







首先介绍一下题意:已知,有N个学生和P门课程,每个学生可以选0门,1门或者多门课程,要求在N个学生中选出P个学生使得这P个学生与P门课程一一对应。
这个问题既可以利用最大流算法解决也可以用匈牙利算法解决。如果用最大流算法中的Edmonds-karp算法解决,因为时间复杂度为O(n*m*m),n为点数,m为边数,会超时,利用匈牙利算法,时间复杂度为O(n*m),时间复杂度小,不会超时。
其实匈牙利算法就是最大流算法,只不过它的使用范围仅限于二分图,所以可以称之为“二分图定制版的最大流算法”,既然是定制的,那么他就会考虑到二分图的特殊性,优化原来的最大流算法,降低时间复杂度,同时也变得有点复杂不容易理解了。既然匈牙利算法继承自最大流算法,所以他的算法框架与最大流算法是一样的:
最大流算法与匈牙利算法的框架:
初始时最大流为0(匈牙利算法为:最大匹配为空)
while 找到一条增广路径(匈牙利算法为:取出未遍历的左边的点u)
最大流+=增广路径的流量,更新网络(匈牙利算法为:如果点u存在增广路径,增广路径取反,最大匹配增加1对匹配)
我们知道在利用最大流算法解决最大匹配问题时,首先需要构建一个超级源点s和超级汇点t,并且边是有方向的和容量(为1)的(如图8所示),而利用匈牙利算法则不需要构造s,t,边也没有方向和容量。表面上看匈牙利算法中的边没有方向和容量,其实在它对增广路径的约束中我们可以看到边的方向和容量的“影子”,如下红色标注的约束。
匈牙利算法对增广路径的约束 参见[1] :
(1)有奇数条边。
(2)起点在二分图的左半边,终点在右半边。
(3)路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。)
(4)整条路径上没有重复的点。
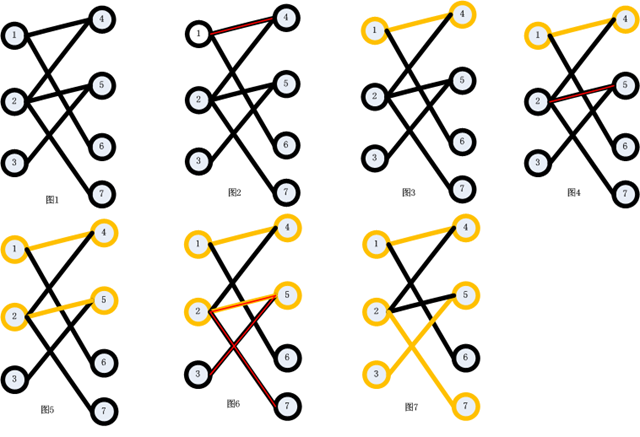
(5)起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。(如图5,图6所示,[2,5]是已经配好对的点;而起点3和终点7目前还没有与其它点配对。)
(6)路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。(如图5,图6所示,原有的匹配[2,5]在在图6给出的增广路径(红线所示)中是第2条边。而增广路径的第1、3条边都没有出现在图5给出的匹配中。)
(7)最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中去,并把增广路径中的所有第偶数条边从原匹配中删除(这个操作称为增广路径的取反),则新的匹配数就比原匹配数增加了1个。(如图6所示,新的匹配就是所有被红色的边所覆盖的黑色的边,而所有红色的边所覆盖的黄色的边则从原匹配中删除,最终匹配结果如图7黄色的边所示。则新的匹配数为3。)
为了便于理解,下面给出利用最大流算法和匈牙利算法解决最大二分匹配的图示。图1为初始二分图,图1->图7为利用匈牙利算法求解最大二分匹配的过程,图8为利用图1二分图所构建的流网络,图8->图14为利用最大流算法求解最大二分匹配的过程,最终求得的最大流为所有增广路径(如图9,图10,图11所示)增加的流相加:1+1+1=3。
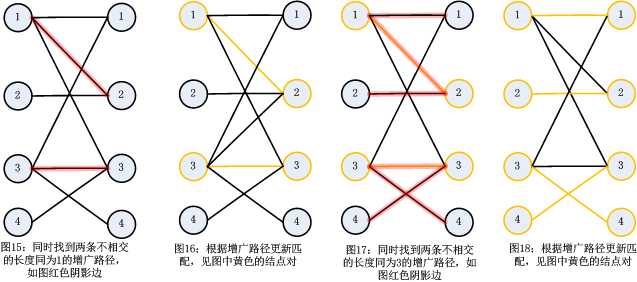
下面介绍一下Hopcroft-Karp算法,这个算法的时间复杂度为O(n^(1/2)*m)。该算法是对匈牙利算法的优化,如图1-图7,利用匈牙利算法一次只能找到一条增广路径,Hopcroft-Karp就提出一次找到多条不相交的增广路径(不相交就是没有公共点和公共边的增广路径),然后根据这些增广路径添加多个匹配。说白了,就是批量处理!为了容易理解,我构造了一个图例,见图15-图18。

回到原题中来,code1、code2分别为dfs和bfs实现的匈牙利算法;code3为利用Hopcroft-Karp解决COURSE的代码。
code1:
#include<iostream>
using namespace std;
#define Maxn 500
//课程与课代表
//存储左侧的点连接的右侧点
int lefts[Maxn];
//存储右侧的点 连接的左侧点
int rights[Maxn];
int flag_rights[Maxn];
int G[Maxn][Maxn];
//nc代表课程数目 ns代表学生数目
int nc,ns;
int findpath(int left_u)
{
for(int v=1;v<=ns;v++)
{
