







第二章监督学习_决策树集成
集成? 难道是准备讲模型间模型协作处理问题?
书中提到了俩个模型:
| No | 模型名 | 原名 |
|---|---|---|
| 1 | 随机森林 | random forest |
| 2 | 梯度提升决策树 | gradient boosted descision tree |
01 随机森林(random forest)
处理问题思路:
核心: 构建多个随机决策树,然后获取每棵树的预测结果再取平均值.
每棵树在决策时不在像决策树那样针对每个节点寻找最佳划分,而是针对某一特征做划分.
对于回归问题: 采用取各个树的平均值.
对于分类问题: 同样先算出每棵树,然后算出所有树的平均值,最终返回概率最大那棵树的结果
分类的那个有点怪异,为什么还要算平均值,每棵树算完不就知道概率了吗?
我猜可能跟这个模型的核心有关,那就是随机.
随机具体体现:
-
数据样本随机(n_sample 采样)
我理解每颗树的训练用的数据样本的个数因该是一样的,不同的是每个样本的数据内容.
书中提到了一个参数[n_sample],我猜它的作用因该是随机采样时每个重复样本的最大个数.举个例子说:
有10个数据样本,你需要随机在这个样本中抽数据.
完成条件是:
随便抽样本,重复了没事,凑出10个样本就行,但是重复样本的个数不能超过n_sample因此每棵树在开始建模就会于原始样本有偏差,
因此不论是解决分类问题也好,还是回归问题也好,都要先算平均值. -
数据特征随机(max_features 采样)
这个是关于特征的随机采样,跟上面稍有不同是:
特征不能重复,而且不能超过原始特征个数.
随机森林 二分类例子
# 绘图相关
import mglearn
import matplotlib.pyplot as plt
# 决策树集合
from sklearn.ensemble import RandomForestClassifier
# 2分类数据集
from sklearn.datasets import make_moons
# 数据分离
from sklearn.model_selection import train_test_split
#############
# 数据样本
#############
# 创建数据样本
# noise
# 增加噪点, 增加数据样本的难度
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
# 差分数据
X_train, X_test, y_train, y_test = \
train_test_split(X,y,stratify=y,random_state=42)
#############
# 数据模型
#############
# 创建决策树集合
# n_estimators
# 决策树中树的个数
forest = RandomForestClassifier(n_estimators=5, random_state=2)
# 向决策树集合模型喂数据
forest.fit(X_train, y_train)
#############
# 绘图
#############
# 在一张画布上创建一个 2 * 3个 绘图, 并限定每个绘图的大小
fig, axes = plt.subplots(2, 3, figsize=(20, 30))
# 使用enumerate为每一次循环计数
# forest.estimators_ 带到一个arraylist里面包含5个实例化的树模型
# axes是 2 * 3 二维数组 axes.ravel()可以把多维数组转变成一维数组
# 结合上面信息,循环的目的就是每次得到一个绘图对象和它对应的树模型
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
# 设置每一个绘图对象的标题
ax.set_title("Tree {}".format(i))
