






1.1 全文检索
1.1.1 Lucene词汇表和架构
这里主要介绍了ElasticSearch的基本概念
文档/字段/词/标记
这是基本的存储结构,类似于mysql数据库的数据库、数据表、行、列
1.1.2 输入数据分析
输入ElasticSearch的数据中在转化成倒排索引的时候,会采用分析器进行分析。
这些过滤器:小写过滤器、同义词过滤器、多语言词干提取过滤器
1.1.3 评分和查询相关性
采用TF-IDF评分
1.2 ElasticSearch基础
1.2.2 ElasticSearch基本概念
节点
一台服务器
集群
多台服务器
分片
数据分身
副本
数据的主分身和次分身
时光之门
操控集群状态
1.3 安装集群
略过,反正到时候又要重新检索
ElasticSearch内部布局:
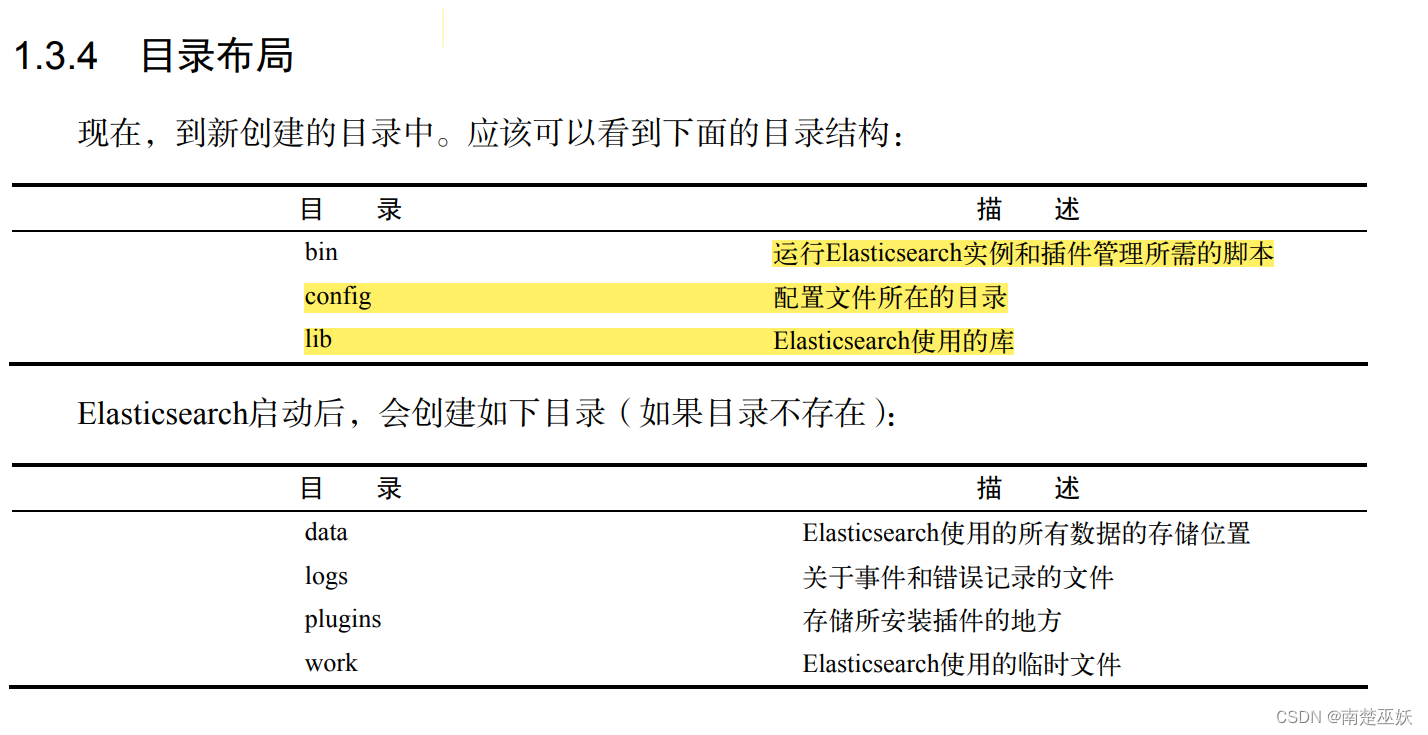
elasticsearch的配置目录:
elasticsearch.yml 服务器的默认配置值,这里cluster.name属性保存集群的名字和node.name是实例(该节点)的名字
cluster.name属性保存集群的名字
node.name是实例(该节点)的名字
logging.yml 定义了多少信息写入系统日志,定义了日志文件,并定期创建新
文件。只有在调整监控、备份方案或系统调试时
Elasticsearch实例的Java虚拟机(JVM)的堆内存限制,默认内存是1024M,但是有时候实验的时候可以修改一下,我是直接改成256M。
默认是通常不应该分配超过50%的系统总内存。
1.3.7 关闭ElasticSearch
(1)如果节点是连接到控制台,按下Ctrl+C。
(2) 第二种选择是通过发送TERM信号杀掉服务器进程(参考Linux上的kill命令和Windows
上的任务管理器)。
(3) 第三种方法是使用REST API。
1.4 用 REST API 操作数据/1.5 检索数据
采用各种手段对数据增删改查
对数据增删改查的各种手段
URI查询中的字符参数
(1)参数q用来指定我们希望文件匹配的查询条件。
(2) 默认查询字段
使用df参数,可以指定在q参数中没有字段时应该默认使用的字段。
(3) 分析器
可以将analyzer属性定义用于分析查询的分析器名称。
(4) 默认操作符
Default_operator属性可以设置成OR或AND,用来指定用于查询的默认布尔运算符。
(5) 查询解释
如果将explain参数设置为true,Elasticsearch将在结果的每个文档里包括额外的解释信息,如文档是从哪个分片上获取的、计算得分的详细信息(5.7节将深入讨论)。
尽量不用
(6)返回字段
默认情况下,返回的每个文档中,Elasticsearch将包括索引名称、类型名称、文档标识符、得分和_source字段。我们可以修改这个行为,通过添加fields参数并指定一个以逗号分隔的字段名称列表。这些字段将在存储字段(如果存在的话)或内部_source字段中检索。
(7) 结果排序
通过使用sort参数,可以指定自定义排序。Elasticsearch的默认行为是把返回文档按它们的得分降序排列。如果想有不同的排序,则需要指定sort参数。例如,添加sort=published:desc,文档将按published字段降序排序;添加sort=published:asc
(8) 搜索超时
默认情况下,Elasticsearch没有查询超时,但你可能希望查询在一段时间(比如5秒)后超时。
(9) 查询结果窗口
Elasticsearch允许你指定结果窗口(应返回的结果列表中文件的范围)。有两个参数用来指定结果窗口大小:size和from。
(10) 搜索类型
URI查询允许使用search_type参数指定搜索类型,搜索类型默认为query_then_fetch。
我们可以使用以下6个值:
(11) 小写扩展词
一些查询使用查询扩展,比如前缀查询(prefix query)
(12) 分析通配符和前缀
默认情况下,通配符查询和前缀查询不会被分析。
















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