if(G[left_u][v]&&!flag_rights[v])
{
flag_rights[v]=1;
if((rights[v]==-1||findpath(rights[v])))
{
lefts[left_u]=v;
rights[v]=left_u;
return 1;
}
}
}
return 0;
}
//最大匹配
int MaxMatch()
{
// printf("MaxMatch开始执行\n");
int cnt=0;
memset(lefts,-1,sizeof(lefts));
memset(rights,-1,sizeof(rights));
for(int u=1;u<=nc;u++)
{
memset(flag_rights,0,sizeof(flag_rights));
if(findpath(u))
{
cnt++;
}
}
return cnt;
}
int main()
{
int num;
scanf("%d",&num);
while(num--)
{
//首先输入数据
memset(G,0,sizeof(G));
scanf("%d%d",&nc,&ns);
for(int u=1;u<=nc;u++)
{
int c_stu;
scanf("%d",&c_stu);
for(int j=0;j<c_stu;j++)
{
int v;
scanf("%d",&v);
G[u][v]=1;
}
}
if(ns>=nc&&MaxMatch()==nc)
{
printf("YES\n");
}
else
{
printf("NO\n");
}
}
return 0;
}
code2:
#include<iostream>
#include<queue>
#define Maxn 500
using namespace std;
//利用匈牙利算法解决二分图匹配问题
int nc,ns;//nc代表课程数 ns代表学生数
int lefts[Maxn];//存储课程所对应的学生
int rights[Maxn];//存储学生所对应的课程
int G[Maxn][Maxn];
int pre_left[Maxn];//记录课程前面的课程 (增广路径)
int mark_right[Maxn];//记录当前学生是否已经遍历(增广路径)
//利用广度优先搜索 得到最大匹配数
int max_match()
{
//lefts 数组初始化为0
memset(lefts,-1,sizeof(lefts));
memset(rights,-1,sizeof(rights));
int maxf=0;
for(int i=1;i<=nc;i++)
{
queue<int>q;
q.push(i);
int ok=0;
memset(mark_right,0,sizeof(mark_right));
memset(pre_left,0,sizeof(pre_left));
while(!q.empty())
{
int u=q.front();
q.pop();
for(int v=1;v<=ns;v++)
{
if(G[u][v]&&!mark_right[v])//如果课程与学生对应 并且当前学生没有被遍历
{
mark_right[v]=1;
if(rights[v]==-1)
{
ok=1;
//更新匹配关系
int sl=u,sr=v;
while(sl!=0)
{
int st=lefts[sl];
lefts[sl]=sr;rights[sr]=sl;
sl=pre_left[sl];sr=st;
}
break;
}
else
{
pre_left[rights[v]]=u;//记录课程的前驱
q.push(rights[v]);
}
}
}
if(ok)
break;
}
if(ok) maxf++;
}
/*
for(int i=1;i<4;i++)
cout<<lefts[i]<<" "<<rights[i]<<endl;
*/
return maxf;
}
int main()
{
int num;
scanf("%d",&num);
while(num--)
{
memset(G,0,sizeof(G));
scanf("%d%d",&nc,&ns);
for(int i=1;i<=nc;i++)
{
int snum;
scanf("%d",&snum);
int u;
for(int j=1;j<=snum;j++)
{
scanf("%d",&u);
G[i][u]=1;
}
}
if(max_match()==nc)
{
printf("YES\n");
}
else
