









对于用户而言,推荐系统和搜索引擎是两个互补工具。搜索引擎满足有明确目标的用户需求,而推荐系统能够帮助用户发现其感兴趣的内容。
如今网上信息泛滥,想要在里面找一条适合自己的信息的成本真的有点高,所以就有了推荐系统。于用户而言,推荐系统能够节省自己的时间;于商家而言,推荐系统能够更好的卖出自己的商品。
基于邻域的推荐算法是推荐系统中最基本的算法,该算法分为两大类:基于用户的协同过滤算法(UserCF)和基于物品的协同过滤算法(ItemCF)。相比于基于用户的协同过滤算法,基于物品的协同过滤算法在工业界应用更多,因为基于用户的协同过滤算法主要有两个缺点:
1.随着网站的用户数目越来越大,计算用户数的相似度将会越来越困难,其运算的时间复杂度和空间复杂度基本和用户的增长数成平方关系
2.基于用户的协同过滤算法很难对推荐结果做出解释
本项目的目标是采用协同过滤算法对用户进行推荐,来帮助用户从海量数据中快速发现感兴趣的网页。
分析过程包括如下内容:
- 从系统中获取用户访问网站的原始记录;
- 对数据进行多维度分析,包括用户访问内容,流失用户分析以及用户分类等;
- 对数据进行预处理
- 以用户访问html后缀的网页为关键条件,对数据进行处理;
- 对比多种推荐算法进行推荐,通过模型评价得到比较好的智能推荐模型,对数据进行预测
从数据库导入数据
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqlconnector://root:liuying0131@localhost:3306/ch12law')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)数据探索-网页类型统计
counts = [ i['fullURLId'].value_counts() for i in sql] #逐块统计
counts = pd.concat(counts).groupby(level=0).sum()
#level=0,表明合并统计结果,把相同的统计项合并(即按index分组并求和);concat首尾相接,表示将所有的counts上下连接起来
counts = counts.reset_index() #重新设置index,将原来的index作为counts的一列。
counts.columns = ['index', 'num'] #重新设置列名,主要是第二列,默认为0
counts['type'] = counts['index'].str.extract('(\d{3})') #提取前三个数字作为类别id
counts_ = counts[['type', 'num']].groupby('type').sum() #按类别合并
counts_['ratio']=counts_/counts_.sum() #增加比例列
counts_.sort_values('num', ascending = False) #降序排列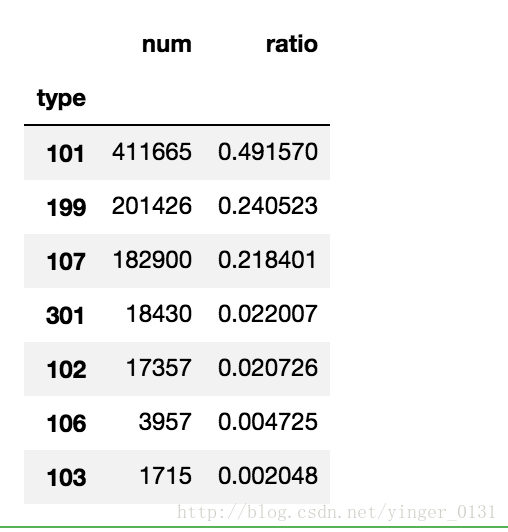
101咨询相关占据几乎一半的比例。
统计类别的函数
#统计其他类别的情况
def counts_type(type):
counts_type=counts[counts['type']==type][['index', 'num']]
counts_type['ratio']=counts_type['num']/counts_type['num'].sum()
return counts_type.sort_values('num', ascending = False)
counts_type('102') #统计107类别的情况
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
def count107(i): #自定义统计函数
j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() #找出类别包含107的网址
j['type'] = None #添加空列
j['type'][j['fullURL'].str.contains('info/.+?/')] = u'知识首页'
j['type'][j['fullURL'].str.contains('info/.+?/.+?')] = u'知识列表页'
j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')] = u'知识内容页'
return j['type'].value_counts()
counts2 = [count107(i) for i in sql] #逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() #合并统计结果
ratio= counts2/counts2.sum()
pd.DataFrame([counts2,ratio]).T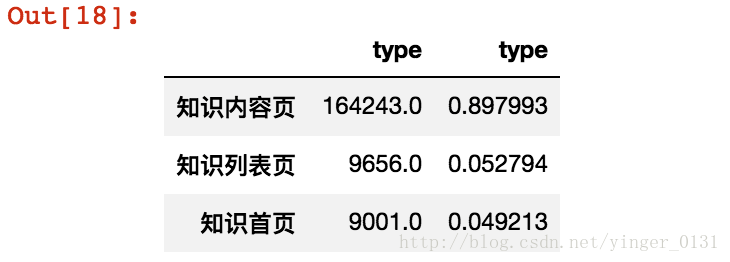
在查看数据过程中发现有的用户没有单机具体的页面(html结尾),他们单机的大部分是目录网页,这样的用户行为可以称为“瞎逛”。
#瞎逛统计
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
counts5 = [ i['fullURLId'][(i['fullURL'].str.contains('html'))==0].value_counts() for i in sql]#没有点击以html结尾的具体页面
