







一.什么是爬虫
爬虫一般指抓取众多公开网站网页上数据的相关技术,此处不是我们说的无脊椎动物哈,爬虫,其实个人认为就是凭借一些小技巧,去白嫖一些公开的数据,之前一直用的Java,最近接触了python,对爬虫颇有兴趣,也爬取了很多网站的信息,当然我也是python小白,希望通过交流学习一起成长。
二.关键信息 cookies
首先如果要学习了解爬虫,那cookie就是绕不开的,cookies,英文解释是会话,每当提到cookies,那就不得不说网络协议--http协议,http协议本身是一种无状态的协议(不了解的同学可以去某度深入了解一哈),http协议中,我们客户端一个普通的请求大致分为三个步骤:
1、首先>>>客户端发送请求到服务器 ;
2、然后>>>服务器处理请求;
3、最后>>>响应客户端。
三部完成,一次交互也就完成了,之后客户端再次向该服务区发送请求后,服务器端其实并不能准确知道这此次请求和上次请求是否是同一个浏览器或用户发出来的,为了解决这个问题,作为web服务器必须能够采用某种方式来唯一识别同一个用户,并记录该用户的状态。而这同一个客户端与服务器端的在一段时间内的多次交互,我们就可以称该客户端为该服务器端的一个客户端会话窗口,有了会话窗口,我们请求的来源就很容易知道,进而实现会话跟踪,记录用户的行为。如下图就是一个cookie:

我们爬数据的时候,除了采用代理或者爬百度高德poi之外,基本上(大部分),如果我们要获取某个浏览器的接口的数据,很多都需要携带cookies,保证登录信息,才能获取到我们想要的接口数据
三.关间信息header
上面说到http协议,以及cookie的作用,相对来说,Header则是HTTP请求比较核心的点,它包含了像客户端浏览器,请求页面,服务器等相关的一系列信息。
当我们在浏览器(以谷歌为例)地址栏里输入地址后,打开浏览器F12(开发者选项),你的窗口将会有类似如下的信息:
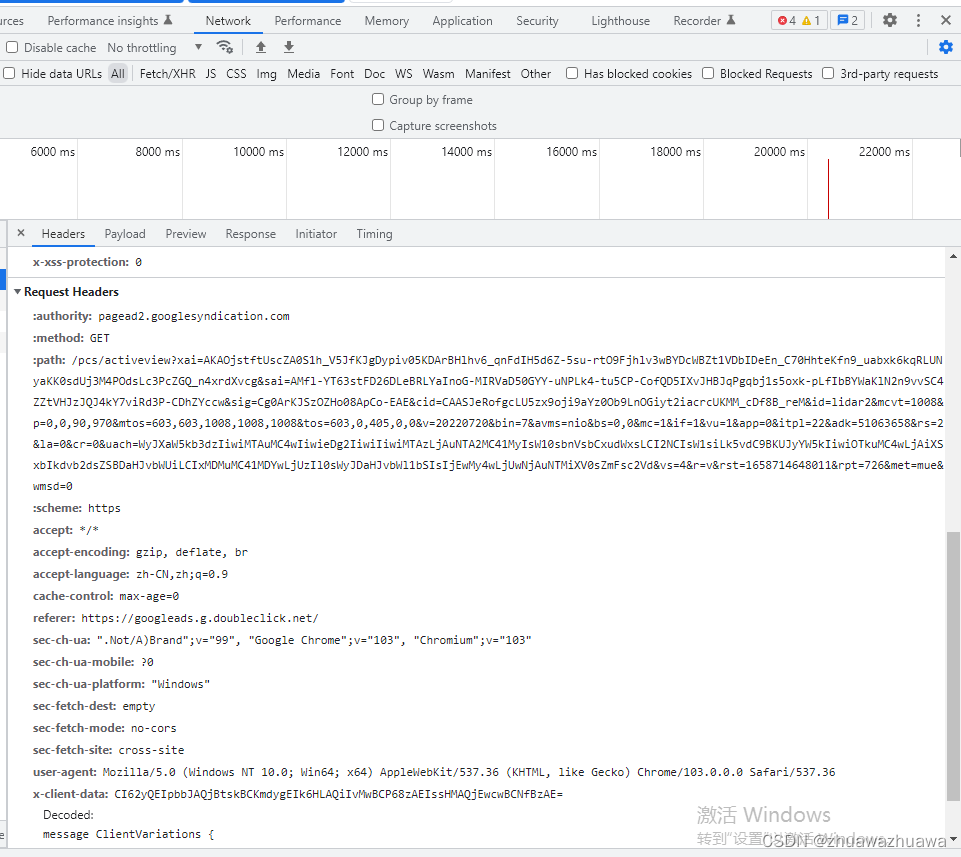
其中有一个属性 User-Agent 还是比较重要的,因为一般都需要添加该属性,如果稍微做过一点反爬过的网站,没有该属性,我们是无法爬取的。该属性主要携带客户端使用的操作系统和浏览器的名称和版本信息。
当我们登陆一些网站的时候,往往会看到一些友好的欢迎信息,列出了你的操作系统的名称和版本等等,大多时候我们并不清楚我们的信息是如何被获取到的;但其实,服务器应用程序就是从User-Agent的请求头中获取到这些信息的。User-Agent请求头允许客户端将它的操作系统、浏览器和其它属性告诉服务器。如上图,就可知我的应用程序版本“Mozilla/5.0”;“Windows NT 10.0 x64”表示“操作系统Windows10 64位系统”;浏览器版本等等................