{
printf("NO\n");
}
/*
cout<<"最大匹配数是:"<<max_match()<<endl;
cout<<"对应的匹配关系是:"<<endl;
for(int i=1;i<=nc;i++)
{
cout<<i<<" "<<lefts[i]<<endl;
}
cout<<"!!!!!!!!!!!!!!"<<endl;
for(int i=1;i<=ns;i++)
{
cout<<rights[i]<<" "<<i<<endl;
}*/
}
return 0;
}
code3:
#include<iostream>
#include<queue>
using namespace std;
const int MAXN=500;// 最大点数
const int INF=1<<28;// 距离初始值
int bmap[MAXN][MAXN];//二分图
int cx[MAXN];//cx[i]表示左集合i顶点所匹配的右集合的顶点序号
int cy[MAXN]; //cy[i]表示右集合i顶点所匹配的左集合的顶点序号
int nx,ny;
int dx[MAXN];
int dy[MAXN];
int dis;
bool bmask[MAXN];
//寻找 增广路径集
bool searchpath()
{
queue<int>Q;
dis=INF;
memset(dx,-1,sizeof(dx));
memset(dy,-1,sizeof(dy));
for(int i=1;i<=nx;i++)
{
//cx[i]表示左集合i顶点所匹配的右集合的顶点序号
if(cx[i]==-1)
{
//将未遍历的节点 入队 并初始化次节点距离为0
Q.push(i);
dx[i]=0;
}
}
//广度搜索增广路径
while(!Q.empty())
{
int u=Q.front();
Q.pop();
if(dx[u]>dis) break;
//取右侧节点
for(int v=1;v<=ny;v++)
{
//右侧节点的增广路径的距离
if(bmap[u][v]&&dy[v]==-1)
{
dy[v]=dx[u]+1; //v对应的距离 为u对应距离加1
if(cy[v]==-1) dis=dy[v];
else
{
dx[cy[v]]=dy[v]+1;
Q.push(cy[v]);
}
}
}
}
return dis!=INF;
}
//寻找路径 深度搜索
int findpath(int u)
{
for(int v=1;v<=ny;v++)
{
//如果该点没有被遍历过 并且距离为上一节点+1
if(!bmask[v]&&bmap[u][v]&&dy[v]==dx[u]+1)
{
//对该点染色
bmask[v]=1;
if(cy[v]!=-1&&dy[v]==dis)
{
continue;
}
if(cy[v]==-1||findpath(cy[v]))
{
cy[v]=u;cx[u]=v;
return 1;
}
}
}
return 0;
}
//得到最大匹配的数目
int MaxMatch()
{
int res=0;
memset(cx,-1,sizeof(cx));
memset(cy,-1,sizeof(cy));
while(searchpath())
{
memset(bmask,0,sizeof(bmask));
for(int i=1;i<=nx;i++)
{
if(cx[i]==-1)
{
res+=findpath(i);
}
}
}
return res;
}
int main()
{
int num;
scanf("%d",&num);
while(num--)
{
memset(bmap,0,sizeof(bmap));
scanf("%d%d",&nx,&ny);
for(int i=1;i<=nx;i++)
{
int snum;
scanf("%d",&snum);
int u;
for(int j=1;j<=snum;j++)
{
scanf("%d",&u);
bmap[i][u]=1;
// bmap[u][i]=1;
}
}
// cout<<MaxMatch()<<endl;
if(MaxMatch()==nx)
{
printf("YES\n");
}
else
{
printf("NO\n");
}
}
//system("pause");
return 0;
}
/*















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









