






参考《Python+Spark 2.0+Hadoop机器学习与大数据实战_林大贵(著) 清华大学出版社》
一、Hadoop集群
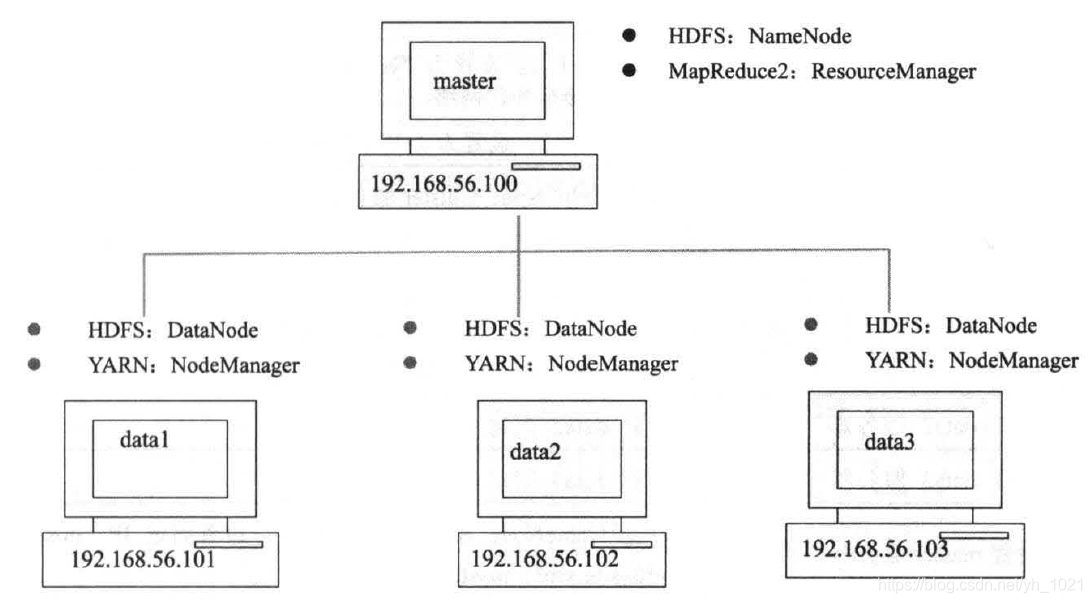
Hadoop集群需要4台服务器才可以建立,可以进行并行处理,所以在虚拟机上创建了master、data1~data3四个服务器。
计算机master在HDFS中作为NameNode,在MapReduce2中作为ResourceManager
计算机data1~data3在HDFS中作为DataNode,在MapReduce2中作为NodeManager
二、Hadoop集群的安装
安装步骤:
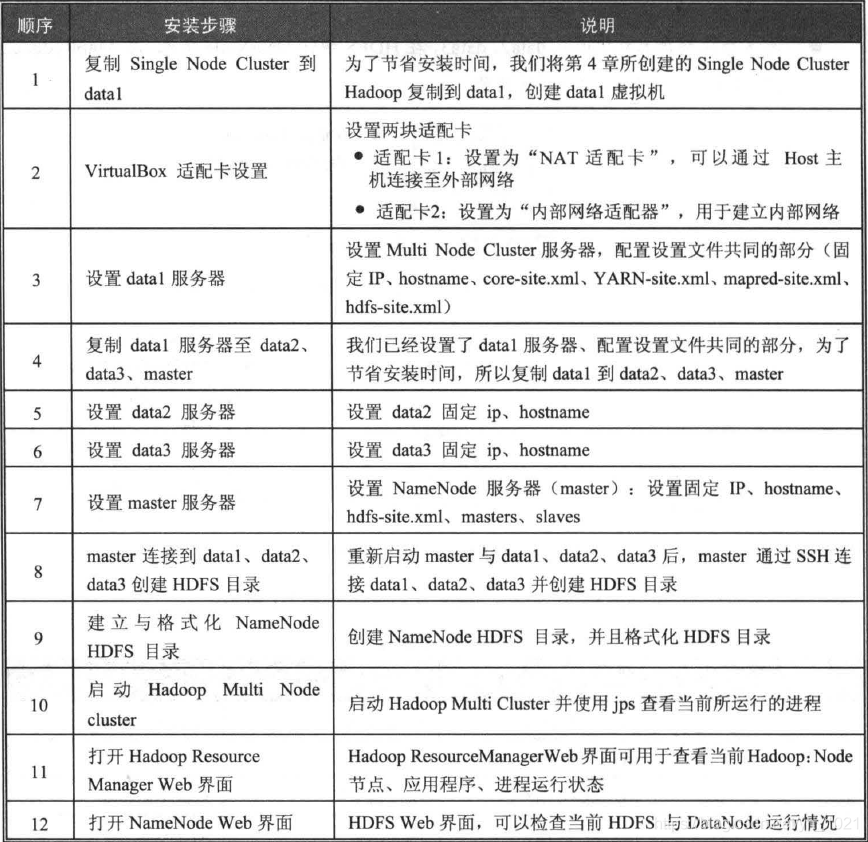
1、复制之前安装的单个Hadoop服务器,创建data1虚拟机
(在virtualBox中直接完全复制即可)
2、在virtualBox中设置data1的网卡
在每一台虚拟主机上设置两个网卡(在virtualBox管理器界面上的设置)
- 网卡1:设置为“NAT网卡”,通过Host主机(windows)连接外部网络
- 网卡2:设置为“仅主机适配器”,创建内部网络,用于连接四个虚拟主机与Host主机
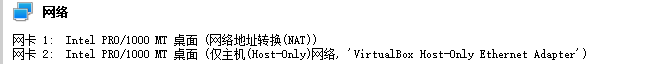
3、设置data1服务器
固定IP、hostname、core-site.xml、YARN-site.xml、mapred-site.xml、hdfs-site.xml
(1)编辑interfaces网络配置文件
每次开机固定IP:192.168.56.101
sudo gedit /etc/network/interfaces
设置网卡1:
设置为“NAT网卡”,通过Host主机连接外部网络,设置为eth0,并设置dhcp自动获得IP地址
设置网卡2:
“仅主机适配器”,建立内部网络。设置为eth1,并设置为static,指定固定IP
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
#NAT interface
auto eth0
iface eth0 inet dhcp
#host only interface
auto eth1
iface eth1 inet static
address 192.168.56.101
netmask 255.255.255.0
network 192.168.56.0
dns-nameservers 192.168.56.1
(2)编辑hostname主机名
sudo gedit /etc/hostname
输入:data1
(3)编辑hosts文件
可以让网络中所有计算机都知道其他计算机的主机名和IP,hosts文件可以储存计算机网络中各节点的信息,负责将主机名映射到对应的IP地址。
sudo gedit /etc/hosts
在文件中设置各节点的主机名与对应的IP
127.0.0.1 localhost
127.0.1.1 hadoop
192.168.0.104 master
192.168.0.101 data1
192.168.0.102 data2
192.168.0.103 data3
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
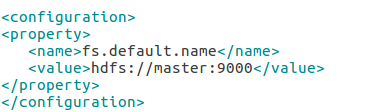
(4)编辑core-site.xml
设置HDFS的默认名称,可使用此名称来存取HDFS
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
localhost改为master,之后可通过hdfs://master:9000存取HDFS
(5)编辑YARN-site.xml
此文件是MapReduce2相关配置
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
文件中输入
ResourceManger主机与NodeManager连接地址为8025
ResourceManger与ApplicationMaster连接地址为8030
ResourceManger与客户端连接地址为8050
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
(6)编辑mapred-site.xml
监控Map与Reduce的JobTracker任务分配情况,以及任务运行情况
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
输入
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
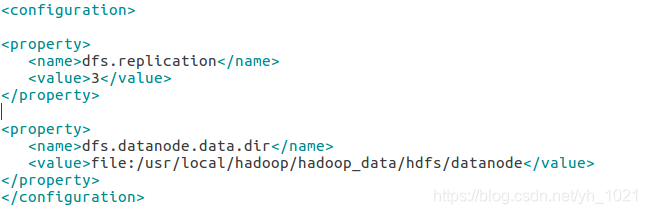
(7)编辑hdfs-site.xml
用于设置HDFS分布式文件系统的配置,data1只是单纯的DataNode,所以删除NameNode设置
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
(8)data1重启
