







什么是pandas?
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
为什么要学习pandas
那么问题来了:numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据
比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等
所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据.
pandas的常用数据类型
Series 一维,带标签数组

从ndarray创建一个系列
如果数据是ndarray,则传递的索引必须具有相同的长度。 如果没有传递索引值,那么默认的索引将是范围(n),其中n是数组长度,即[0,1,2,3…. range(len(array))-1] - 1]。
案例1:
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])##numpy中的数组对象
s = pd.Series(data)
print s
运行结果:
0 a
1 b
2 c
3 d
dtype: object
【注】这里没有指定索引名,于是默认。
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
print s
运行结果:
案例2:
100 a
101 b
102 c
103 d
dtype: object
[注]这里传递了索引名
从字典创建一个系列
字典(dict)可以作为输入传递,如果没有指定索引,则按排序顺序取得字典键以构造索引。 如果传递了索引,索引中与标签对应的数据中的值将被拉出。
示例1
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print s
Python
执行上面示例代码,输出结果如下 -
a 0.0
b 1.0
c 2.0
dtype: float64
注意 - 字典键用于构建索引。dType我可以自己指定类型
示例2
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print s
执行上面示例代码,输出结果如下 -
b 1.0
c 2.0
d NaN##索引对应的键如果没有,用NAN填充
a 0.0
dtype: float64
从具有位置的系列中访问数据
系列中的数据可以使用类似于访问ndarray中的数据来访问。
示例1:
检索第一个元素。比如已经知道数组从零开始计数,第一个元素存储在零位置等等。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the first element
print s[0]
执行上面示例,得到以下结果 -
1
示例2
检索系列中的前三个元素。 如果a:被插入到其前面,则将从该索引向前的所有项目被提取。 如果使用两个参数(使用它们之间),两个索引之间的项目(不包括停止索引)。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the first three element
print s[:3]
执行上面示例,得到以下结果 -
a 1
b 2
c 3
dtype: int64
示例3
检索最后三个元素,参考以下示例代码 -
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the last three element
print s[-3:]
执行上面示例代码,得到以下结果 -
c 3
d 4
e 5
dtype: int64
使用标签检索数据(索引)
一个系列就像一个固定大小的字典,可以通过索引标签获取和设置值。
示例1
使用索引标签值检索单个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve a single element
print s['a']
执行上面示例代码,得到以下结果 -
1
示例2
使用索引标签值列表检索多个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve multiple elements
print s[['a','c','d']]
Python
执行上面示例代码,得到以下结果 -
a 1
c 3
d 4
dtype: int64
示例3
如果不包含标签,则会出现异常。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve multiple elements
print s['f']
执行上面示例代码,得到以下结果 -
…
KeyError: 'f'
pandas之Series切片和索引

pandas之Series的索引和值

pandas之读取外部数据
现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?
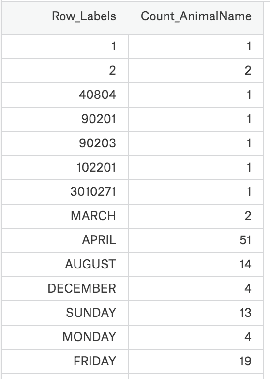

【注】我这利用了布尔索引筛选了一些数据,只统计次数800-1000的。很明显,这不再试series了,而是一种新的数据结构,也就是接下来要介绍的DataFrame!
DataFrame 二维,Series容器
pandas之DataFrame

DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1

[注]上图可以看到dataframe里面要传的参数有哪些!

