







作为全文检索的的工具包——Lucene,自诞生后就备受瞩目。但由于版本更新较快,新版本稳定不佳,因此我还是选择4.3.x系列的稳定版本作为练习之用。索引创建和索引检索的代码如下所示:
一、首先工程得导入lucene依赖的各个jar包,以免报错。
二、索引创建
package com.test.lucene;
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* Filename: IndexCreat.java
* Copyright: Copyright (c)2010
* Company: com
* @version: 1.0
* @since: JDK 1.6.0_21
* Create at: 2016年6月3日 上午12:04:10
* Description: Create Index
*
* Modification History:
* Date Author Version Description
* -----------------------------------------------------------------
* 2016年6月3日 Kevin-YE 1.0 1.0 Version
**/
public class IndexCreat {
public static void main(String[] args) {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43); //standard Analyzer
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_43, analyzer);
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);//set index open mode
Directory directory = null; //Index storage
IndexWriter indexWriter = null;
try {
directory = FSDirectory.open(new File("F://index/Test"));
if(indexWriter.isLocked(directory)){
indexWriter.unlock(directory);
}
indexWriter = new IndexWriter(directory, indexWriterConfig);
}catch(Exception e) {
e.printStackTrace();
}
Document doc1 = new Document();
doc1.add(new StringField("id", "akfjjf", Store.YES ));
doc1.add(new TextField("content", "普天同庆", Store.YES ));
doc1.add(new IntField("num", 1, Store.YES));
try {
indexWriter.addDocument(doc1);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Document doc2 = new Document();
doc2.add(new StringField("id", "", Store.YES ));
doc2.add(new TextField("content", "阳光普照", Store.YES ));
doc2.add(new IntField("num", 2, Store.YES));
try {<span style="white-space:pre"> </span>//close resource
indexWriter.commit();
indexWriter.close();
directory.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
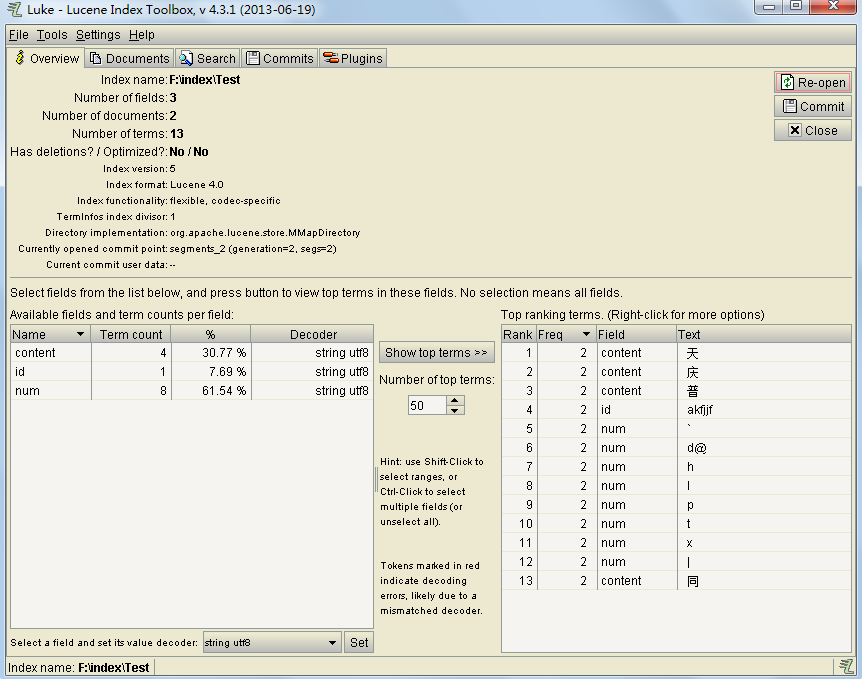
}索引创建成功后,可在F盘下找到Index/Test目录。在这里,我们使用工具Luke4.3.1进行验证索引是否创建成功。请注意:Luke工具包要和Lucene工具包版本一致,否则会出现"read past eof"的错误。
三、索引检索
package com.test.lucene;
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* Filename: IndexSearch.java
* Copyright: Copyright (c)2010
* Company: com
* @version: 1.0
* @since: JDK 1.6.0_21
* Create at: 2016年6月3日 下午10:38:57
* Description: Index search
*
* Modification History:
* Date Author Version Description
* -----------------------------------------------------------------
* 2016年6月3日 Kevin-Ye 1.0 1.0 Version
**/
public class IndexSearch {
public static void main(String[] args) {
Directory directory = null;
try {
directory = FSDirectory.open(new File("F://Index/Test"));
DirectoryReader dReader = DirectoryReader.open(directory); // read index file
IndexSearcher indexSearcher = new IndexSearcher(dReader); // create index object
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
QueryParser parser = new QueryParser(Version.LUCENE_43, "content",analyzer); //set index query string
Query query = parser.parse("普天同庆");
TopDocs topDocs = indexSearcher.search(query, 10);
if(topDocs != null) {
System.out.println("查询到符合文档总数为:"+ topDocs.totalHits);
for(int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = indexSearcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("id=" + doc.get("id"));
System.out.println("content=" + doc.get("content"));
System.out.println("num=" + doc.get("num"));
}
}//close resource
directory.close();
dReader.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
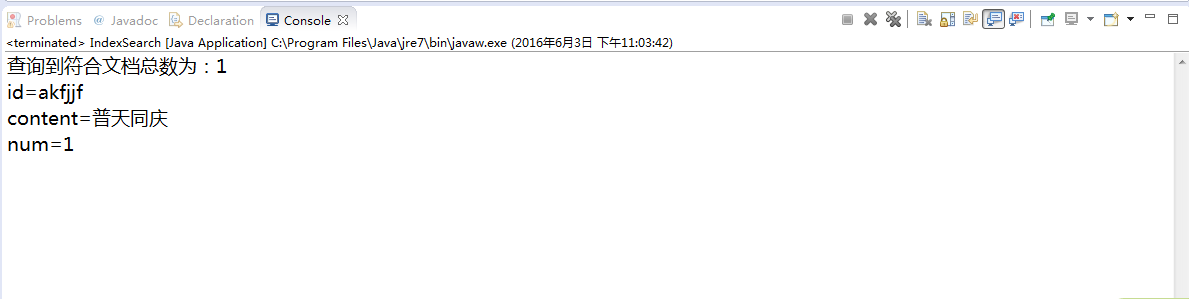
运行结果如下所示:















 8165
8165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









