







前两个算法都比较容易理解,这章的内容开始有点晦涩了,引入了一些新鲜的概念。且看下面的解说
特点:
计算复杂度不高、输出结果易于理解、对中间值的缺失不敏感、可以处理不相关特征数据、适用数据类型是数值型和标称值型数据(离散数据)、可能会产生过度匹配问题
原理:
在给定的数据集上,可以根据不同的特征值对数据集进行重新划分为不包含该特征的子集,其中能够找到一个最好的特征对数据集进行划分,每个字数据集对应了决策树中的一个分支。如果一个分支上的数据集对应的数据属于同一个类型,则该分支结束,无需对该子数据集进一步划分。如果一个分支上的数据集不属于同一个类型,则需要迭代划分数据集的过程,知道所有具有相同类型的数据均在一个数据子集内。
划分数据集的最大原则就是讲无序的数据变得更加有序。如何来判断数据变得更加有序呢?需要引入以下几个新概念了。
概念:
信息:如果待分类的信息可能分在n个分类中,则第i个分类的信息定义为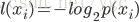
熵(香农熵):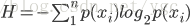
信息增益:划分数据集之前之后信息发生的变化称为信息增益。在这里主要是通过划分前和划分后的熵来进行度量。划分前的熵是该信息集的香农熵,,通过上面的熵公式计算,表示为H。划分后的熵等于划分后每个信息自己的香农熵*选择每个信息子集的概率的和。例如如果以一个特征对信息集进行划分,特征的一个取值将信息集划分为不包含该特征的一个子集,特征有m个取值,则会将信息集划分为m个不包含该特征的子集,选择每个子集的概率p(sj),每个子集的香农熵(H(sj)。信息增益表示为I,则划分信息子集的信息增益公式为
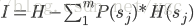
原理中所说的“划分数据集的最大原则就是讲无序的数据变得更加有序”就是用不同的特征来划分数据集,找一个信息增益最大的划分特征作为最终划分数据集的特征
伪代码:
创建决策树模型伪代码
创建树(数据集)
如果数据集中只包含一种分类类别
返回该类别
如果数据集中没有特征值了
返回数据集中类别数量最多的类别
寻找数据集中最佳的划分子集的特征
将该特征名作为树节点
遍历该特征的每种特征值
以当前的特征值划分子集
以子集为参数递归调用创建树()方法
将递归调用的结果作为树节点的一个分支
寻找数据集的最佳划分返回树
寻找最佳划分特征(数据集)
计算数据集的熵
遍历数据集每个特征
计算当前特征的取值域
遍历当前特征的取值域
根据当前值划分子集
累加划分该子集的概率和该自己的熵的乘积
该特征划分信息增益=数据集的熵-累加结果
比较每个特征信息增益,记录最大的信息增益和特征编号
划分数据子集返回最好特征编号
划分数据子集(数据集,特征编号,特征值)
遍历数据集
如果数据向量中划分特征的值=特征值
从向量中取不包含该特征的子向量作为子集的一个向量
返回子集














 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









