






安装计划
| hadoop01 | hadoop02 | hadoop03 | |
| HDFS | namenode+datanode | datanode+secondarynamenode | datanode |
| YARN | nodemanager | nodemanager | nodemanager+resourcemanager |
参考:Hadoop 集群安装_iFulling的博客-CSDN博客_hadoop集群的安装
安装说明
如果没有特殊说明操作过程中使用账号:rd Linux账号普通账号新建与授权_磊杰哟的博客-CSDN博客
准备三台机器:
192.168.1.18(主)----hadoop01
192.168.1.137(从)----hadoop02
192.168.1.248(从)----hadoop03
jdk安装目录:/usr/local/java
hadoop安装目录:/home/rd/soft/hadoop-2.7.6
环境准备
- jdk安装:JDK下载安装-Linux-2022年05月03日_磊杰哟的博客-CSDN博客_jdk下载linux
- 新建账号:Linux账号普通账号新建与授权_磊杰哟的博客-CSDN博客
- 更改主机名查询静态表:
-
hostnamectl set-hostname node1 - 免密登录:Linux免密登录
hadoop安装文件下载
- 官网下载地址:最低版本2.10.* Index of /hadoop/common
- 旧官网下载地址:Index of /dist/hadoop/common
- 百度网盘下载地址:
- 链接:https://pan.baidu.com/s/1vRSQB-zfG8wQX58dX8WxOg 提取码:wucj
修改配置文件
解压安装文件至:/home/rd/soft/hadoop-2.7.6
以下操作首先在其中一台机器上操作,比如现在hadoop01(192.168.1.18)机器上操作,最后统一传输至其他服务器(hadoop02、hadoop03)
HDFS集群配置
YARM集群配置
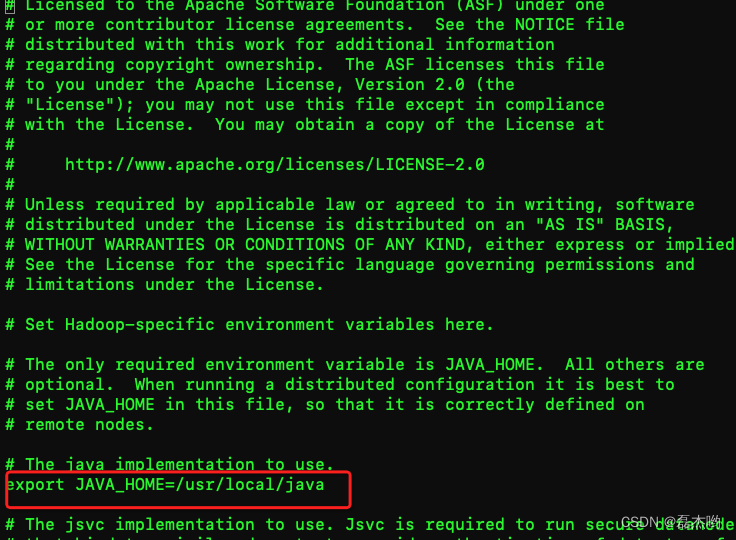
修改 hadoop-env.sh 文件
配置hadoop使用的jdk
cd /home/rd/soft/hadoop-2.7.6/etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME的值为本机的jdk安装根目录
修改 core-site.xml 文件
进入hadoop安装目录,创建临时目录tmp(用于存放数据)
/home/rd/soft/hadoop-2.7.6
mkdir tmp修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
cd /home/rd/soft/hadoop-2.7.6/etc/hadoop
vi core-site.xml
<configuration>
<property>
<!--hadoop hdfs的访问入口 namenode的访问入口-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--hadoop namenode的管理数据的存储位置 namenode所在的节点本地-->
<name>hadoop.tmp.dir</name>
<value>/home/rd/soft/hadoop-2.7.6/tmp</value>
</property>
</configuration>新建并修改mapred-site.xml
cd /home/rd/soft/hadoop-2.7.6/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改mapred-site.xml
cd /home/rd/soft/hadoop-2.7.6/etc/hadoop
vi mapred-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--resourcemanager节点-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
</configuration>新建或修改slaves文件
cd /home/rd/soft/hadoop/etc/hadoop
vi slaves在里面删掉"localhost",加入集群中所有Slave机器的IP,也是每行一个。
192.168.1.18
192.168.1.248
192.168.1.137将文件复制传输至其他服务器
从hadoop01机器将hadoop文件传输至其他服务器
scp -r /home/rd/soft/hadoop-2.7.6 hadoop02:/home/rd/soft
scp -r /home/rd/soft/hadoop-2.7.6 hadoop03:/home/rd/soft
配置hadoop环境变量
- 为了操作方便,切换到root账号修改环境变化;
- 三台机器全部执行环境变量配置操作并且将配置生效;
设置环境变量
vi /etc/profile
最底下追加
export HADOOP_HOME=/home/rd/soft/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
加载生效当前配置
source /etc/profile确认环境变量配置
确认上面配置的环境变量配置的是否正确且已经生效
[rd@5ljzd8ppi2avyaqh ~]$ hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /home/rd/soft/hadoop/share/hadoop/common/hadoop-common-2.7.6.jar
[rd@5ljzd8ppi2avyaqh ~]$ 格式化
登录主机器(hadoop01-192.168.1.18)执行下面的命令
hdfs namenode -format
关闭防火墙
systemctl stop firewalld启动服务
在任意节点启动hdfs
start-dfs.sh
在resourcemanager(hadoop03)节点启动yarn
start-yarn.sh
启动后验证:jps
启动后效果如下

| HDFS | YARN | |
| hadoop01 | namenode+datanode | nodemanager |
| hadoop02 | datanode+secondarynamenode | nodemanager |
| hadoop03 | datanode | nodemanager+resourcemanager |
管控台















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









