







Abstract
本文贡献:
- 研究条件对抗网络作为一个通用的解决图像到图像的翻译问题的方案。
- 不仅学习从输入图像到输出图像的映射,而且学习一个损失函数来训练这种映射。
结果:
- 使得对传统上需要不同的损失公式的问题采用相同的普遍方法成为可能。
1. Introduction
- 将自动的图像到图像翻译定义为,在给定足够训练数据的情况下,将场景的一种可能表示转换为另一种可能表示的问题。

- predict pixels from pixels
- CNN 学习最小化损失函数,即对结果质量进行评分的目标——尽管学习过程是自动的,但仍需要大量手动工作来设计有效的损失。迫使 CNN 做我们真正想要的损失函数——例如,输出清晰、逼真的图像。
- GANs学习一个损失,试图分类输出图像是真是假,同时训练生成模型,以尽量减少这种损失。由于GANs学习的是与数据相适应的损失,因此它们可以应用于传统上需要不同类型的损失函数的大量任务。
- cGANs学习条件生成模型。这使得cGAN适合于图像到图像的转换任务,其中对输入图像进行条件处理并生成相应的输出图像。
2. Related work
Structured losses for image modeling——图像建模中的结构损失:
- 传统Image-to-image translation方法将输出空间视为“非结构化”的,即每个输出像素被视为有条件地独立于所有其他像素。
- cGANs是结构化损失。结构化损失对输出的联合配置进行惩罚。
- 大量文献考虑了此类损失,方法包括条件随机场、SSIM度量、特征匹配、非参数损失、卷积伪先验和基于匹配协方差统计的损失。
- cGANs的不同之处在于,损失是学习的,理论上,GAN可以惩罚输出和目标之间任何可能存在差异的结构。
Conditional GANs——条件GANs:
- 本文框架的不同之处在于没有特定于应用程序的内容。这使得设置比大多数其他设置简单得多。
- 本文的生成器使用了基于“U-Net”的架构 ,判别器则使用了卷积“PatchGAN”分类器,它只对图像块级别的结构进行惩罚。
- 类似的PatchGAN架构曾被提出,旨在捕捉局部风格统计信息。
- 本文展示了这种方法在更广泛的问题上是有效的,并探讨了改变块大小的影响。
3. Method
- GANs 学习从随机噪声向量z到输出图像y的映射,表示为 G : z → y G: z \rightarrow y G:z→y 。
- cGANs 学习从观测到的图像x和随机噪声向量z到图像y的映射,表示为 G : { x , z } → y G: \{x, z\} \rightarrow y G:{ x,z}→y 。
- 生成器G被训练生成的输出不能被对抗性训练的判别器D区分为“假”图像,而判别器D则被训练尽可能准确地检测出生成器的“伪造”图像。
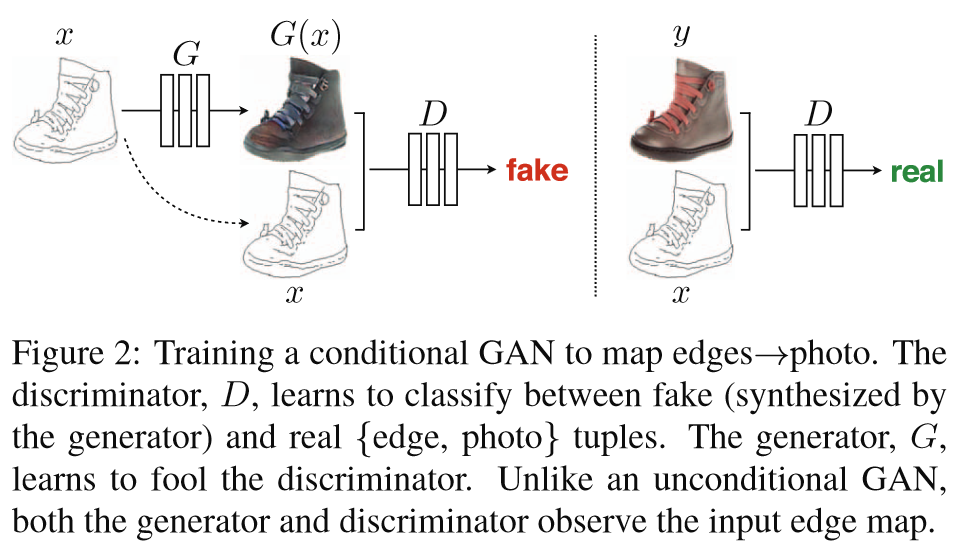
3.1 Objective——目标
cGANs的目标函数:
L c G A N ( G , D ) = E x , y [ log D ( x , y ) ] + E x , z [ log ( 1 − D ( x , G ( x , z ) ) ) ] L_{cGAN}(G, D) = \mathbb{E}_{x,y}[\log D(x, y)] + \mathbb{E}_{x,z}[\log(1 - D(x, G(x, z)))] LcGAN(G,D)=Ex,y[log
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3350
3350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