我们发送请求完成后,首先肯定会收到状态码反馈是否成功如下图:
接下来我们进入下一个模块
四.requests模块
为什么要用这个模块?因为request可以“伪造”请求,不需要我们通过浏览器直接发送这些数据,只需要通过python中request来模拟浏览器发送请求。Requests模块其实就是Python实现的简单的HTTP库,和爬虫相关的其他库,在使用之前必须先引入该模块,当然python还提供了很多爬虫模块,例如urllib,httplib。但就目前来说Requests模块是最流行,最简单的。也是当前比较好用的模块,当然,在一些比较复杂的网站或做反爬比较厉害的网站,直接通过request往往是不够的,还需要有其他模块的加入,例如直接爬取源码解析,或者爬取前端代码属性值等等,就需要加入urllib模块才能实现。下图展示的就是request的一个简单请求

五.爬取数据(以ai企查专利数据为例)
准备:python版本3以上,我用的工具是pychorm,破解版可以微信公众号搜,还是比较容易获取,还有就是要引入模块requests
1.首先浏览器登录爱企查,进入F12开发者选项,清空当前请求响应
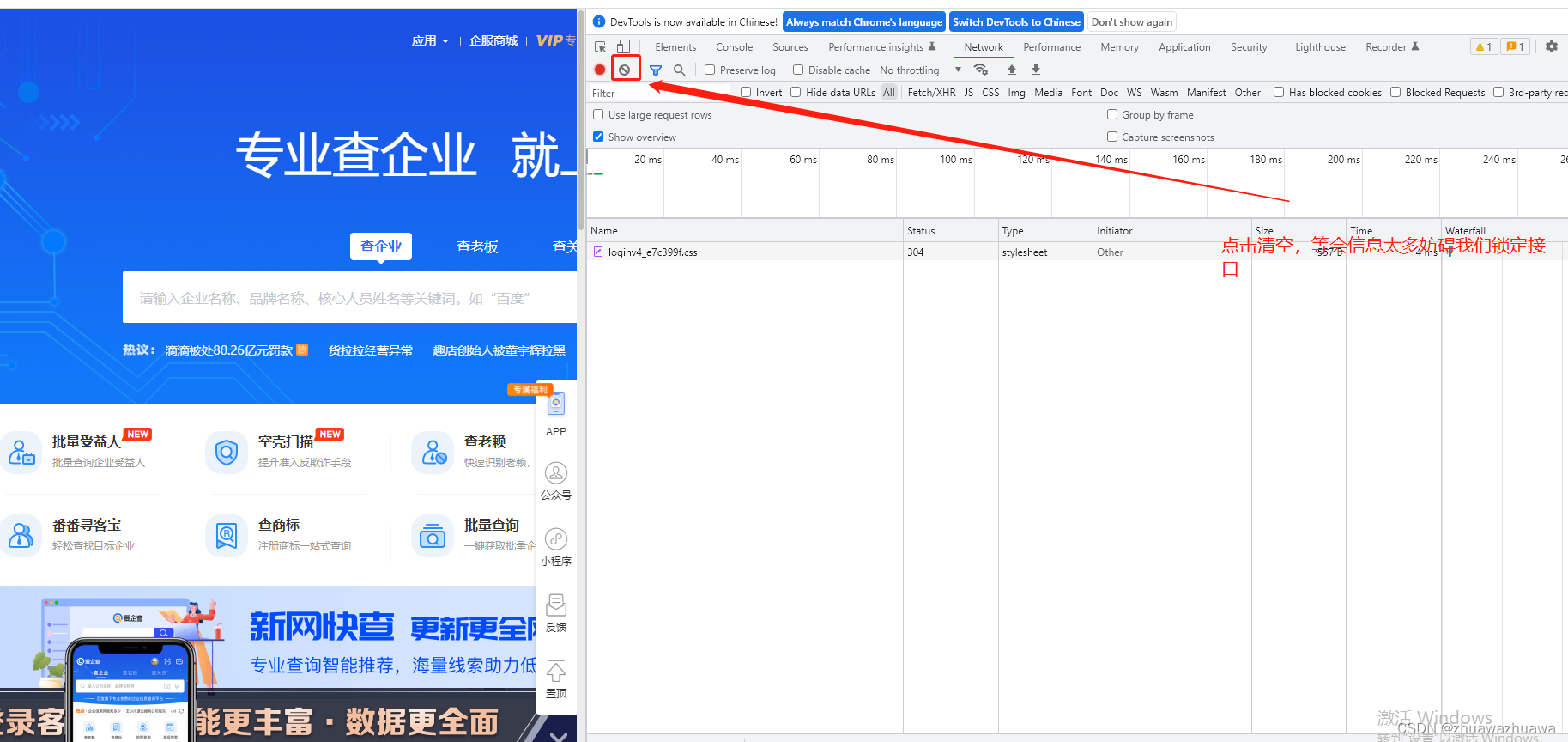
