







看网上很多人都说,Hadoop 1.x和 2.x的区别,可能就是版本稳定性的区别。因为1.x版本的不会再更新和修复Bug了。但是 2.x 的兴起,就意味着抛弃很多老版的东西。
1.下载2.7.1版本的Hadoop发行版
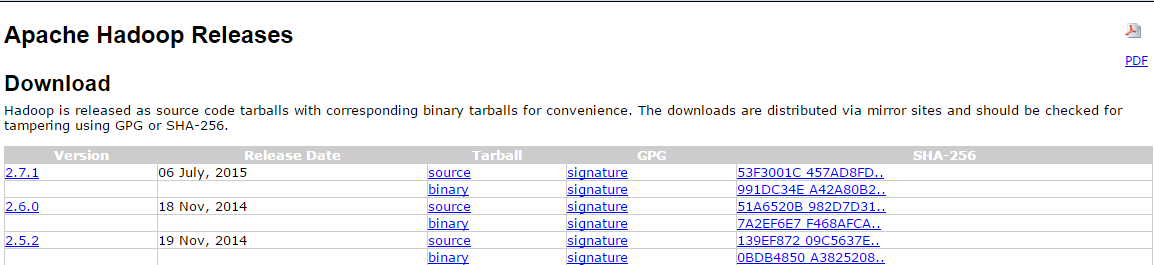
点开以后,就有两种方法来下载安装包了,一个在centos中使用" wget " 命令,一个就是在windows中使用winSCP软件实现与centos的文件传输。

2.配置Hadoop环境变量
3.配置 Hadoop-env.h文件
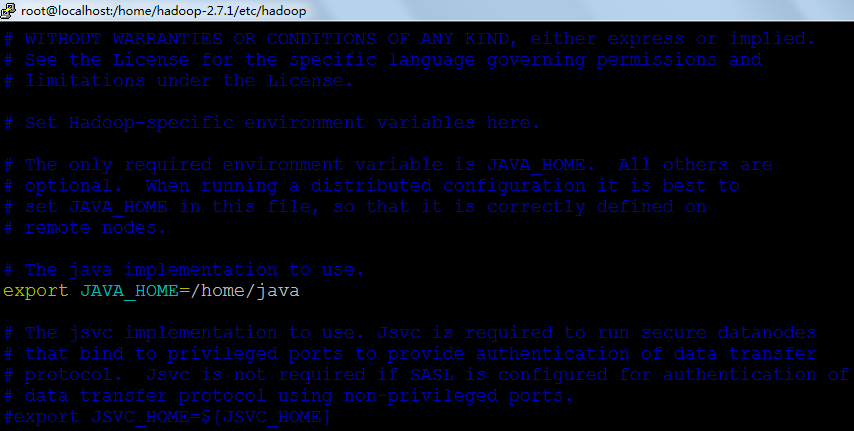
4.安装hadoop并且配置文件
<span style="font-family:Microsoft YaHei;font-size:12px;">在etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration></span>上述配置说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于fs.defaultFS目录的,比如namenode的名字空间存放地方就是 ${fs.defaultFS}/dfs/name,datanode数据块的存放地方就是${fs.defaultFS}/dfs/data,所以设置好fs.defaultFS目录后,其他的重要目录都是在这个目录下面,这是一个根目录。
在etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>说明:这里的dfs.replication的value为1是因为我们这里配置的是单机伪分布式,只有一台机子 。
5.启动hadoop
[root@localhost hadoop-2.7.1]# cd sbin
[root@localhost sbin]# hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
15/07/12 02:22:44 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost.localdomain/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.1
STARTUP_MSG: java = 1.7.0_79
************************************************************/
中间省略若干。。。。
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.1
************************************************************/
[root@localhost sbin]# ./start-dfs.sh
15/07/12 02:26:17 WARN util.NativeCodeLoader: Unable to load native-hadoop libra using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop-2.7.1/logs/hadoop-root-nammain.out
localhost: starting datanode, logging to /home/hadoop-2.7.1/logs/hadoop-root-datmain.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop-2.7.1/logs/hadoop-rocalhost.localdomain.out
15/07/12 02:26:45 WARN util.NativeCodeLoader: Unable to load native-hadoop libra using builtin-java classes where applicable
[root@localhost sbin]# jps
2957 NameNode
3341 Jps
3224 SecondaryNameNode
<span style="color:#555555;">2015-07-12 02:30:11,369 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting
2015-07-12 02:30:11,373 INFO org.apache.hadoop.ipc.Server: IPC Server listener on 50020: starting
2015-07-12 02:30:12,345 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /tmp/hadoop-ro
</span><span style="color:#ff6666;">2015-07-12 02:30:12,348 WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: I = CID-bedad193-15c3-42cc-8f1f-2888abfcbe93; datanode clusterID = CID-92e43622-3107-4382-b360-4ef</span><span style="color:#555555;">
2015-07-12 02:30:12,359 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failocalhost/127.0.0.1:9000. Exiting.
java.io.IOException: All specified directories are failed to load.
</span>从日志中可以看出,原因是因为datanode的clusterID 和 namenode的clusterID 不匹配。解决方法:打开hdfs-site.xml文件配置的datanode和namenode对应的目录,在tmp/hadoop-root/dfs目录下分别打开data和name目录下current文件夹里的VERSION,可以看到clusterID项正如日志里记录的一样,确实不一致,修改datanode里VERSION文件的clusterID 与namenode里的一致,再重新启动dfs(执行start-dfs.sh)再执行jps命令,可以看到datanode已正常启动。出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。下面就是正确启动了hadoop伪分布式集群~
[root@localhost bin]# hdfs |grep format
namenode -format format the DFS filesystem
[root@localhost bin]# ls
container-executor hadoop hadoop.cmd hdfs hdfs.cmd mapred mapred.cmd rcc test-container-e
[root@localhost bin]# jps
4558 SecondaryNameNode
7215 Jps
4284 NameNode
4379 DataNode
6.使用hadoop命令(具体的还是看hadoop官网的File System Shell Guide)
[root@localhost ~]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]<span style="line-height: 35px; font-family: Arial, Helvetica, sans-serif; font-size: 12px; background-color: rgb(255, 255, 255);"> </span>















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