# 在每个模型上用训练数据测试每个模型成果,同时画出决策边界
mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
# 我们创建了6个绘图,据册数集合只使用了5个
# 在最后一个绘图上绘制决策树集合计算的最终的决策边界
mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1], alpha=0.4)
# 在最后一个绘图上设置标题
axes[-1, -1].set_title("Random Forest")
# 在最后有一个绘图上绘制绘制散点图
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
# 显示画布
plt.show()
成像效果
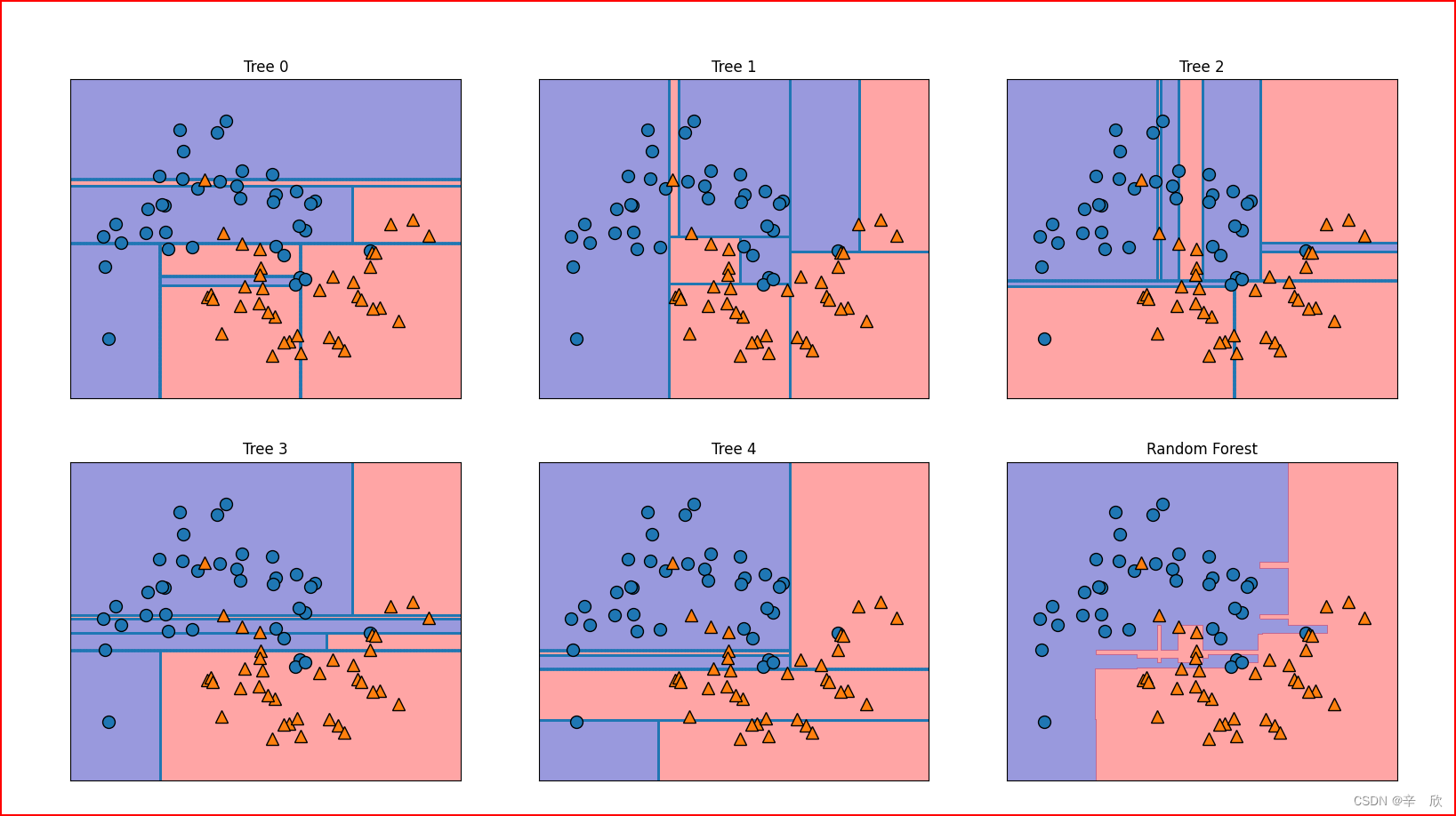
这个图怎么看:
- 1~5是决策树模型创建的5个决策树模型各自的图
- 6是将前5个图层综合分析后合成的图,从图的变现来看并不是简单的堆叠前5张图
可能产生的问题
- 1~5图中,散点图相同决策边界为什么不同
散点图相同原因:
影响散点图的参数是[n_sample],我们在建模的时候没有指定,因此每个决策树都必须考虑整个数据集
决策边界不同原因:In [27]: forest Out[27]: RandomForestClassifier(n_estimators=5, random_state=2) # 每个决策树模型都有一个随机种子,这个是在决策树集合模型内部实现的 In [28]: forest.estimators_[0] Out[28]: DecisionTreeClassifier(max_features='auto', random_state=1872583848) In [29]: forest.estimators_[1] Out[29]: DecisionTreeClassifier(max_features='auto', random_state=794921487)
之前在学决策树时写过一个例子,证明了模型的决策并不是通过特征重要性来划分的,
我们用同样的数据同样的方法,看看决策树集合的表现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
lr = load_iris()
tree1 = DecisionTreeClassifier().fit(lr.data, lr.target)
tree2 = RandomForestClassifier(n_estimators=100).fit(lr.data, lr.target)
n_feature = len(lr.feature_names)
# 在Y轴上显示 指定宽度的bar
# 第一个参数:
# 参数的Y轴位置
# 第二参数:
# bar的宽度
plt.barh(range(n_feature), tree1.feature_importances_,
align='center', label="tree")
plt.barh(range(n_feature), tree2.feature_importances_,
align='center', label="some tree")
# 在Y中指定位置加label
plt.yticks(np.arange(n_feature), lr.feature_names)
plt.legend()image/
plt.show()
成像效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kgmizhtw-1654525180188)(.\image\2022-06-06-11-00-25.png)]](https://img-blog.csdnimg.cn/e4cde46a594942edb0cfa4dd5a8e56e5.png)
可以看出决策树集合模型给出了准确的答案,
也就是说决策树集合模型是综合分析特征后再进行决策.