2.在输入框随便输入几个文字,某度这个主要是模糊查询,

3.此时就会暴露出几个接口,可以看到suggest接口,点击该接口的响应response,可以看到接口下具体json类型信息(这就是我们需要爬取的第一部分数据),还可以看到pid(该字段关联了ai企查很多其他信息), 有了pid,你可以在爱企查获取绝大部分你想要的接口数据
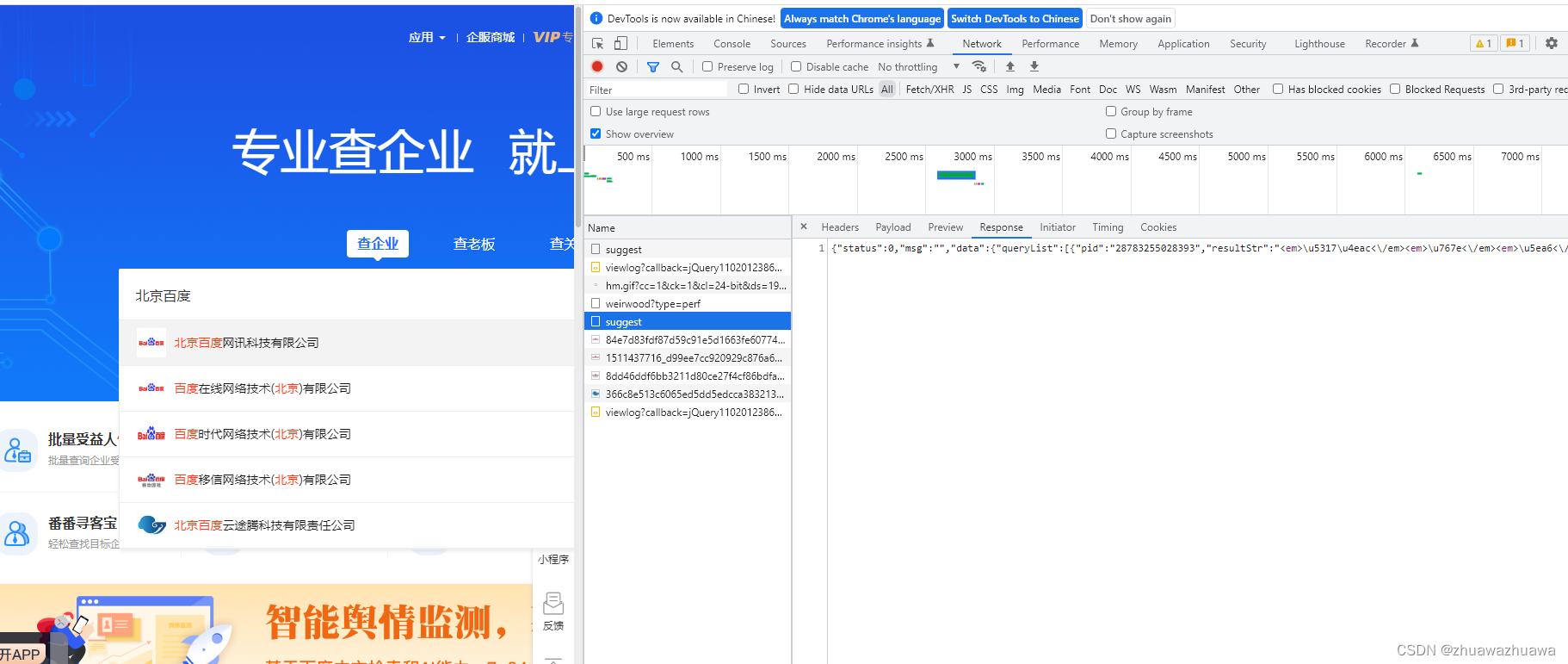
4.此时我们想要获取的第一步信息流程已经走通且能拿到数据,按思路,写代码爬取了。
注意>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
找到刚刚我们获取到的接口suggest,右键copy-->copyasurl(bash)
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
进入网页Convert curl commands to code
这个网页可以帮我们生成cookies和头
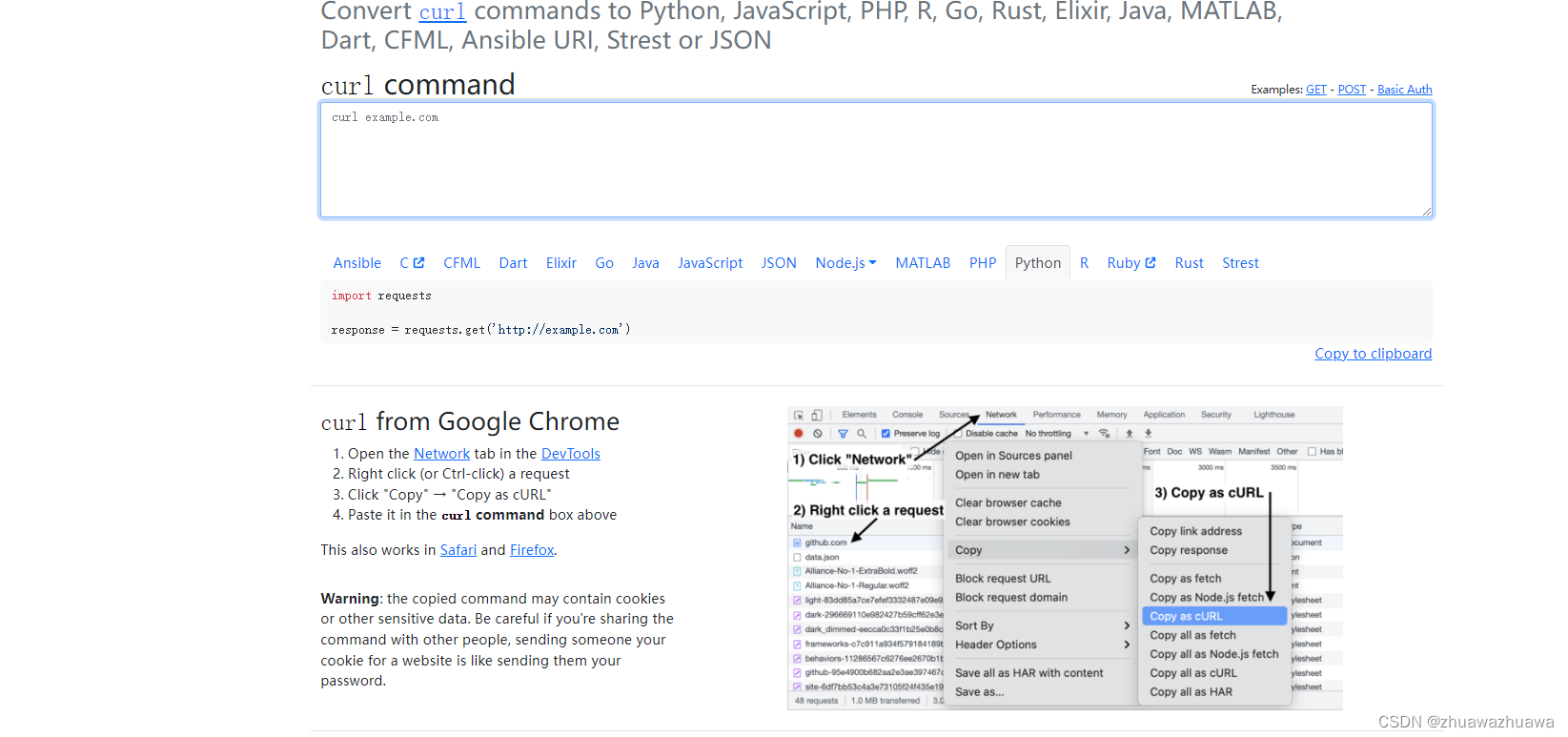
5.将刚刚复制的接口粘贴进command,选择python
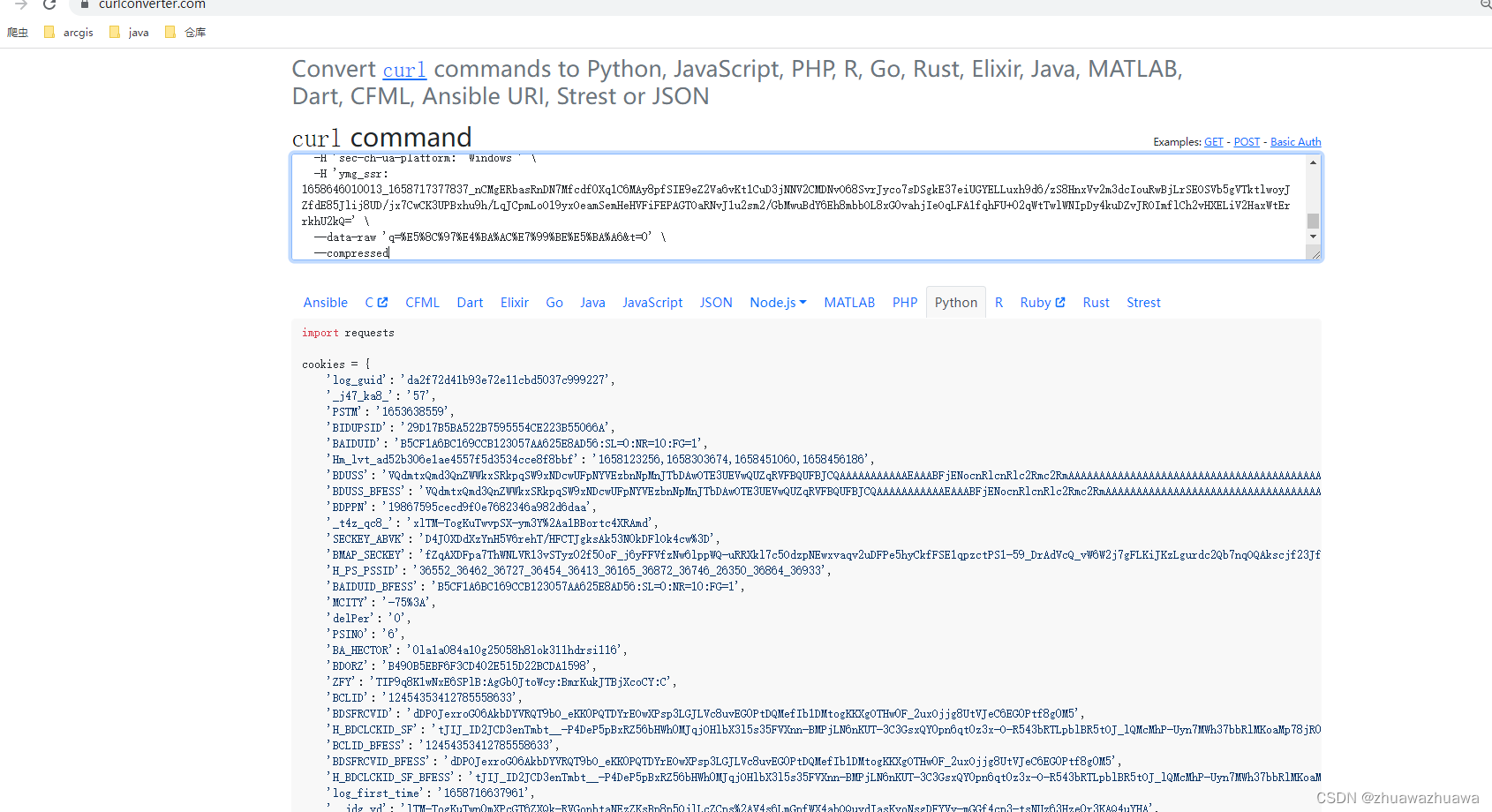
