







首先为了方便,我大概在博友林子的博客基础上进行编辑,今天我将跳跃表实现了一下,算法导论公开课的那位年轻教授说他花了半个小时写好半个小时调试好,我的时间估计是他的4倍吧,只有结构实现看了这篇博客的插入代码,了解了只需要在n空间大小构建跳跃表的结构。对于自己几乎独立的实现了这个算法,虽然简单,但是还是很有成就感的。需要自己注意的是在独立实现代码的时候不仅仅只是需要简单的了解大概的算法,而是
1)确定需要使用的数据结构,如今天的代码中的SKNode, SkipList.
2)如何初始化这个数据结构,这样才能得到求解问题循环结束条件。(初始化条件很重要)
3)先自己按照算法流程,插入、查找、删除一个一个写好伪代码,这样才不至于在写代码的时候没有关注点,思维混乱。可以先从最简单也是最和核心的查找算法写起。
4)最后是调试,碰到不对的步骤,可以添加打印,我现在对于数据结构还有太底层的调试时看不出来太多信息的,只能一步一步的试探。这也是一个软肋,以后有空一定要再学学编程范式这种比较底层的东西,还有内存管理也很重要。
参考的博文地址如:
跳跃链表简介
二叉树是一种常见的数据结构。它支持包括查找、插入、删除等一系列操作。但它有一个致命的弱点,就是当数据的随机性不够时,会导致其树形结构的不平衡,从而直接影响算法的效率。
跳跃链表(Skip List)是1987年才诞生的一种崭新的数据结构,它在进行查找、插入、删除等操作时的期望时间复杂度均为O(logn),有着近乎替代平衡树的本领。而且最重要的一点,就是它的编程复杂度较同类的AVL树,红黑树等要低得多,这使得其无论是在理解还是在推广性上,都有着十分明显的优势。
跳跃链表的最大优势在于无论是查找、插入和删除都是O(logn),不过由于跳跃链表的操作是基于概率形成的,那么它操作复杂度大于O(logn)的概率为,可以看出当n越大的时候失败的概率越小。
另外跳跃链表的实现也十分简单,在平衡树中是最易实现的一种结构。例如像复杂的红黑树,你很难在不依靠工具书的帮助下实现该算法,但是跳跃链表不一样,你可以很容易在半个小时内就完成其实现。
跳跃链表的空间复杂度的期望为O(n),链表的层数期望为O(logn).
如何改进普通的链表?
我们先看看一个普通的链表

可以看出查询这个链表O(n),插入和删除也是O(n).因此链表这种结构虽然节省空间,但是效率不高,那有没有什么办法可以改进呢?
我们可以增加一条链表做为快速通道。这样我们使用均匀分布,从图中可以看出L1层充当L0层的快速通道,底层的结点每隔固定的几个结点出现在上面一层。

我们这里主要以查找操作来介绍,因为插入和删除操作主要的复杂度也是取决于查找,那么两条链表查找的最好的时间复杂度是多少呢?
一次查找操作首先要在上层遍历<=|L1|次操作,然后在下层遍历<=(L0/L1)次操作,至多要经历

次操作,其中|L1|为L1的长度,n为L0的长度.
那么最好的时间复杂度,也就怎么设置间隔距离才能使查找次数最少有
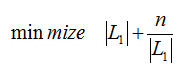
我们对|L1|的长度求导得
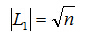
把上式代入函数,查找次数最小也就是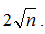
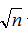
那么三条链表呢

同理那么我们让L2/L1=L1/L0,然后同样列出方程,求导可得L2=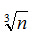
........................................................................
第k条链条.....查找次数为
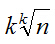
我们这里取k=logn,代入的查找次数为2logn.
