







第二章监督学习_线性模型
01 线性模型适合处理的问题
markdown里的数学公式不太会写,就按自己理解的简单描述一下吧
线性模型给出的预测公式大概是:
特征1 特征1系数 + 特征2 特征2系数 + 特征n 特征n系数 + 偏移系数 = 预测结果.
x[0] w[0] + x[1] w[1] + x[n] w[n] + b
从字面上理解,线性模型绘图效果应当是直线.
书中介绍 1个属性成直线, 2个属性成平面, 多个属性成超平面,看到这里暂时还不太理解.
但是从公式来看,线性方程模型因为汇集了各个特征数据,因此应当能解决K邻近算法对特殊个数支持不足的短板.
02 怎样判断线性模型的好坏
所有的模型好坏的判断都是看计算结果与真实结果的误差有多少,只不过每种模型对这个"多少"的计算方法不一样罢了.
线性模型均方差来衡量误差大小: (我理解:平方是为了放大微小的偏差.)
SUM((数据1预测值 - 数据1真实值)平方 … + (数据N预测值 - 数据N真实值)平方) / N
03 简单例子[LinearRegression] (单一特征)
# 线性模型
from sklearn.linear_model import LinearRegression
# K邻近算法模型
from sklearn.neighbors import KNeighborsRegressor
# 波形图数据 [单一特征]
from mglearn.datasets import make_wave
# 机器学习 数据分离
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 获得样本数据
X, y = make_wave(n_samples=60)
# 分离数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 喂数据
lr = LinearRegression().fit(X_train, y_train)
knn = KNeighborsRegressor().fit(X_train, y_train)
# 用训练数据查看结果
plt.plot(X_train, lr.predict(X_train))
plt.plot(X_train, knn.predict(X_train))
plt.legend(['LinearRegression', 'KNeighborsRegressor'], loc='best')
# 显示画布
plt.show()
In [21]: X[:5]
Out[21]:
array([[-0.75275929],
[ 2.70428584],
[ 1.39196365],
[ 0.59195091],
[-2.06388816]])
In [22]: lr.predict(X_train)[:5]
Out[22]: array([ 0.02670583, 0.20717424, -1.07624425, -0.92509177, -0.84478135])
In [23]: dir(lr)
Out[23]:
['__abstractmethods__',
...
'coef_', # 线性公式中的数据样本特征系数 w
'intercept_', # 线性公式中的偏移参数 b
'n_features_in_',
'rank_',
'singular_']
In [25]: dir(knn)
Out[25]:
['__abstractmethods__',
...
'effective_metric_',
'effective_metric_params_',
'n_features_in_',
'n_samples_fit_',
'weights']
In [26]: lr.coef_ # 特征系数
# 注意看这里返回的时数组,也就是说每个特征都会有这么一个值
# 从上图可以看出俩,邻近算法的点虽然忽上忽下,但是总的趋势和线性方程的直线斜度差不多
# 线性方程我立即就是表现这种斜度,而将忽上忽下的点都汇集在这个斜度的直线上
# 既然改变了点的位置,那就肯定会出现误差,这个误差的具体算出公式我暂时不研究了,先知道为什么有误差就可以了
Out[26]: array([0.39390555])
In [27]: lr.intercept_ # 偏移系数
Out[27]: -0.031804343026759746
# 查看模型得分, 不咋地呀
In [28]: lr.score(X_train, y_train)
Out[28]: 0.6700890315075756
# 测试数据分数也低得可怜, 不要这个分数倒是与训练数据分数差不多
# 数上说这叫做欠拟合,这个要怎么理解呢:
# 对于一个模型来说,无论什么样的数据计算结果都很低而且得分差不多的情况,属于毫无目的性,毫无选择性,
# 对各种数据都包容,为了做到包容就要损失一部分强过滤,好比网眼越大,穿过鱼的大小种类越多,因此叫欠拟合.
# 如果这个模型对训练数据得分很高,而测试数据分数低的可怜,那就说明是过拟合. (模型条件它复杂,不适用于其它数据)
In [29]: lr.score(X_test, y_test)
Out[29]: 0.65933685968637
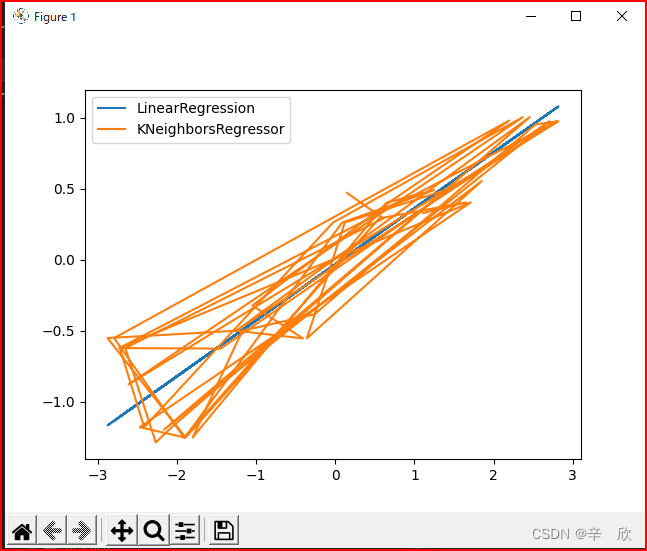
为了描述,我把K邻近模型的结果和线性模型都放在一张图上.
对于拥有一个特征的数据样本而言:
- K邻近模型几乎真实反映了预测位置
- 线性模型突出的是一种趋势,所以会使计算结果都靠近这个趋势的水平面上而形成一条直线.因此对于特征数少的数据样本来说,线性模型的误差要更大一些.
另外书中提到一个技巧: 所有的模型的实例化对象中都有不已下划线开头但以下划线结尾的属性,
这些属性存放的是模型训练后的结果,是为了区别于用户设定的内容.
04 简单例子[LinearRegression] (多特征)
# 线性模型
from sklearn.linear_model import LinearRegression
# 波士顿房价数据 [多特征]
from mglearn.datasets import load_extended_boston
# 机器学习 数据分离
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 获得样本数据
X, y = load_extended_boston()
# 分离数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 喂数据
lr = LinearRegression().fit(X_train, y_train)
# 用训练数据查看结果
plt.plot(X_train, lr.predict(X_train))
# 显示画布
plt.show()
In [2]: X.shape
Out[2]: (506, 104)
# 训练数据得分也不高呀,难道是过拟合?
In [3]: lr.score(X_test, y_test)
Out[3]: 0.6074721959665939
In [4]: lr.score(X_train, y_train)
Out[4]: 0.9520519609032727
函数帮助如下:
In [9]: from sklearn.linear_model import LinearRegression
In [10]: help(LinearRegression)
Help on class LinearRegression in module sklearn.linear_model._base:
class LinearRegression(sklearn.base.MultiOutputMixin, sklearn.base.RegressorMixin, LinearModel)
| LinearRegression(*, fit_intercept=True, normalize='deprecated', copy_X=True, n_jobs=None, positive=False)
|
| Ordinary least squares Linear Regression.
|
| LinearRegression fits a linear model with coefficients w = (w1, ..., wp)
| to minimize the residual sum of squares between the observed targets in
| the dataset, and the targets predicted by the linear approximation.
|
| Parameters
| ---------- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