和一个ndarray一样,我们通过shape,ndim,dtype了解这个ndarray的基本信息,那么对于DataFrame我们有什么方法了解呢

从列表创建DataFrame
实例-1
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
执行上面示例代码,得到以下结果 -
0
0 1
1 2
2 3
3 4
4 5
实例-2
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print df
执行上面示例代码,得到以下结果 -
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13
实例-3
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print df
执行上面示例代码,得到以下结果 -
Name Age
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0
注意 - 可以观察到,dtype参数将Age列的类型更改为浮点。
从ndarrays/Lists的字典来创建DataFrame
所有的ndarrays必须具有相同的长度。如果传递了索引(index),则索引的长度应等于数组的长度。
如果没有传递索引,则默认情况下,索引将为range(n),其中n为数组长度。
实例-1
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print df
执行上面示例代码,得到以下结果 -
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 Ricky
注 - 观察值0,1,2,3。它们是分配给每个使用函数range(n)的默认索引。
示例-2
使用数组创建一个索引的数据帧(DataFrame)。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print df
执行上面示例代码,得到以下结果 -
Age Name
rank1 28 Tom
rank2 34 Jack
rank3 29 Steve
rank4 42 Ricky
注意 - index参数为每行分配一个索引,colmun是列。
从列表创建数据帧DataFrame
字典列表可作为输入数据传递以用来创建数据帧(DataFrame),字典键默认为列名。
实例-1
以下示例显示如何通过传递字典列表来创建数据帧(DataFrame)。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print df
执行上面示例代码,得到以下结果 -
a b c
0 1 2 NaN
1 5 10 20.0
注意 - 观察到,NaN(不是数字)被附加在缺失的区域。
示例-2
以下示例显示如何通过传递字典列表和行索引来创建数据帧(DataFrame)。
import pandas as pd
##相当于制定了列索引a,b,c
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data, index=['first', 'second'])
print df
执行上面示例代码,得到以下结果 -
a b c
first 1 2 NaN
second 5 10 20.0
实例-3
以下示例显示如何使用字典,行索引和列索引列表创建数据帧(DataFrame)。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
#With two column indices, values same as dictionary keys
##重新制定列索引名,就可以干掉上面的c
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
#With two column indices with one index with other name
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print df1
print df2
执行上面示例代码,得到以下结果 -
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
注意 - 观察,df2使用字典键以外的列索引创建DataFrame; 因此,附加了NaN到位置上。 而df1是使用列索引创建的,与字典键相同,所以也附加了NaN。
从系列的字典来创建DataFrame
字典的系列可以传递以形成一个DataFrame。 所得到的索引是通过的所有系列索引的并集。
示例
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df
`
执行上面示例代码,得到以下结果 -
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
注意 - 对于第一个系列,观察到没有传递标签'd',但在结果中,对于d标签,附加了NaN。
列选择
下面将通过从数据帧(DataFrame)中选择一列。
示例
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df ['one']
执行上面示例代码,得到以下结果 -
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
列添加
下面将通过向现有数据框添加一个新列来理解这一点。
示例
i
mport pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
# Adding a new column to an existing DataFrame object with column label by passing new series
print ("Adding a new column by passing as Series:")
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print df
print ("Adding a new column using the existing columns in DataFrame:")
df['four']=df['one']+df['three']
print df
执行上面示例代码,得到以下结果 -
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
Shell
列删除
列可以删除或弹出; 看看下面的例子来了解一下。
例子
# Using the previous DataFrame, we will delete a column
# using del function
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print df
# using del function
print ("Deleting the first column using DEL function:")
del df['one']
print df
# using pop function
print ("Deleting another column using POP function:")
df.pop('two')
print df
Python
执行上面示例代码,得到以下结果 -
Our dataframe is:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
Deleting the first column using DEL function:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
Deleting another column using POP function:
three
a 10.0
b 20.0
c 30.0
d NaN
Shell
行选择,添加和删除
现在将通过下面实例来了解行选择,添加和删除。我们从选择的概念开始。
标签选择
可以通过将行标签传递给loc()函数来选择行。参考以下示例代码 -
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.loc['b']
Python
执行上面示例代码,得到以下结果 -
one 2.0
two 2.0
Name: b, dtype: float64
Shell
结果是一系列标签作为DataFrame的列名称。 而且,系列的名称是检索的标签。
按整数位置选择
可以通过将整数位置传递给iloc()函数来选择行。参考以下示例代码 -
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.iloc[2]
Python
执行上面示例代码,得到以下结果 -
one 3.0
two 3.0
Name: c, dtype: float64
Shell
行切片
可以使用:运算符选择多行。参考以下示例代码 -
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df[2:4]
Python
执行上面示例代码,得到以下结果 -
one two
c 3.0 3
d NaN 4
Shell
附加行
使用append()函数将新行添加到DataFrame。 此功能将附加行结束。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print df
Python
执行上面示例代码,得到以下结果 -
a b
0 1 2
1 3 4
0 5 6
1 7 8
Shell
删除行
使用索引标签从DataFrame中删除或删除行。 如果标签重复,则会删除多行。
如果有注意,在上述示例中,有标签是重复的。这里再多放一个标签,看看有多少行被删除。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
# Drop rows with label 0
df = df.drop(0)
print df
Python
执行上面示例代码,得到以下结果 -
a b
1 3 4
1 7 8
Shell
在上面的例子中,一共有两行被删除,因为这两行包含相同的标签0。
pandas案例
从mongodb提取豆瓣信息
from pymongo import MongoClient
import pandas as pd
##与mongo建立连接
client = MongoClient()
##链接mongo的douban库的tv1集合
collection = client["douban"]["tv1"]
data = collection.find()##取出一条条文档,这里的文档就是一大条json字符串!!
data_list = []
for i in data:
temp = {}
temp["info"]= i["info"]
##下面的这句语句i[][]表示的意思是取该json字符串中rating对应的value,然后再从value中取count对应的value!!
temp["rating_count"] = i["rating"]["count"]
temp["rating_value"] = i["rating"]["value"]
temp["title"] = i["title"]
temp["country"] = i["tv_category"]
temp["directors"] = i["directors"]
temp["actors"] = i['actors']
data_list.append(temp)
# t1 = data[0]
# t1 = pd.Series(t1)
# print(t1)
df = pd.DataFrame(data_list)
# print(df)
#显示头几行
print(df.head(1))
# print("*"*100)
# print(df.tail(2))
#展示df的概览
# print(df.info())
# print(df.describe())
print(df["info"].str.split("/").tolist())
对狗的名字出现的次数排序
import pandas as pd
df = pd.read_csv("./dogNames2.csv")
# print(df.head())
# print(df.info())
#dataFrame中排序的方法
df = df.sort_values(by="Count_AnimalName",ascending=False)
# print(df.head(5))
#pandas取行或者列的注意点
# - 方括号写数组,表示取行,对行进行操作
# - 写字符串,表示的去列索引,对列进行操作
print(df[:20])
print(df["Row_Labels"])
print(type(df["Row_Labels"]))














 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









