






1、模型误差
模型误差=偏差+方差+不可避免的误差
不可避免的误差是数据本身带有的,而偏差和方差是训练模型时造成的
- 欠拟合是造成偏差的主要原因
- 过拟合是造成方差的主要原因,因为模型复杂,数据对模型的扰动很大
- 非参数学习(依赖于数据)算法都是高方差算法,因为对数据不进行任何假设
- 参数学习(例如线性回归)都说是高偏差算法,因为对数据具有极强的假设(认为数据符合这个模型)
一般降低偏差会提高方差,降低方差会提高偏差,最好是能在方差和偏差之间找到平衡。当然一般机器学习最容易产生过拟合问题,也就带来了方差问题,解决高方差的方法: - 1、降低模型复杂度
- 2、减少数据维度,降噪
- 3、增加样本数、数据集
- 4、使用验证集(防止对测试集过拟合)
- 5、模型正则化
2、模型正则化(regularization)
加入模型正则化,目标:使得 J ( θ ) = M S E ( y , y ^ ; θ ) + α 1 2 ∑ i = 1 n θ i 2 J\left ( \theta \right )=MSE\left (y,\hat{y};\theta \right )+\alpha \frac{1}{2}\sum_{i=1}^{n}\theta _{i}^{2} J(θ)=MSE(y,y^;θ)+α21∑i=1nθi2尽可能小。要使加的一项尽可能小,必须让 θ \theta θ(特征的系数)尽可能小,这样也就不会发生过拟合现象。在这里面增加了超参数 α \alpha α,改变 α \alpha α就改变了正则化一项所占的比重。
(1)岭回归(L2正则项)
使用岭回归,采用不同的 α \alpha α值,比较正则化结果
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
x=np.random.uniform(-3.0,3.0,size=100)
x=x.reshape(-1,1)
y=0.5*x+3+(np.random.normal(0.,1.,size=100)).reshape(-1,1)
plt.scatter(x,y)
plt.show()
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def polyregression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("standard",StandardScaler()),
("lin_reg",LinearRegression())
])
from sklearn.model_selection import train_test_split
np.random.seed(666)
x_train,x_test,y_train,y_test =train_test_split(x,y)
from sklearn.metrics import mean_squared_error
poly20_reg=polyregression(degree=20)
poly20_reg.fit(x_train,y_train)
y_predict=poly20_reg.predict(x_test)
error=mean_squared_error(y_predict,y_test)
print(error)
#画出模型中的拟合曲线
def plot_model(model):
x_plot=np.linspace(-3,3,100).reshape(100,1)
y_plot=model.predict(x_plot)
plt.scatter(x,y)
plt.plot(x_plot,y_plot,color='r')
plt.axis([-3,3,0,6])
plt.show()
plot_model(poly20_reg)
#使用岭回归
from sklearn.linear_model import Ridge
from sklearn.pipeline import Pipeline