就能得到头和cookies信息了,然后复制下面代码
6.在编辑工具新建一个文件,将代码粘贴即可,此时就能获取到数据了
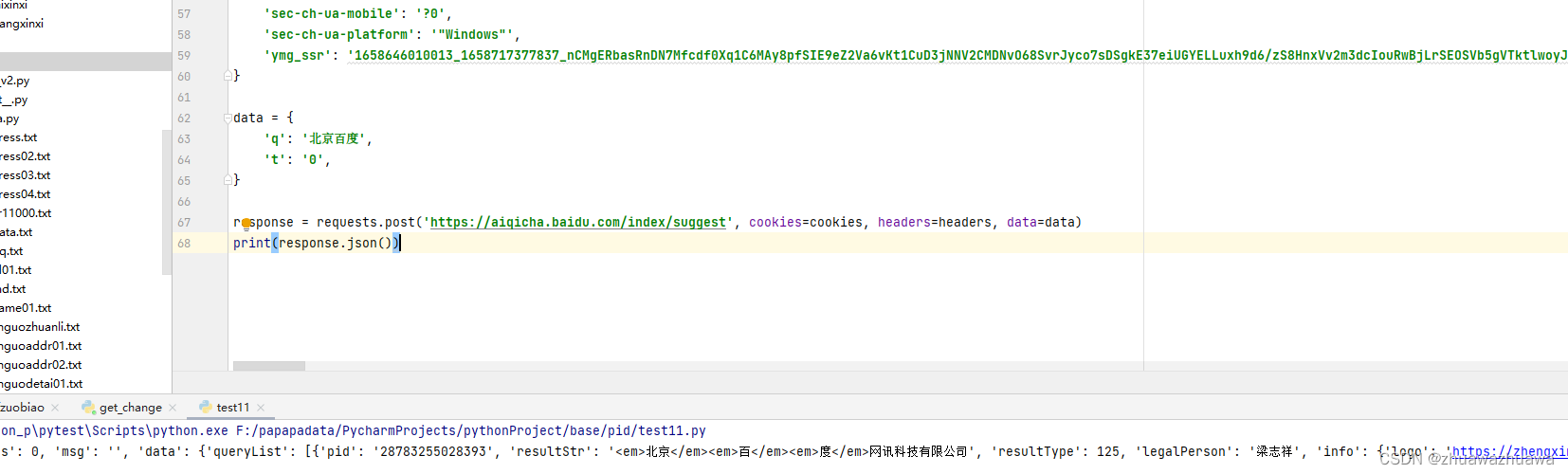
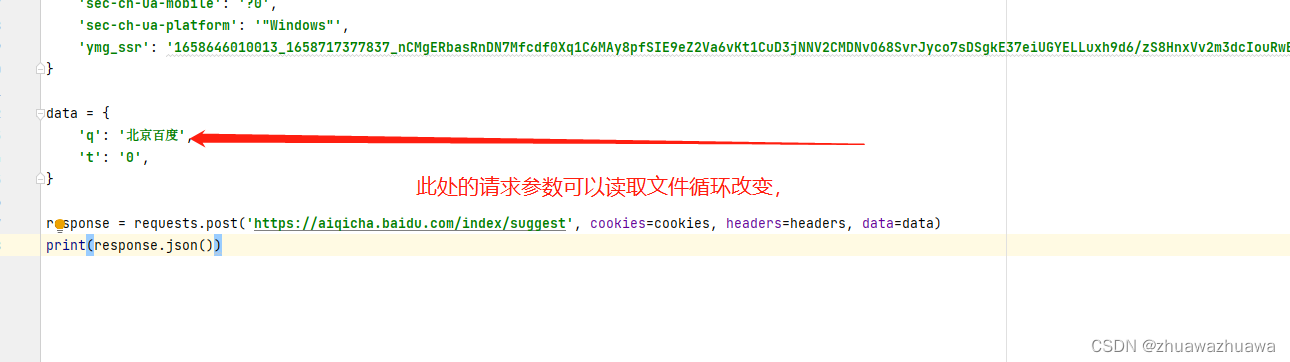
但是为了提高容错性与健壮性,除了添加代理以外,还需要进行异常处理,下面附上我自己之前用的代码。
import time
import requests
from bs4 import BeautifulSoup
import xlrd
import json
import random
import requests
cookies = {你的cookies}
headers = {你的请求头}
# 隧道域名:端口号
tunnel = "你的隧道端口信息 可以网上买"
# 用户名密码方式
username = "用户名"
mima= "***"
proxies = {代理信息}
def get_com_list(name):
data = {
'q': name,
't': '0',
}
try:
