #输出原数,若为x+y就输出每个数相加的结果
def char2num(s):
digits={'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}#定义一个字典让字符串0等于整形0
return digits[s]
print(reduce(fn,map(char2num,'1092')))
print(type(reduce(fn,map(char2num,'1092'))))
#结果为:
1092
<class 'int'>
3,filter函数
也接收一个函数和一个list,不同的是该函数f的作用是对每个元素进行判断,返回True或False,filter()根据判度胺结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list
def is_odd(n):
return n%2==0
print(list(filter(is_odd,[1,2,3,4,5,6,76,7,8])))
#结果为
[2, 4, 6, 76, 8]
4,sorted函数
sorted()函数是对所有可以迭代的对象进行排序操作的函数
语法:sorted(iterable[,cmp[,key[,reverse]]])
(1)iterable --可迭代对象
(2)cmp 比较函数。该函数具有两个参数,其参数的值都是从可迭代对象中取出.同时,此函数必须遵守的规则为:大于则返回1;小于则返回-1;等于则返回0。
(3)key 主要是用来进行比较的元素,它只有一个参数,而具体的函数的参数是取自于可迭代对象中,即指定可迭代对象中的一个元素来进行排序。
(4)reverse 排序规则,reverse=True是为降序,reverse==False时为升序
print(sorted([13,2324,23,45325,435],key=abs))
print(sorted(['asdf','asdsd','sdwer'],key=str.lower))
#结果为
[13, 23, 435, 2324, 45325]
['asdf', 'asdsd', 'sdwer']
5,偏函数
int()函数可以把字符串转换为整数,它提供了一个base参数,其默认值为10.如果将base的参数值设为n,那么就可以左n进制的转换
int(‘12345’,base=8)
结果为5349
6,递归函数
在函数内部,我们可以调用其他函数。如果一个函数在内部调用自己本身,那么,这个函数就称为递归函数。
在使用递归函数时,需要注意以下两点:
(1)递归就是在过程或函数里调用自身
(2)必须有一个明确的递归结束条件,即递归出口
def foo(n):
if n>0:
return n+foo(n-1)
else:
return 0
print(foo(100))
#结果:5050
优点:
(1)递归代码看起来更加简洁
(2)可以用递归将复杂任务分解成更简单的子问题
(3)使用递归比使用一些嵌套迭代更容易
缺点:
(1)递归的逻辑很难调试,跟进;
(2)递归调用的代价高昂(效率低),因为该函数占用了大量的内存和时间
文件操作
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name, mode)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
打开文件的模式
模式 描述
r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+ 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
读写文件
# 第一步打开文件,如果文件不存在会或者创建文件w是写,a是追加
file = open('b.txt','w',encoding='utf-8')
# 进行读写操作
file.write('你好')
file.write('\n滴滴起步')
# 读写完成后需要关闭
file.close()
2,读取文件的步骤与方法
# 以绝对路径或相对路径的方式打开文件夹下的文件,设置为r,(前面需要加r,不然直接使用斜杠会报错,可以使用两个斜杠转义)
# 也可以直接使用反斜杠代替,一个反斜杠相当于两个斜杠
file = open(r'D:\pythonLearnSoftware\PythonProject\classLearn_day05\a.txt','r',encoding='utf-8')
# 读入4个字符
data = file.read(4)
print(data)
# 读取之后光标会移动,再读取这一行前面的内容已经读取过了就只能通过光标移动往后读取后面的内容
data2 = file.readline()
print(data2)
# 读取整个文件的数据
data3 = file.readlines()
print(data3)
file.close()
文件备份
1,步骤
①接收用户输入的文件名
②规划备份文件名
③备份文件写入数据
2,规划备份文件名
提取目标文件后缀
组织备份的文件名,xx[备份]后缀
index = old_name.rfind('.')
# print(index) # 后缀中.的下标
# print(old_name[:index]) # 源文件名(无后缀)
# 2.2 组织新文件名 旧文件名 + [备份] + 后缀
new_name = old_name[:index] + '[备份]' + old_name[index:]
# 打印新文件名(带后缀)
# print(new_name)
backFileName = inputFIleName[:inputFIleName.rindex('.')]+'_bak'+inputFIleName[inputFIleName.rindex('.'):]
备份文件示例:
inputFIleName = input("请输入要备份的文件名称")
print(inputFIleName)
backFileName = inputFIleName[:inputFIleName.rindex('.')]+'_bak'+inputFIleName[inputFIleName.rindex('.'):]
print(backFileName)
# 之前一直错误的原因是将要读取文件的名字和要写入文件的名字写反了
readFile = open(inputFIleName,'r',encoding='utf-8')
writeFIle = open(backFileName,'w',encoding='utf-8')
# data = readFile.readlines()
# print(data)
# writeFIle.write(data)
while True:
data = readFile.readline()
# 如果没有数据就退出循环
if len(data) == 0:
break
# 6- 写数据
writeFIle.write(data)
readFile.close()
writeFIle.close()
















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











