







multiprocessing.Process的join()方法
通过上篇博文可以看出join()方法具有清除僵尸进程的作用,与此同时带来的负面作用就是子父进程的串行执行(此处假设我们的目标是保证子父进程的执行方式是非阻塞的;对于实际需求是需要父进程阻塞等待子进程结束后在执行的应用场景,可以忽略本篇博文)。接下来将从join的底层实现出发探究其能够清楚僵尸进程的原因和阻塞执行的方式;同时基于一个demo来给出实际工作中如何准确有效的避免和消除僵尸进程。
join初探
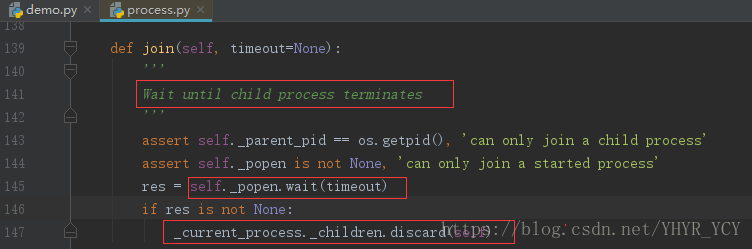
基于PyCharm查看join的源码,如上图所示;官方描述该方法的功能是“等待,直到子进程结束”;从字面意思也不难看出,该方法是一个阻塞方法;需要注意的是这里等待的主语是主进程而非子进程。该方法主要做了两件事:
(1) 通知父进程调用wait方法
(2) 将该子进程从父进程的子进程列表中移除
第一件事调用wait方法背后的实际调用链是:process模块的Process.join() => forking模块的Popen.wait(),实则是调用了os.waitpd方法【注意这里的Popen根据操作系统的不同而不同,分为Unix/Linux和Windows两种】;至于为什么要调用该方法可以看我上篇博文中有关Linux进程基本概念模块的描述。
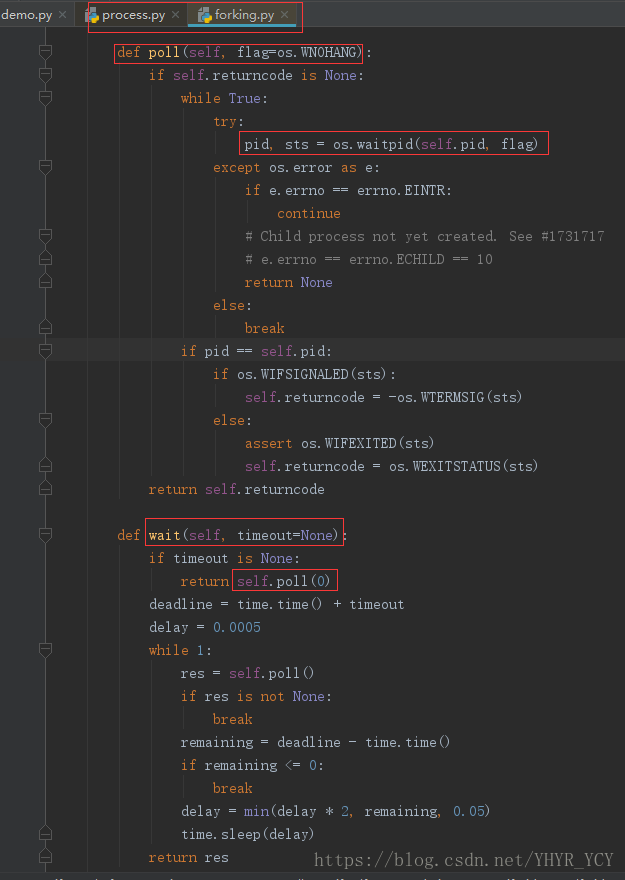
看到这,对于join()能消除僵尸进程的原因应该有了较为深刻的认识了;但是还存在一个问题:进程的串行执行问题还未解决。源码中join有一个timeout的参数,该参数的作用是设置一个该方法调用的等待时间,如果不设置,则等待子进程结束后在执行父进程;如果设置了,当子进程的运行周期大于你所设置的timeout时长时,表示过了timeout时长后(单位是秒),开始唤醒父进程,此时子父进程开始同时执行;如果子进程的运行周期小与你所设置的timeout时长时,当你的子进程结束后会立即执行父进程,而不用等待你所设置的时长结束后才开始唤醒父进程。光说这些理论可能印象不会太深刻,接下来用几组例子来抛砖引玉,在加深对join理解的同时,介绍两种僵尸进程的有效清除办法。
样例代码如下所示
# -*- coding: utf-8 -*-
import multiprocessing
import os
import time
class MainProcess:
def __init__(self, main_process_time, child_process_time):
self.main_process_time = main_process_time
self.child_process_time = child_process_time
def excutor(self):
print('main process begin, pid={0}, ppid={1}'.format(os.getpid(), os.getppid()))
p = ChildProcess(self.child_process_time)
p.start()
p.join(3)
for i in range(self.main_process_time):
print('main process, pid={0}, ppid={1}, times={2}'.format(os.getpid(), os.getppid(), i))
time.sleep(1)
class ChildProcess(multiprocessing.Process):
def __init__(self, process_ti 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