response = requests.post('https://aiqicha.baidu.com/index/suggest', cookies=cookies,headers=headers,proxies=proxies, data=data,timeout=(0.5, 0.8))
time.sleep(0.2)
queryList = response.json()["data"]["queryList"]
print(queryList)
for query in queryList:
pid = query["pid"]
resultStr = query["resultStr"].replace("<em>", "")
resultStr = resultStr.replace("</em>", "")
resultStr = resultStr.replace("(", "(")
resultStr = resultStr.replace(")", ")")
if resultStr == name:
print("end---", pid, resultStr)
with open("gqdata.txt", "a", encoding='utf-8') as file:
result = name + "," + pid + "\n"
file.write(result)
except Exception as e:
print("-----")
print(e)
get_com_list(name)
with open("此处txt文件是我要抓的企业名称", "r+", encoding='utf-8') as file:
content = file.read()
com_list = content.split("\n")
with open("gqdata.txt", "r+", encoding='utf-8') as file:
result = file.read()
result_list = result.split("\n")
name_list = [r.split(",")[0] for r in result_list]
for i in range(0, len(com_list)):
com_name = com_list[i]
if com_name in name_list:
a = 1
else:
print("no")
get_com_list(com_name)
第一步获取pid已经完成,接下来我们继续,获取专利信息
1.首先随便搜索进入一家企业(以北京百度为例),打开F12清空所有页面接口等等信息,找到知识产权专利信息.