到此为主,我们应该知道了,期望上最好的层数是logn层,而且上下层结点数比为2,这样查找次数常数最小,复杂度保持在O(logn)。
跳跃链表的结构
跳跃表由多条链构成(L0,L1,L2 ……,Lh),且满足如下三个条件:
- 每条链必须包含两个特殊元素:+∞ 和 -∞(可以需要,可以不需要,我的实现是采用了-∞作为header之后的 节点,即第一个节点,+∞作为最后一个节点)
- L0包含所有的元素,并且所有链中的元素按照升序排列。
- 每条链中的元素集合必须包含于序数较小的链的元素集合。
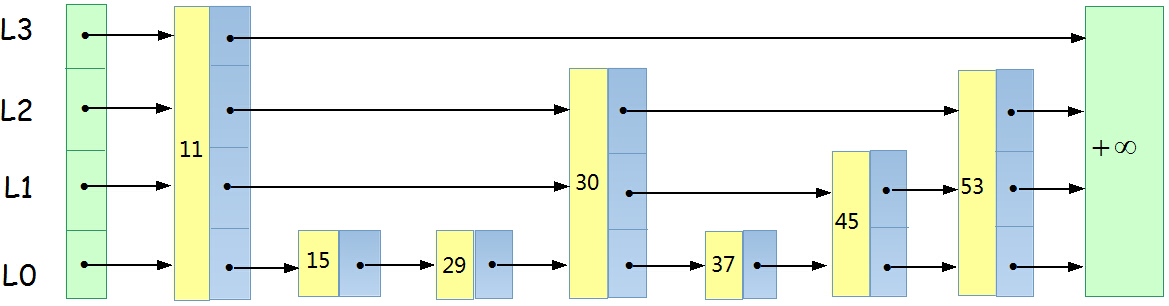
结点结构源代码
我觉得如果不考虑空间效率是可以将数据在每层上面分开存储,但是也可以办到在一个n的空间存储,跳跃表就是在这些数据之间建立links,使用links替代树形结构,如Btreap树堆,R-B Trees, AVL trees。 现在我给的是基于一个n空间存储。

class SKNode
{
public:
int key;
SKNode* forward[MAXLEVEL];
SKNode()
{
key=0;
for(int i =0;i<MAXLEVEL;i++)
{
forward[i]= NULL;
}
}
SKNode& operator=(const SKNode* & node)
{
key=node->key;
for(int i=0;i<MAXLEVEL;i++)
{
forward[i] = node->forward[i];
}
return *this;
}
};
//skip list, it has a header, this header have maxlevel pointers
class SkipList
{
public:
SKNode *hdr; /* list Header */
int listLevel; /* current level of list */
int insert(int key);
SKNode* search(int key);
int deleteNode(int key);
void printList();
SkipList()
{
hdr = new SKNode;
listLevel = 0;
hdr->key = -INT_MAX;
SKNode* end = new SKNode;
SKNode* first = new SKNode;
first->key=-INT_MAX;
end->key=INT_MAX;
for(int i =0;i<MAXLEVEL;i++)
{
hdr->forward[i]=first;
hdr->forward[i]->forward[i] = end;
}
printList();
}
~SkipList()
{
delete hdr;
}
};
跳跃链表查找操作
目的:在跳跃表中查找一个元素x
在跳跃表中查找一个元素x,按照如下几个步骤进行:
1、 p = hdr; 从最上层的链(Lh)的开头开始,进入到各层
2、 for i(listLevel-1, 0) , 从最上层的链(Lh)的开头开始, 如L3到L0
3、假设当前位置为p,p初始值为hdr, p在i层的下一个节点为q = p->forward[i], 它向右指向的节点为q(p与q不一定相邻)。将x和q.key做比较
(1)if x>q.key 在i层继续向右走,
then p = p->forward[i].