(9)重启后确定网络设置
ifconfig
可以看到有两个网卡,网卡二的内部IP是192.168.56.101
(10)打开网页看外网连接是否正常,并关闭data1
4、复制data2、data3、master
选择虚拟机进行内存设置(主要由Host主机的内存大小决定)
选择虚拟机–>系统–>内存大小
Host为8G时,master:2GB、data1:1GB、data2:1GB、data3:1GB
Host为16G时,master:4GB、data1:2GB、data2:2GB、data3:2GB
5、设置data2、data3、master服务器
(1)设置data2固定IP地址
设置固定IP为:192.168.56.102
sudo gedit /etc/network/interfaces
在address中改为192.168.56.102
(2)编辑hostname文件
改为data2
sudo gedit /etc/hostname
(3)同理修改data3(192.168.56.103)和master(192.168.56.100)
(4)在master中编辑hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
master只是单纯作为NameNode,所以删除DataNode的HDFS设置,并加入NameNode的HDFS设置
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
(5)在master中编辑master文件
用于告诉hadoop系统哪一台服务器是NameNode
sudo gedit /usr/local/hadoop/etc/hadoop/masters
输入:master
(6)在master中编辑slaves文件
用于告诉hadoop系统哪些服务器是DataNode
sudo gedit /usr/local/hadoop/etc/hadoop/slaves
输入
data1
data2
data3
(7)配置好后都可以重启并输入ifconfig查看网络设置
6、master连接data1、data2、data3,创建HDFS目录
创建NameNode(master)的ssh连接到DataNode(data1、data2、data3),并创建HDFS相关目录
(1)启动所有服务器
(2)在master中通过SSH连接到data1服务器
ssh data1
hduser@master变成hduser@data1就是连接成功
(3)创建HDFS目录
删除HDFS所有目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
创建DataNode存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
将目录所有者改为hduser
sudo chown -R hduser:hduser /usr/local/hadoop
退出,回到master
exit
(4)重复步骤3,完成对data2、data3的设置
7、创建并格式化NameNode HDFS目录
(1)重新创建NameNode HDFS目录
删除HDFS所有目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
创建DataNode存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
将目录所有者改为hduser
sudo chown -R hduser:hduser /usr/local/hadoop
(2)格式化NameNode HDFS目录
之前已经创建了NameNode和DataNode的HDFS目录
hadoop namenode -format
8、启动Hadoop Multi Node Cluster
之前完成了Hadoop集群的构建,下面分别启动HDFS和YARN
start-dfs.sh
start-yarn.sh
或者启动全部:
start-all.sh
**注意:**master、data1、data2、data3的秘钥都要相同,如果有改动可以用master中的秘钥进行复制
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或者:PermitEmptyPasswords 参数值修改为yes
sudo gedit /etc/ssh/sshd_config
(1)查看master(namenode)进程(process)
在master中输入jps可以用于查看当前所运行的进程
jps
(2)查看data1(datanode)进程
连接data1虚拟机:ssh data1
查看进程:jps
回到master:exit
(3)打开Hadoop ResourceManager web界面
http://master:8088/
打开NameNode Web界面
http://master:50070/














 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