随机森林模型总结
-
优点:
- 随机森林有决策树模型的所有优点,而且弥补了决策树过拟合的问题.
- 在默认参数下模型的预测结果就很准确
-
缺点
- 随机森林的模型深度要远远大于决策树的深度,不适合演示教育目的.
- 默认情况下模型的构建是随机的,如果需要再现模型问题时,模型构建参数 radom_state要设置成0才可以
- 模型的构建需要消耗更多的内存和时间
- 对高纬度的稀疏数据,特别是文本支持不是太好
- 如果想在短时间取得大概的预测结果,使用线性模型要更好一些
02 梯度提升决策树(gradient boosted descision tree)
原理 梯度提升决策树
通过合并多个数构建模型,
随机森林的重点在于随机,
梯度提升决策树是连续创建,而且新创建的树总是试图解决上棵树的错误
梯度提升决策树产生的思想: 合并多个简单的模型结果,通过迭代来提高模型性能
梯度提升决策树 例子
# 决策树集合 梯度提升决策树
# 多维数据基础库
import numpy as np
# 绘图相关
import matplotlib.pyplot as plt
# 机器学习 数据分离
from sklearn.model_selection import train_test_split
# 机器学习 肿瘤数据样本
from sklearn.datasets import load_breast_cancer
# 梯度提升决策树
from sklearn.ensemble import GradientBoostingClassifier
# 随机森林
from sklearn.ensemble import RandomForestClassifier
# 决策树
from sklearn.tree import DecisionTreeClassifier
def plots_feature_importances_cancer(model, ax, str_x_label):
""" 使用算法模型绘制标尺图
Args:
model (_type_): 算法模型
ax (_type_): 单个绘图
"""
# 获得特征个数
n_features = cancer.data.shape[1]
# 绘制标尺
ax.barh(range(n_features), model.feature_importances_, align='center')
# 设置Y轴标尺的表示内容
ax.set_yticks(np.arange(n_features), cancer.feature_names)
ax.set_xlabel(str_x_label)
ax.set_ylabel("Feature")
# 获得肿瘤数据
cancer = load_breast_cancer()
# 数据分离
X_train, X_test, y_train, y_test = \
train_test_split(cancer.data, cancer.target, random_state=0)
# 实例化决策树
tree = DecisionTreeClassifier(random_state=0)
# 实例化随机森林
random_trees = RandomForestClassifier(random_state=0)
# 实例化梯度提升决策树
gradient_trees = GradientBoostingClassifier(random_state=0, max_depth=1)
# 训练模型
tree.fit(X_train, y_train)
random_trees.fit(X_train, y_train)
gradient_trees.fit(X_train, y_train)