(2) else x<=q.key,
then i--, 即将当前指针直接下移到下一层。
for循环结束,i变为了0, 即在最后一层, p = p->foward[0]
4、判断p,
(1) if p!= NULL && p->key = x
return p
(2) return NULL
如我们查找29, 先从入口到l3,29>11,p = 11, 判断知道往下走L2,29<30, 继续往下L1,29<30,L1,29>15, 前进,29<=29, 结束, p在15的位置,所以最后指针调整到p = p->forward[0], 判断p值。
(今天因为我从listLevel开始,浪费了好多调试时间。。。。)
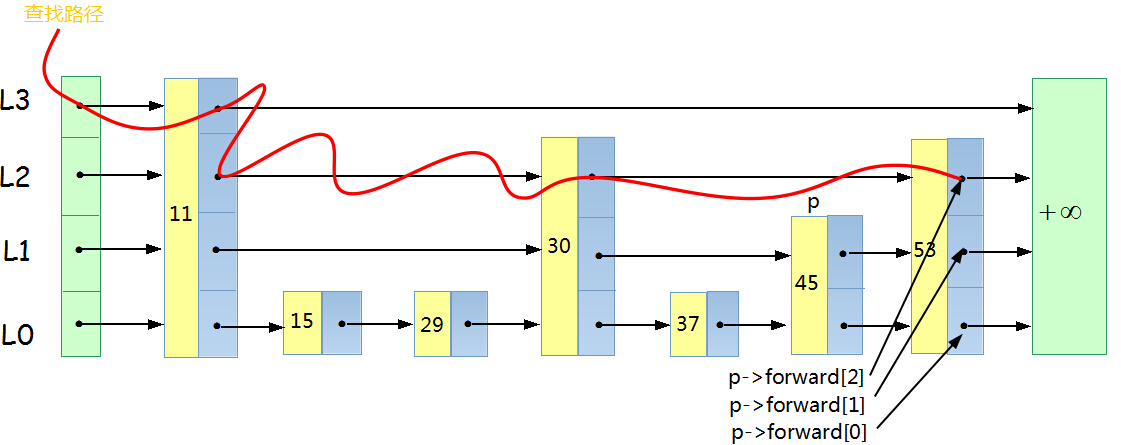
元素53的查找路径
下面是C++实现代码:
SKNode* SkipList::search(int key)
{
SKNode* current = new SKNode;
current = hdr;
int i = listLevel-1;
for(;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
//否则i--,转到下一层
}
current = current->forward[0];
if(current!= NULL && current->key == key)
{
cout<<"find"<<key<<endl;
return current;
}
return NULL;
}
跳跃链表插入操作
目的:向跳跃表中插入一个元素x
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
1)关于在L0层的插入的位置,我们先利用跳跃表的查找功能, x<=q.key,所以x的位置一定是在x之后,q之前。 同样可以推论在L1,L2 ,L listLevel层的位置是在循环中生成他们这层最后的位置,就是在search的while之后记录一个这个位置为S[i]。最后需要在所有的S[i]之后重连数据之间的链接。 (但是需要注意的是为了,如果我们不想加入重复数据,需要判断p->forward[0]的值,如果相等,就是找到了,不需要再插入。当然如果我们不介意重复数据,也可以不加这个判断。)
2)需要插入的高度,决定在L1-listLevel的哪些位置加。 而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
伪代码如下:
Skip List Insertion(x)
p = hdr;
newlevel = getlevel();
s[listLevel] = hdr(注意需要全部初始化为hdr,为了newlevel增长了,但是增长的层次s[i]却没有数据,没有初始化,应该从头结点开始)
for i(listLevel-1, 0)
while(q!=+∞ && x>key)
then p = p->forward[i].