def ridgeregression(degree,alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("standard", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha)) #alpha值就是正则化那一项的系数
])
#设置alpha=0.001
Ridge_reg=ridgeregression(20,0.001)
Ridge_reg.fit(x_train,y_train)
y_predict=Ridge_reg.predict(x_test)
error2=mean_squared_error(y_test,y_predict)
print(error2)
plot_model(Ridge_reg)
#设置alpha=10
Ridge_reg2=ridgeregression(20,10)
Ridge_reg2.fit(x_train,y_train)
y_predict=Ridge_reg2.predict(x_test)
error3=mean_squared_error(y_test,y_predict)
print(error3)
plot_model(Ridge_reg2)
得到未正则化的结果为:
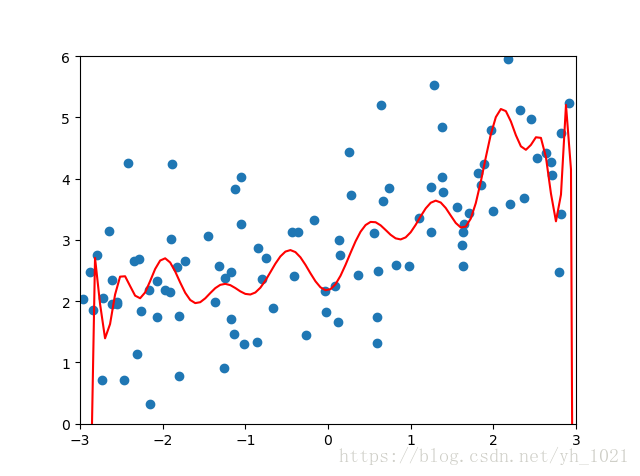
均方误差:167.94010860023363
α
\alpha
α为0.001时的正则化结果为:
均方误差:1.2857689721696126‘
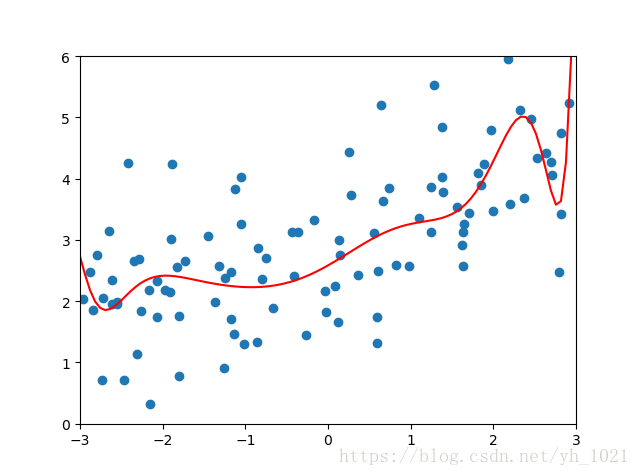
α
\alpha
α为10时的正则化结果为:
均方误差:1.1451272194878863
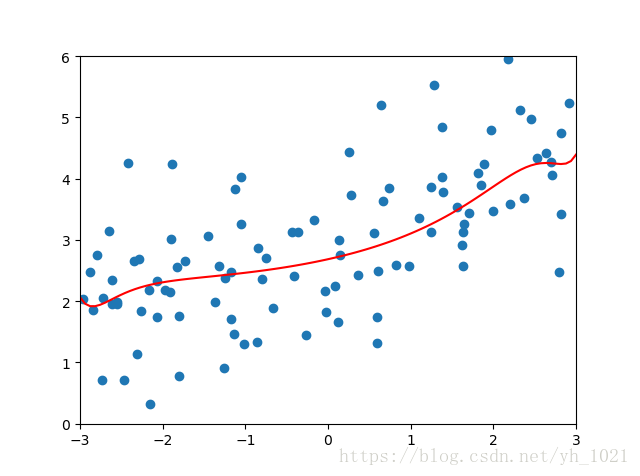
α
\alpha
α为10000时的正则化结果为:
均方误差为:1.7967435583384
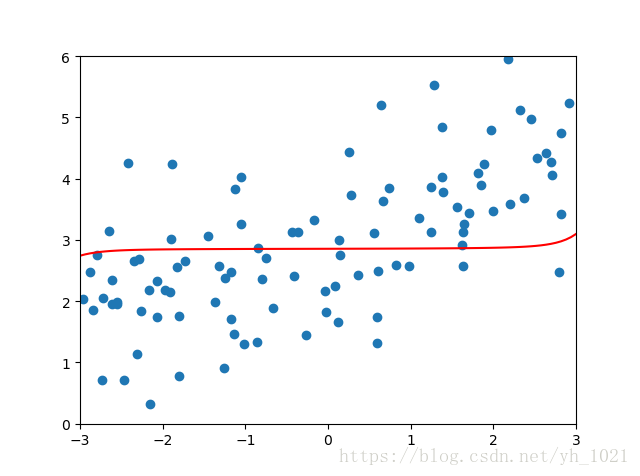
可见当 α \alpha α越大,正则化程度越高,但是当 α \alpha α过大时,正则化项所占比重太大,反而误差会上升。(因为比重太大,要使正则化项最小, θ \theta θ值只能取0,所以为一条直线)
(2)LASSO回归(L1正则项)
目标:使 J ( θ ) = M S E ( y , y ^ ; θ ) + α ∑ i = 1 n ∣ θ i ∣ J\left ( \theta \right )=MSE\left (y,\hat{y};\theta \right )+\alpha\sum_{i=1}^{n}\left |\theta _{i} \right | J(θ)=MSE(y,y^;θ)+α∑i=1n∣θi∣尽可能小
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
x=np.random.uniform(-3.0,3.0,size=100)
x=x.reshape(-1,1)
y=0.5*x+3+(np.random.normal(0.,1.,size=100)).reshape(-1,1)
plt.scatter(x,y)
plt.show()
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def polyregression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("standard",StandardScaler()),
("lin_reg",LinearRegression())
])
from sklearn.model_selection import train_test_split
np.random.seed(666)
x_train,x_test,y_train,y_test =train_test_split(x,y)
from sklearn.metrics import mean_squared_error