counts5= pd.concat(counts5).groupby(level=0).sum()
counts5 = pd.DataFrame(counts5)
counts5['type'] = counts5.index.str.extract('(\d{3})') #提取前三个数字作为类别id
counts5_ = counts5[['type', 'fullURLId']].groupby('type').sum()#按类别合并
counts5_['ratio']=counts5_/counts5_.sum() #增加比例列
counts5_.sort_values('fullURLId', ascending = False) #按类型编码顺序排序 #点击次数统计
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
c = [i['realIP'].value_counts() for i in sql] #统计各个IP出现次数
count6 = pd.concat(c).groupby(level=0).sum() #合并统计结果
count6 = pd.DataFrame(count6) #将Series转为DataFrame
count6[1] = 1 #添加一列全为1
count6_=count6.groupby('realIP').sum() #统计各个不同点击数 出现的次数
count6_['ratio1']=count6_[1]/count6_[1].sum()
count6_['ratio2']=count6_[1]*count6_.index/(count6_[1]*count6_.index).sum()
count6_.head(10)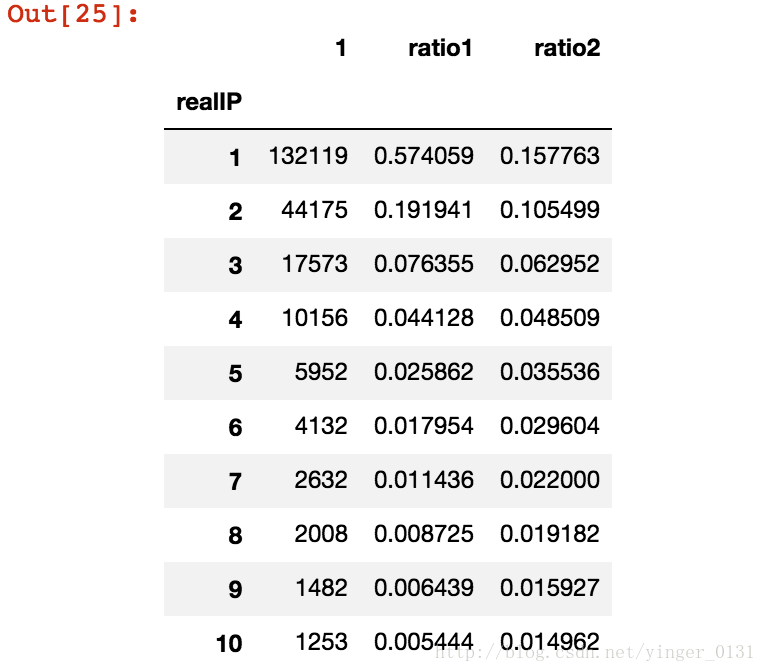
可以看出80%的用户只提供了30%的浏览量,点击次数最大值为42790次,是律师浏览的信息。
数据预处理
for i in sql:
d = i[['realIP', 'fullURL']] #只要网址列
d = d[d['fullURL'].str.contains('\.html')].copy() #只要含有.html的网址
#保存到数据库的cleaned_gzdata表中(如果表不存在则自动创建)
d.to_sql('cleaned_gzdata', engine, index = False, if_exists = 'append')由于用户在浏览网页时存在翻页情况,不同的网址属于同一类型的网页,针对这些网页需要还原其原始类别。
for i in sql: #逐块变换并去重
d = i.copy()
d['fullURL'] = d['fullURL'].str.replace('_\d{0,2}.html', '.html') #将下划线后面部分去掉,规范为标准网址
d = d.drop_duplicates() #删除重复记录
d.to_sql('changed_gzdata', engine, index = False, if_exists = 'append') #保存
因为目标是为用户提供个性化推荐,在处理数据过程中要进一步对数据进行分类。
sql = pd.read_sql('changed_gzdata', engine, chunksize = 10000)
for i in sql: #逐块变换并去重
d = i.copy()
d['type_1'] = d['fullURL'] #复制一列
d['type_1'][d['fullURL'].str.contains('(ask)|(askzt)')] = 'zixun' #将含有ask、askzt关键字的网址的类别一归为咨询(后面的规则就不详细列出来了,实际问题自己添加即可)
d.to_sql('splited_gzdata', engine, index = False, if_exists = 'append') #保存
模型构建
结合数据特点:网页数明显小于用户数,本项目采用基于物品的协同过滤推荐系统对用户进行个性化推荐,以推荐结果作为推荐系统结果的重要部分。
主要分为两步:
- 计算物品之间的相似度;
- 根据物品相似度和用户的历史行为给用户生成推荐列表
由于用户行为是二元选择(0或者1),此处选择采用杰卡德相似系数法计算物品的相似度。
import numpy as np
def Jaccard(a, b): #自定义相似系数
return 1.0*(a*b).sum()/(a+b-a*b).sum()
class Recommender():
sim = None #相似度矩阵
def similarity(self, x, distance): #计算相似度矩阵的函数
y = np.ones((len(x), len(x)))
for i in range(len(x)):
for j in range(len(x)):
y[i,j] = distance(x[i], x[j])
return y
def fit(self, x, distance = Jaccard): #训练函数
self.sim = self.similarity(x, distance)
def recommend(self, a): #推荐函数
return np.dot(self.sim, a)*(1-a) 














 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