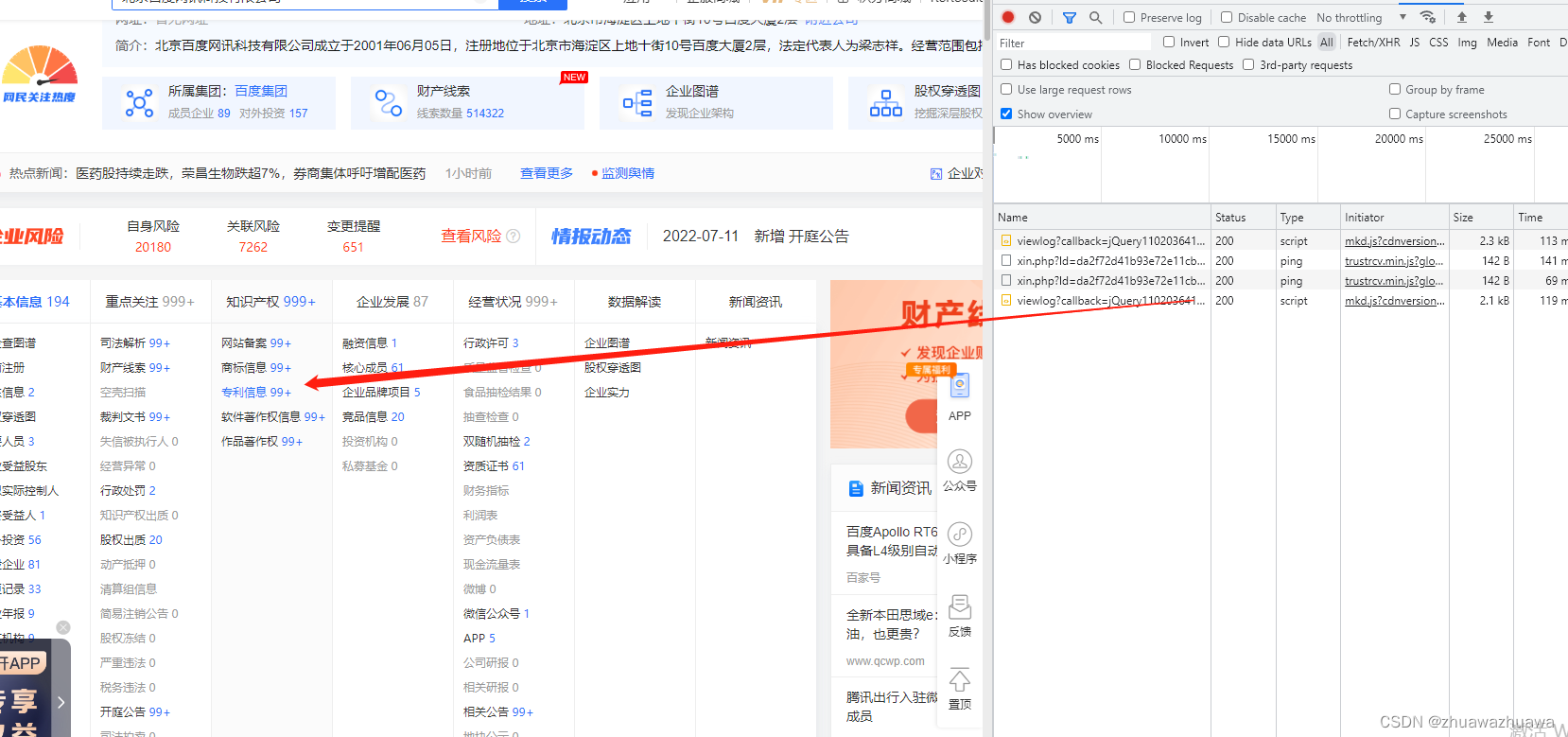
2.进入点击,清理所有接口信息
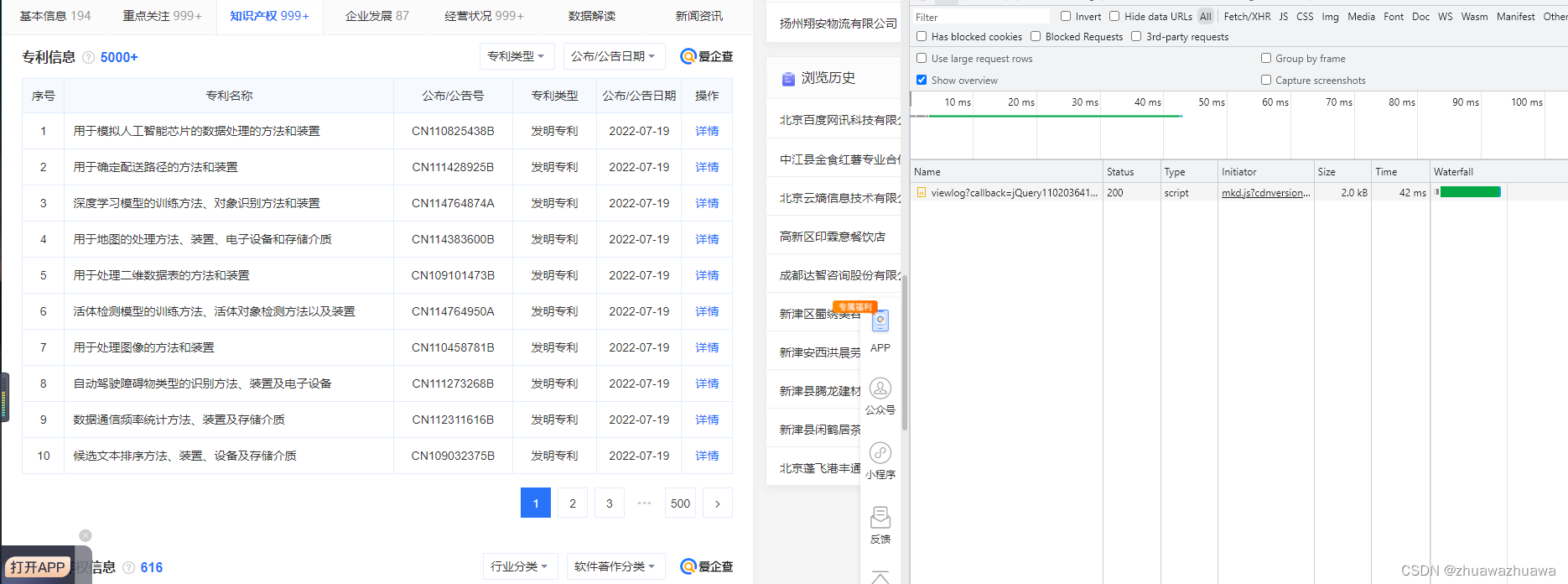
3.选择页数,此时就会暴露专利信息接口
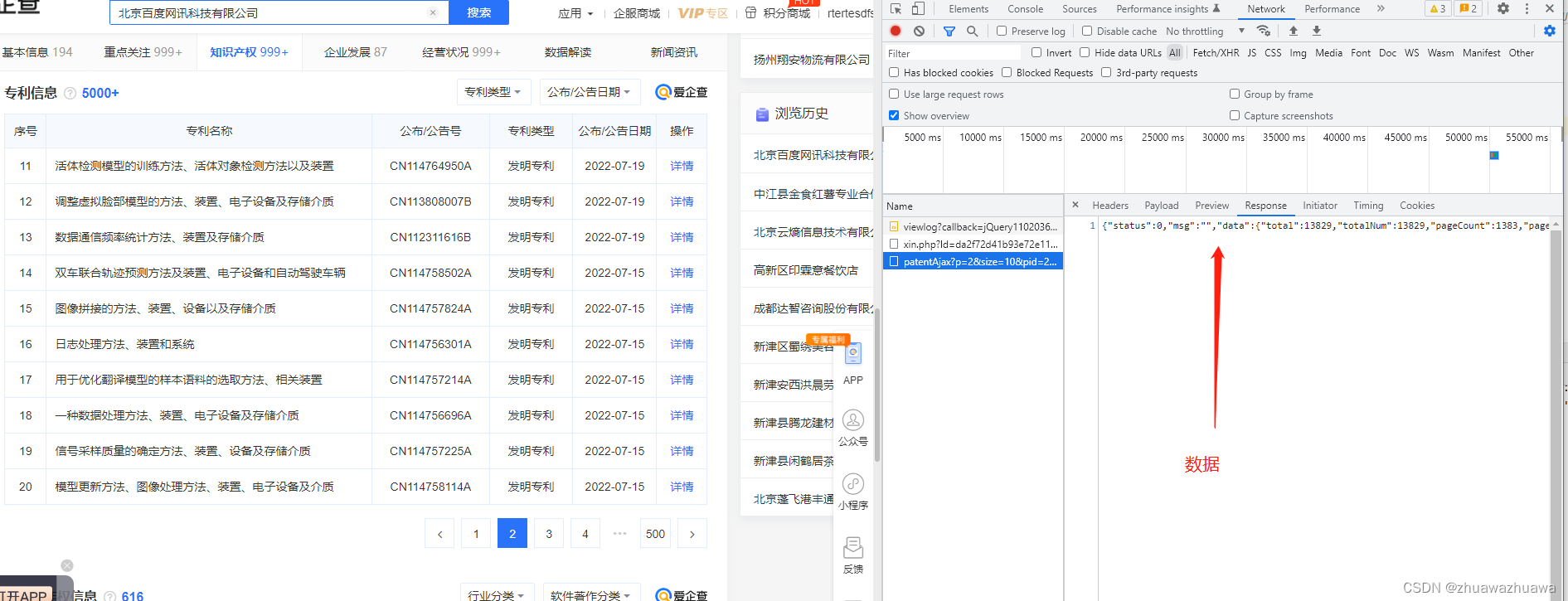
4.哈哈,接下来驾轻就熟同样的步骤即可爬取专利,不仅仅是专利信息哦,基本所有的该页面接口信息都能拿捏,同样附上我的简易代码(此处没有做调试,代理等等,当初数据比较少,就为了快速干完,没有考虑这些问题,可以自行调整代码):
import requests
cookies = {你都cookies}
headers = {
你的头信息
}
lines = []
with open('你的pid', mode='r', encoding='UTF-8') as kf:
while True:
line = kf.readline()
if not line:
break
line = line.strip()
lines.append(line)
print(len(lines))
names = []
with open('和pid对应的名称', mode='r', encoding='UTF-8') as kf:
while True:
line = kf.readline()
if not line:
break
line = line.strip()
names.append(line)
print(len(names))
#
j = 0
with open('存取位置', mode='a', encoding='UTF-8') as pd:
while j < len(names):
i = 1
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>"+str(j)+"<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")
max = 10
while i <= max:
params = {'p': i, 'size': max, 'pid': lines[j], }
response = requests.get("https://aiqicha.baidu.com/detail/patentAjax", params=params, cookies=cookies,headers=headers)
data = response.json()["data"]
max = response.json()["data"]["pageCount"]
data["name"] = names[j]
name = data["name"]
print(name)
print(max)
i += 1
res = str(data)
print(res)
pd.writelines(res + '\n')
j += 1

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









