







 本文详细介绍了GPU的发展历程、数据并行架构,特别是SIMD执行模式,以及GPU的效率影响因素如占用率和动态分支。此外,阐述了GPU管线的概念与实现,强调了可编程着色阶段的重要特性,包括统一指令集、输入类型和操作。最后,提及了着色器阶段的演变和相关编程API的发展。
本文详细介绍了GPU的发展历程、数据并行架构,特别是SIMD执行模式,以及GPU的效率影响因素如占用率和动态分支。此外,阐述了GPU管线的概念与实现,强调了可编程着色阶段的重要特性,包括统一指令集、输入类型和操作。最后,提及了着色器阶段的演变和相关编程API的发展。

一、Chapter3——The Graphics Processing Unit
(一)Background
the history of GPU and
Waiting for data to be retrieved means the processor is stalled, which reduces performance.
(二)Data-Parallel Architectures
1、About the stalling of the processor :
CPU : To minimize the effect of latency, much of a CPU’s chip consists of fast local caches, memory that is filled with data likely to be needed next. CPUs also avoid stalls by using clever techniques such as branch prediction, instruction reordering, register renaming, and cache prefetching.
GPU : Much of a GPU’s chip area is dedicated to a large set of processors, called shader cores, often numbering in the thousands.in which ordered sets of similar data are processed in turn.The GPU is optimized for throughput.
But, The approach of the GPU has a cost : With less chip area dedicated to cache memory and control logic, latency for each shader core is generally considerably higher than what a CPU processor encounters. A memory fetch like texture can take hundreds to thousands of clock cycles, during which time the GPU processor is doing nothing.
2、single instruction, multiple data(SIMD)
Thread consists of a bit of memory for the input values to the shader, along with any register space needed for the shader’s execution.——2000 threads deal with 2000 tasks.
Wrap : Threads that use the same shader program are bundled into groups, called warps by NVIDIA and wavefronts by AMD.
A wrap is a group of threads. and one thread deal with a task in a group.
Swap : a warp, a group contain 32 tasks, and there 32 processors ( threads ) perform 32 tasks, when stalling , they will swap out for another warp or group to perform.
Return : when swaping to the end group, the threads will return to first group (this time stalling is over.)
SIMD executes the same command in lock-step on a fixed number of shader programs. The advantage of SIMD is that considerably less silicon (and power) needs to be dedicated to processing data and switching.
3、 influences efficiency.
Occupancy : the number of thread refer to how many thread could be resident on GPU at one time.
Dynamic Branching : if statement
(三)GPU Pipeline Overview
1、Conceptual(functional stage) & Implement(physical stages)
functional stage :
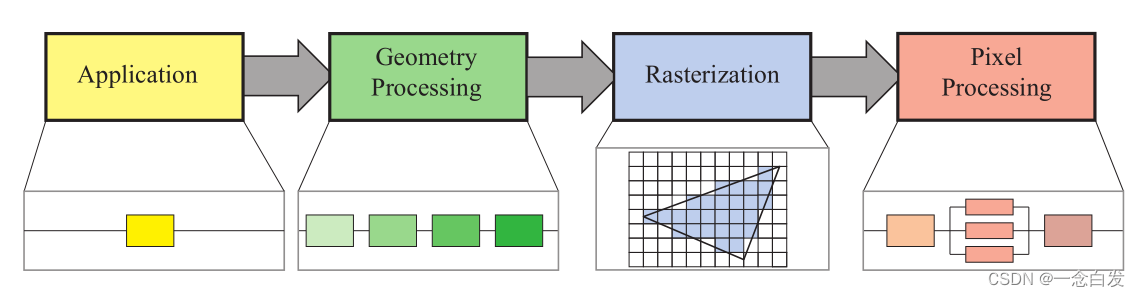
physical stages :

The GPU implements the conceptual pipeline stages.
2、Logical Model & Physical Model
We describe here the logical model(implementation above) of the GPU, the one that is exposed to you as a programmer by an API. The implementation of this logical pipeline, the physical model, is up to the hardware vendor.
(四)The Programmable Shader Stage
1、ISA :
Modern shader programs use a unified shader design. Internally they have the same instruction set architecture (ISA).
architecture: shader processors are usable in a variety of roles, and the GPU can allocate these as it sees fit.
2、two types of inputs :
Each programmable shader stage has two types of inputs: uniform inputs and varying inputs.
3、registers
The underlying virtual machine provides special registers for the different types of inputs and outputs. temporary registers & Varying Input Registers & temporary registers
4、Operations
operators such as * and +
intrinsic functions, e.g., atan(), sqrt(), log()
5、 flow control
Static flow control branches are based on the values of uniform inputs.
Dynamic flow control is based on the values of varying inputs, meaning that each fragment can execute the code differently.
(五)The Evolution of Programmable Shading and APIs
略


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