# 为了对比模型间差异,创建了3个绘图
fig, axes = plt.subplots(1, 3, figsize=(20, 30))
# 分别绘图
plots_feature_importances_cancer(tree, axes[0], 'tree')
plots_feature_importances_cancer(random_trees, axes[1], 'random tree')
plots_feature_importances_cancer(gradient_trees, axes[2] 'gradient boost')
# 显示画布
plt.show()
成像效果:
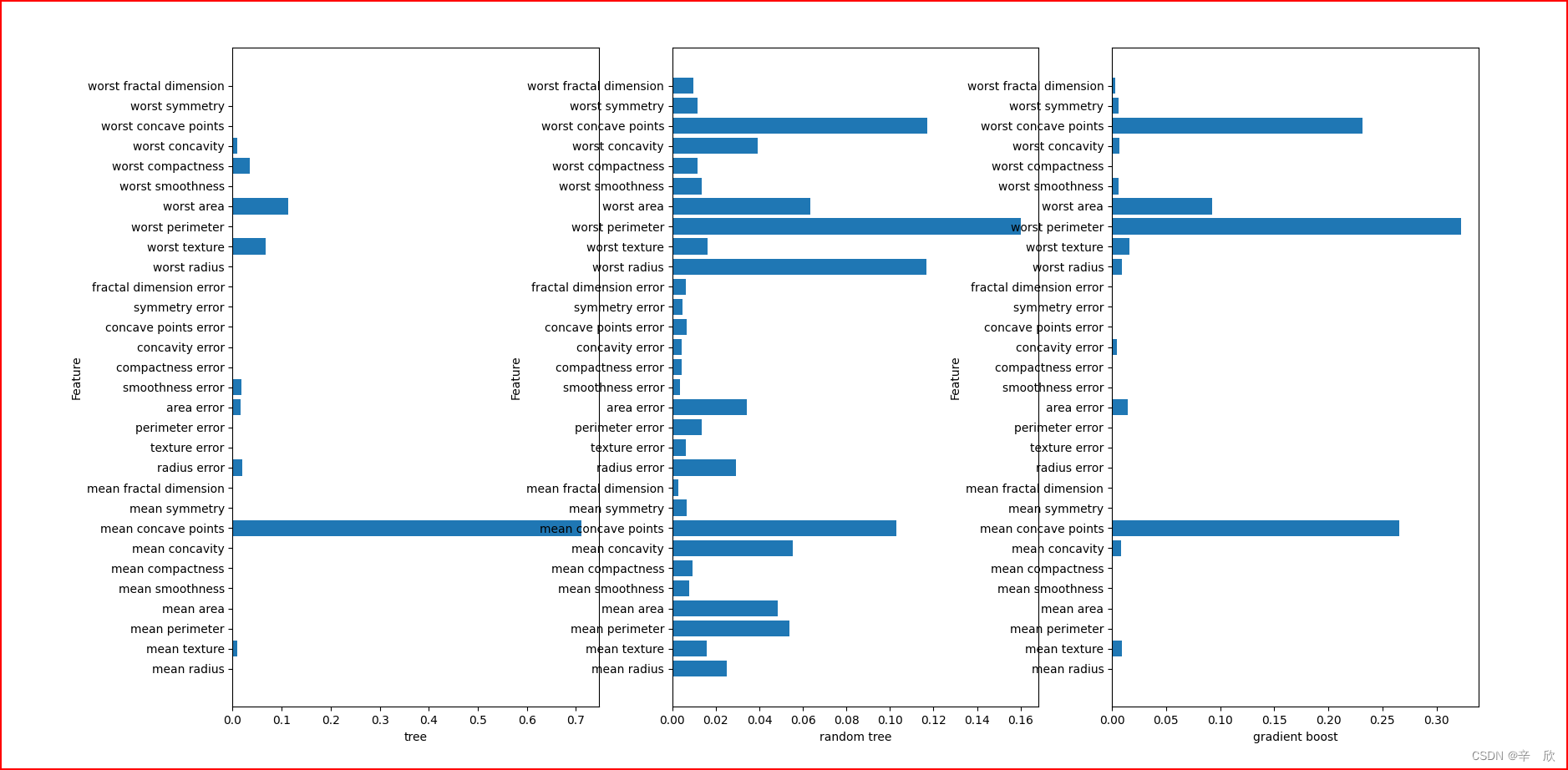
之前我们学决策树的时候就已经证明了: 并不是以最重要的特征来进行决策划分的
从图中我们也可以看出来,随机模型和梯度提升决策树的特征重要划分差不太多,基本预测的很准.
梯度提升决策树模型的图更直观,因为它已经去掉了一些影响不大的特征.
看一下各模型的得分:
In [11]: tree.score(X_train, y_train)
Out[11]: 1.0
In [12]: tree.score(X_test, y_test)
Out[12]: 0.8811188811188811
In [13]: random_trees.score(X_train, y_train)
Out[13]: 1.0
In [14]: random_trees.score(X_test, y_test)
Out[14]: 0.972027972027972
In [15]: gradient_trees.score(X_train, y_train)
Out[15]: 0.9906103286384976
In [16]: gradient_trees.score(X_test, y_test)
Out[16]: 0.972027972027972
决策树集合的俩模型的测试得分都不错.梯度提升模型还可以微调参数来改变模型的结果.
| Class名 | PKG位置 | 参数 | 参数说明 |
|---|---|---|---|
| GradientBoostingClassifier | sklearn.ensemble | [n_estimators] 决策树个数 默认100 [max_depth] 决策的最大深度 默认3 一般不超过5 [learning_rate] 学习率 默认0.1 | [n_estimators] 决策树个数越多,预测结果越平滑,模型过拟合度越小(参考的内容越多结果越准确),相应的模型越复杂 [max_depth]深度越大,模型越准确,时间内存消耗越大 [learning_rate] 越大新树的纠错强度就越高,越低学习能力越弱,也就需要更多的树来学习 |
梯度提升决策树总结
因为随机森林模型和梯度提升模型的变现都很好,而且随机森林在默认参数下的预测就很准确,
因此一般建议先选用随机森林来建模.
如果在机器性能优点吃紧或是时间比较仓促又或者需要更精确的预测那么可以选择梯度提升决策树模型.
梯度提升模型中n_estimators参数控制创建树的个数, learning_rate学习率控制每颗树的学习强度.
这两个参数耦合度很高.树越多,模型越复杂.学习率越低就需要更多的树来支持
书中建议优先使用n_estimaotrs来控制模型复杂度,然后通过微调learning_rate来控制模型精度.















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