poly20_reg=polyregression(degree=20)
poly20_reg.fit(x_train,y_train)
y_predict=poly20_reg.predict(x_test)
error=mean_squared_error(y_predict,y_test)
print(error)
#画出模型中的拟合曲线
def plot_model(model):
x_plot=np.linspace(-3,3,100).reshape(100,1)
y_plot=model.predict(x_plot)
plt.scatter(x,y)
plt.plot(x_plot,y_plot,color='r')
plt.axis([-3,3,0,6])
plt.show()
plot_model(poly20_reg)
#使用LASSO回归
from sklearn.linear_model import Lasso
from sklearn.pipeline import Pipeline
def ridgeregression(degree,alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("standard", StandardScaler()),
("ridge_reg", Lasso(alpha=alpha)) #alpha值就是正则化那一项的系数
])
#设置alpha=0.001
Lasso_reg1=ridgeregression(20,0.01)
Lasso_reg1.fit(x_train,y_train)
y_predict=Lasso_reg1.predict(x_test)
error1=mean_squared_error(y_test,y_predict)
print(error1)
plot_model(Lasso_reg1)
#设置alpha=0.1
Lasso_reg2=ridgeregression(20,0.1)
Lasso_reg2.fit(x_train,y_train)
y_predict=Lasso_reg2.predict(x_test)
error2=mean_squared_error(y_test,y_predict)
print(error2)
plot_model(Lasso_reg2)
#设置alpha=0.1
Lasso_reg3=ridgeregression(20,1)
Lasso_reg3.fit(x_train,y_train)
y_predict=Lasso_reg3.predict(x_test)
error3=mean_squared_error(y_test,y_predict)
print(error3)
plot_model(Lasso_reg3)
当正则化系数
α
\alpha
α为0.01时:
均方误差为:1.149608084325997
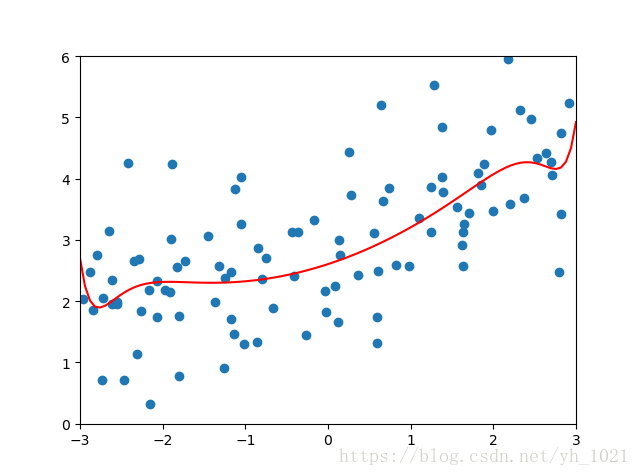
当正则化系数
α
\alpha
α为0.1时:
均方误差为:1.1213911351818648
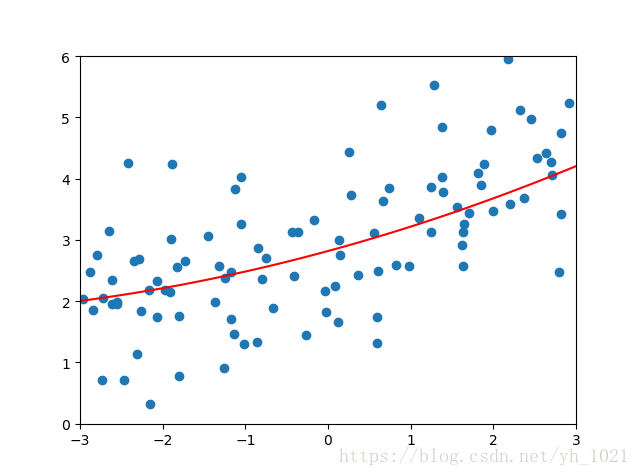
当正则化系数
α
\alpha
α为1时:
均方误差为:1.8408939659515595
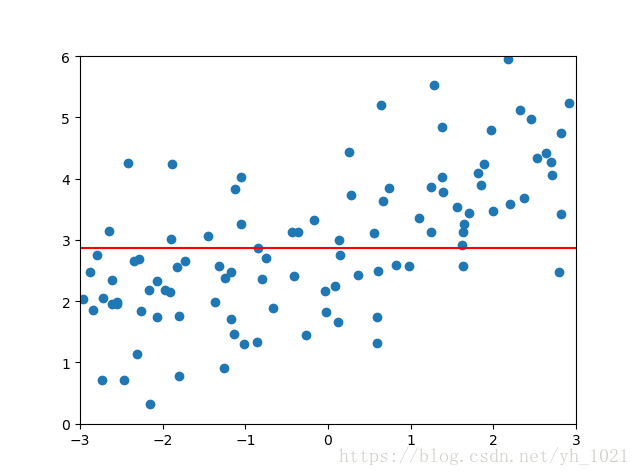
可见LASSO回归和岭回归类似,
α
\alpha
α取值过大反而会导致误差增加,拟合曲线为直线。但是LASSO更趋向于使得一部分的
θ
\theta
θ值为0,拟合曲线更趋向于直线,所以可以作为特征选择来使用,去除一些模型认为不需要的特征。
LASSO可能会去除掉正确的特征,从而降低准确度,但如果特征特别大,使用LASSO可以使模型变小。














 74
74











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