//else x<=q.key,
//then i--
s[i]=p; (s[i]为i层探索的最后一个节点,最后需要在这之后插入x)
last = p->forward[0] //判断是否相等,。。。。
//插入数据,重连链表
if(newlevel>level) level = newlevel
for i(newlevel-1 - 0)
node->forward[i]= s[i]->forward[i]
s[i]->forward[i] = node
我定义一个随机决策模块,它的大致内容如下,但是这个代码不能保证完全随机,其实每次的运行结果都是一样的:
int getInsertLevel()
{
int upcount = 0;
for(int i=0;i<MAXLEVEL;i++)
{
int num = rand()%10;
if(num<5)
{
upcount++;
}
}
return upcount;
}
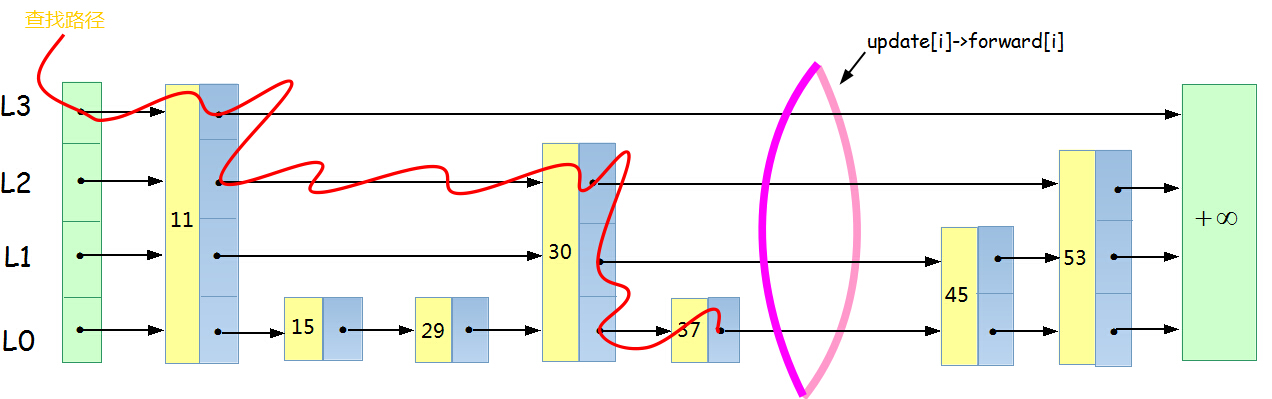
如插入43,查找路径如下。
43的下一个数接到的40下一个数45。
40的下一个数接到43
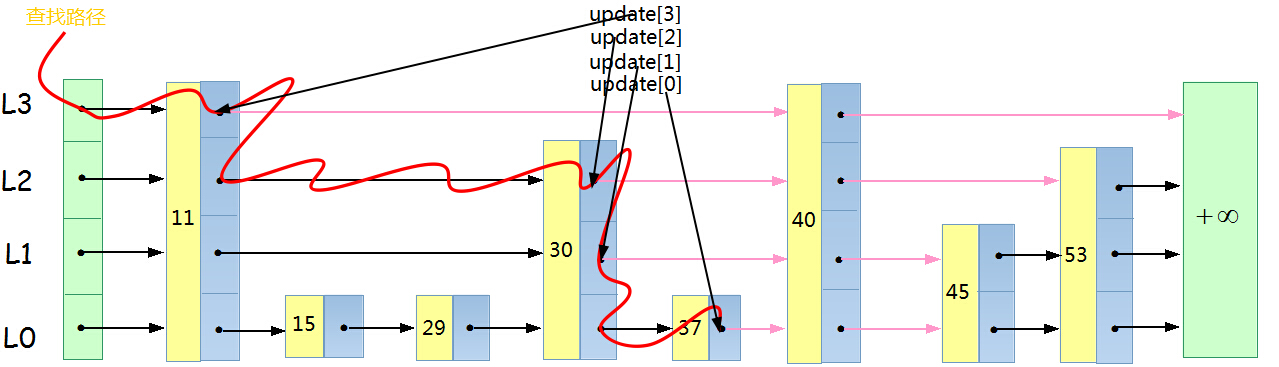
紫色的箭头表示更新过的指针
int SkipList::insert(int key)
{
int level = getInsertLevel();
SKNode* node = new SKNode;
node->key=key;
SKNode *s[MAXLEVEL];
SKNode* current = new SKNode;
SKNode* last = new SKNode;
for(int i =0;i<MAXLEVEL;i++)
{
s[i]=hdr->forward[i];//initiation
}
current = last = hdr;
cout<<"hdr"<<hdr->key<<endl;
int i = listLevel-1;
for(;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
s[i] = current;//保存每一层位置上的最后指针的前驱
}
last=current->forward[0];
if(last != NULL && last->key == key)
{
cout<<"inset key:"<<key<<"already existed"<<endl;
return 0;
}
if(level>listLevel)//更新层数
{
listLevel = level;
}
for(int k = 0; k <listLevel;k++)
{
node->forward[k]=s[k]->forward[k];
s[k]->forward[k]=node;
}
if(level>listLevel)
{
listLevel = level;
}
return 1;
} 跳跃链表的删除
目的:从跳跃表中删除一个元素x
删除链表和插入几乎一模一样的,只是在最后重接链表不同:
在跳跃表中查找到这个元素的位置,如果未找到,则退出
否则将该元素所在整列从表中删除
将多余的“空链”删除
Skip List Deletion(x)
p = hdr;
//newlevel = getlevel();
s[listLevel] = hdr(注意需要全部初始化为hdr,为了newlevel增长了,但是增长的层次s[i]却没有数据,没有初始化,应该从头结点开始)
fori(listLevel-1, 0)
while(q!=+∞ && x>key)
then p = p->forward[i].
