






在图像分类的研究中,ImageNet具有着十分特殊的意义。其事专门针对于深度学习而提出的数据集,比机器学习的数据集(MNIST、CIFAR、SVHN、Fashion-MNIST等)要大很多。在其官网上也只是原始的图片数据集,单单是ILSVRC2012的训练集都有100多G。因此把图片放入网络并不合适。Tensorflow中也提供了将数据集处理成TfRecord类型的数据,也有人提出了如何进行处理。
1、数据集下载
有两种方法可以下载数据,
第一去官网,但是官网一般需要注册。
http://www.image-net.org/challenges/LSVRC/2012/
第二是去别人提供的网站下载:https://blog.csdn.net/qq_20481015/article/details/82912590。
其包含如下:

复制下面的连接到迅雷中,即可下载。速度嗨可以,但是会花一段时间。
2、脚本下载
tensorflow官方提供了生成Tfrecord的方法。可以通过以下方式下载:
git clone https://github.com/tensorflow/models.git
有人提出了放在目录:/models/research/slim (https://blog.csdn.net/Gavin__Zhou/article/details/80242998)
也有学者认为放在目录:/models/research/inception/inception/data (https://blog.csdn.net/hustlx/article/details/76585843)
事实上,都是需要如下文件:
preprocess_imagenet_validation_data.py #处理val的数据
process_bounding_boxes.py #处理boundingbox数据
build_imagenet_data.py #构建数据集主程序
imagenet_lsvrc_2015_synsets.txt
imagenet_2012_validation_synset_labels.txt
imagenet_metadata.txt
3、数据处理
-生成Tfrecord数据
参考 http://www.image-net.org/challenges/LSVRC/2012/。
假设数据存放在 models/research/slim/ImageNet-ori 目录下,TFRecord文件的输出目录是 models/research/slim/ILSVRC2012/output,当前目录是 models/research/slim。
# 创建相关目录
mkdir -p ILSVRC2012
mkdir -p ILSVRC2012/raw-data
mkdir -p ILSVRC2012/raw-data/imagenet-data
mkdir -p ILSVRC2012/raw-data/imagenet-data/bounding_boxes
# 做bounding box数据
tar -xvf ImageNet-ori/ILSVRC2012_bbox_train_v2.tar.gz -C ILSVRC2012/raw-data/imagenet-data/bounding_boxes/
python process_bounding_boxes.py ILSVRC2012/raw-data/imagenet-data/bounding_boxes/ imagenet_lsvrc_2015_synsets.txt | sort > ILSVRC2012/raw-data/imagenet_2012_bounding_boxes.csv
生成imagenet_2012_bounding_boxes.csv文件,为最后的数据处理做准备。
# 做验证集(解压时间久)
mkdir -p ILSVRC2012/raw-data/imagenet-data/validation/
tar xf ILSVRC2012_img_val.tar -C ILSVRC2012/raw-data/imagenet-data/validation/
python preprocess_imagenet_validation_data.py ILSVRC2012/raw-data/imagenet-data/validation/ imagenet_2012_validation_synset_labels.txt
将validation的图片于标签对应,分别放入不同的文件夹中。

共1000类,每一个文件内都包含50个JEPG图片。
由于训练集是两重的tar压缩包,因此操作不同于验证集。
# 做训练集(解压时间更久,保持耐心!)
mkdir -p ILSVRC2012/raw-data/imagenet-data/train/
# 将训练集复制到 ILSVRC2012/raw-data/imagenet-data/train/ 下,而后 cd 到此目录下进行处理
mv ImageNet-ori/ILSVRC2012_img_train.tar ILSVRC2012/raw-data/imagenet-data/train/ && cd ILSVRC2012/raw-data/imagenet-data/train/
# 解压ILSVRC2012_img_train.tar
tar -xvf ILSVRC2012_img_train.tar
# 将原始的ILSVRC2012_img_train.tar移动回原先的位置ImageNet-ori。此处应填写自己的目录
mv ILSVRC2012_img_train.tar ../../../ImageNet-ori/
# 将每一个子-tar文件解压,分别放入对应的子文件夹下
find . -name "*.tar" | while read NAE ; do mkdir -p "${NAE%.tar}"; tar -xvf "${NAE}" -C "${NAE%.tar}"; rm -f "${NAE}"; done
生成的训练集。
# 执行准换,注意移动到models/research/slim下,执行如下命令
python build_imagenet_data.py --train_directory=ILSVRC2012/raw-data/imagenet-data/train --validation_directory=ILSVRC2012/raw-data/imagenet-data/validation --output_directory=ILSVRC2012/output --imagenet_metadata_file=imagenet_metadata.txt --labels_file=imagenet_lsvrc_2015_synsets.txt --bounding_box_file=ILSVRC2012/raw-data/imagenet_2012_bounding_boxes.csv
最后生成TFrecord数据:
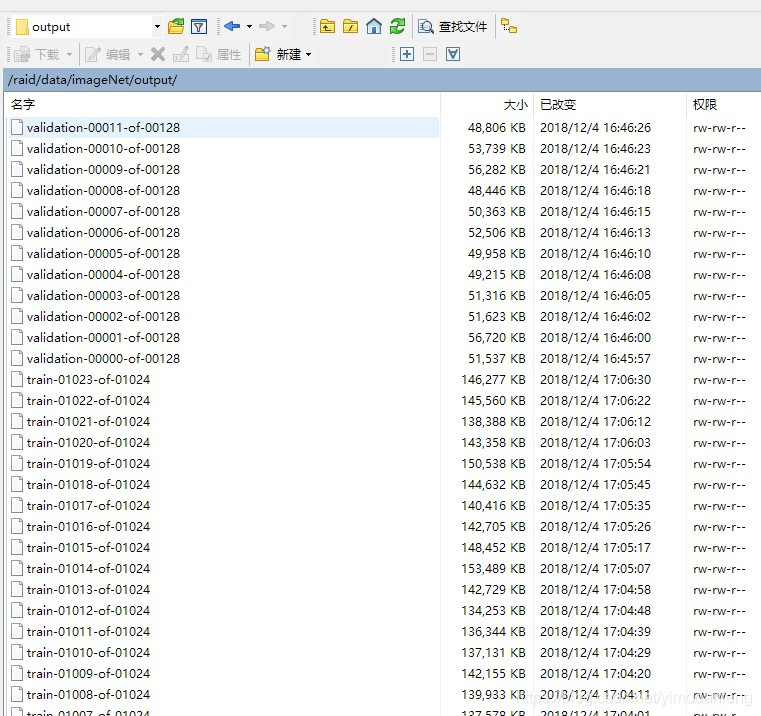
共128个验证集(0-127),1024个训练集(0-1023)。
-报错事宜
mv ILSVRC2012_img_train.tar ../../../ImageNet-ori/
很容易报错,必须要把原始数据集移动走。
最后的数据转换代码,必须用
python
# 而不是python3
,不然会报错。此外,将build_imagenet_data.py中第530 行的 代码
# 从shuffled_index = len(filenames)改成
shuffled_index = range(len(filenames))
-其他处理方法制作.py文件
在最后一步前,自己编写代码进行遍历操作。使用
cv2
Image (from PIL import Image )

















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