//else x<=q.key,
//then i--
s[i]=p; (s[i]为i层探索的最后一个节点,最后需要在这之后插入x)
last = p->forward[0] //判断是否相等,。。。。
if(last->key != x)
return
//删除数据,重连链表
for i(listlevel-1 - 0)
s[i]->forward[i]=s[i]->forward[i]->forward[i];
这段代码如下:
intSkipList::deleteNode(int key)
{
SKNode *s[MAXLEVEL];
SKNode* current = new SKNode;
SKNode* last = new SKNode;
for(inti =0;i<MAXLEVEL;i++)
{
s[i]=hdr->forward[i];//initiation
}
current = last = hdr;
for(inti = listLevel-1;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
s[i] = current;//保存每一层位置上的最后指针的前驱
}
last=current->forward[0];
if(last->key != key)
{
cout<<"delete key:"<<key<<"does not existed"<<endl;
return 0;
}
for(inti = 0; i<listLevel;i++)
{
s[i]->forward[i]=s[i]->forward[i]->forward[i];
}
return 1;
}
整个C++程序如下
#include <iostream>
#include <vector>
using namespace std;
#define MAXLEVEL 4 //最多2 power n=16个数
/*skip list node,they are keys and pointers*/
classSKNode
{
public:
int key;
SKNode* forward[MAXLEVEL];
SKNode()
{
key=0;
for(inti =0;i<MAXLEVEL;i++)
{
forward[i]= NULL;
}
}
SKNode& operator=(constSKNode* & node)
{
key=node->key;
for(inti=0;i<MAXLEVEL;i++)
{
forward[i] = node->forward[i];
}
return *this;
}
};
//skip list, it has a header, this header have maxlevel pointers
classSkipList
{
public:
SKNode *hdr; /* list Header */
intlistLevel; /* current level of list */
int insert(int key);
SKNode* search(int key);
intdeleteNode(int key);
voidprintList();
SkipList()
{
hdr = new SKNode;
listLevel = 0;
hdr->key = -INT_MAX;
SKNode* end = new SKNode;
SKNode* first = new SKNode;
first->key=-INT_MAX;
end->key=INT_MAX;
for(inti =0;i<MAXLEVEL;i++)
{
hdr->forward[i]=first;
hdr->forward[i]->forward[i] = end;
}
printList();
}
~SkipList()
{
deletehdr;
}
};
intgetInsertLevel()
{
intupcount = 0;
for(inti=0;i<MAXLEVEL;i++)
{
intnum = rand()%10;
if(num<5)
{
upcount++;
}
}
returnupcount;
}
SKNode* SkipList::search(int key)
{
SKNode* current = new SKNode;
current = hdr;
inti = listLevel-1;
for(;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
//否则i--,转到下一层
}
current = current->forward[0];
if(current!= NULL && current->key == key)
{
cout<<"find"<<key<<endl;
return current;
}
return NULL;
}
intSkipList::insert(int key)
{
int level = getInsertLevel();
SKNode* node = new SKNode;
node->key=key;
SKNode *s[MAXLEVEL];
SKNode* current = new SKNode;
SKNode* last = new SKNode;
for(inti =0;i<MAXLEVEL;i++)
{
s[i]=hdr->forward[i];//initiation
}
current = last = hdr;
cout<<"hdr"<<hdr->key<<endl;
inti = listLevel-1;
for(;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
s[i] = current;//保存每一层位置上的最后指针的前驱
}
last=current->forward[0];
if(last != NULL && last->key == key)
{
cout<<"inset key:"<<key<<"already existed"<<endl;
return 0;
}
if(level>listLevel)//更新层数
{
listLevel = level;
}
for(int k = 0; k <listLevel;k++)
{
node->forward[k]=s[k]->forward[k];
s[k]->forward[k]=node;
}
if(level>listLevel)
{
listLevel = level;
}
return 1;
}
intSkipList::deleteNode(int key)
{
SKNode *s[MAXLEVEL];
SKNode* current = new SKNode;
SKNode* last = new SKNode;
for(inti =0;i<MAXLEVEL;i++)
{
s[i]=hdr->forward[i];//initiation
}
current = last = hdr;
for(inti = listLevel-1;i>=0;i--)
{
while(current->forward[i]->key != INT_MAX && key>current->forward[i]->key)//key大于下一个数据的值。转到本层下一个元素
{
current = current->forward[i];
}
s[i] = current;//保存每一层位置上的最后指针的前驱
}
last=current->forward[0];
if(last->key != key)
{
cout<<"delete key:"<<key<<"does not existed"<<endl;
return 0;
}
for(inti = 0; i<listLevel;i++)
{
s[i]->forward[i]=s[i]->forward[i]->forward[i];
}
return 1;
}
voidSkipList::printList()
{
SKNode* current = hdr;
for(inti = listLevel -1;i>=0;i--)
{
current = hdr->forward[i];
cout<<"level "<<i<<"................................"<<endl;
while(current->forward[i] != NULL)//key大于下一个数据的值。转到本层下一个元素
{
cout<<" "<<current->key;
current = current->forward[i];
}
cout<<" "<<current->key<<endl;
}
}
int main()
{
SkipListsk;
constint n = 7;
intnum[n]={30,15,45,37,11,53,17};
cout<<"test insert............."<<endl;
for(inti = 0;i<n;i++)
{
sk.insert(num[i]);
}
sk.printList();
cout<<"test search............"<<endl;
sk.search(17);
cout<<"test delete................."<<endl;
sk.deleteNode(30);
sk.printList();
system("pause");
return 0;
}
跳跃链表的搜索时间复杂度为O(logn)
定理:n个元素的跳跃链表的每一次搜索的时间复杂度有很高的概率为O(logn).
高概率:事件E以很高的概率发生意味着对于a>=1,存在一个合适的常数使得事件E发生的概率Pr{E}>=1-O(1/n^a).
其中a是任意选择的一个数,不同的a影响搜索时间复杂度的常数,即a*O(logn),这个在后面介绍.
我们要证跳跃链表的时间复杂度,不能只是证明一次搜索的复杂度为,是要证明全部的搜索都是O(logn),因为这是基于概率的算法,如果光一次有效率并没有多大作用.
我们定义时间Ei为某一次搜索失败的概率,那么假设k次搜素,我们先假定失败的概率为O(1/n^a),其中至少有一次失败的概率为
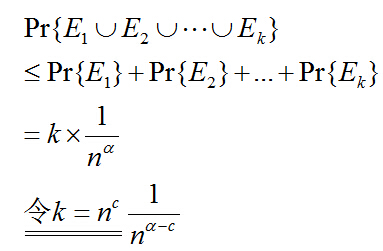
可以估算出k次有一次失败的概率为1/n^(a-c),那么我们只要让a>=c+1或者a取无穷大,就可以证明每一次搜索都具有高概率成功。


















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









