







 本文详细介绍了Hadoop的分布式文件系统HDFS的原理,包括其高吞吐量访问、高容错性和线性扩展能力。讲解了HDFS的架构,包括NameNode、Secondary NameNode和DataNode的角色。还深入解析了HDFS的读写操作流程,并列举了常用HDFS命令。此外,通过3个测试例子展示了HDFS的实战应用,包括读取、写入和文件系统交互。
本文详细介绍了Hadoop的分布式文件系统HDFS的原理,包括其高吞吐量访问、高容错性和线性扩展能力。讲解了HDFS的架构,包括NameNode、Secondary NameNode和DataNode的角色。还深入解析了HDFS的读写操作流程,并列举了常用HDFS命令。此外,通过3个测试例子展示了HDFS的实战应用,包括读取、写入和文件系统交互。
【注】该系列课程是应邀实验楼整理编写的,这里需要赞一下实验楼提供了学习的新方式,可以边看博客边上机实验,课程地址为 https://www.shiyanlou.com/courses/237
1 环境说明
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
- 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
- JDK:1.7.0_55 64位
- Hadoop:1.1.2
2 HDFS原理
HDFS(Hadoop Distributed File System)是一个分布式文件系统,是谷歌的GFS山寨版本。它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
- 高吞吐量访问:HDFS的每个Block分布在不同的Rack上,在用户访问时,HDFS会计算使用最近和访问量最小的服务器给用户提供。由于Block在不同的Rack上都有备份,所以不再是单数据访问,所以速度和效率是非常快的。另外HDFS可以并行从服务器集群中读写,增加了文件读写的访问带宽。
- 高容错性:系统故障是不可避免的,如何做到故障之后的数据恢复和容错处理是至关重要的。HDFS通过多方面保证数据的可靠性,多份复制并且分布到物理位置的不同服务器上,数据校验功能、后台的连续自检数据一致性功能都为高容错提供了可能。
- 线性扩展:因为HDFS的Block信息存放到NameNode上,文件的Block分布到DataNode上,当扩充的时候仅仅添加DataNode数量,系统可以在不停止服务的情况下做扩充,不需要人工干预。
2.1 HDFS架构
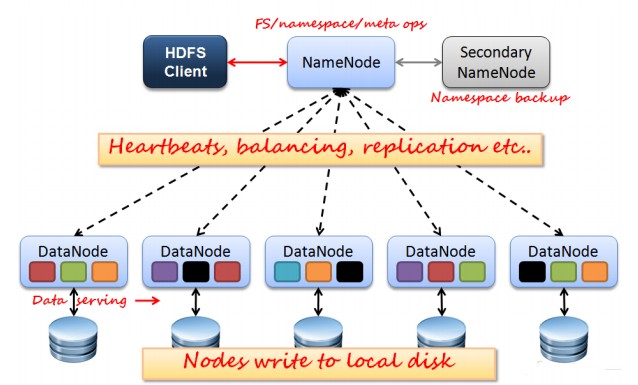
如上图所示HDFS是Master和Slave的结构,分为NameNode、Secondary NameNode和DataNode三种角色。
- NameNode:在Hadoop1.X中只有一个Master节点,管理HDFS的名称空间和数据块映射信息、配置副本策略和处理客户端请求;
- Secondary NameNode:辅助NameNode,分担NameNode工作,定期合并fsimage和fsedits并推送给NameNode,紧急情况下可辅助恢复NameNode;
- DataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode;
2.2 HDFS读操作
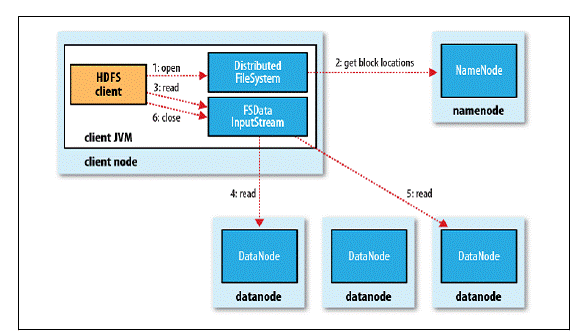
- 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象时分布文件系统的一个实例;
- DistributedFileSystem通过使用RPC来调用NameNode以确定文件起始块的位置,同一Block按照重复数会返回多个位置,这些位置按照Hadoop集群拓扑结构排序,距离客户端近的排在前面;
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流,客户端对这个输入流调用read()方法;
- 存储着文件起始块的DataNode地址的DFSInputStream随即连接距离最近的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端;
- 到达块的末端时,DFSInputStream会关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode,这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流;
- 一旦客户端完成读取,就对FSDataInputStream调用close()方法关闭文件读取。
2.3 HDFS写操作
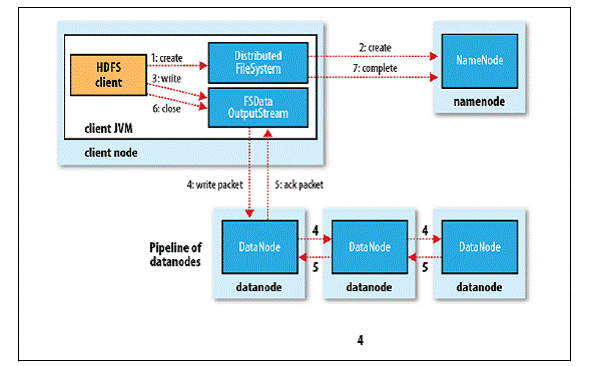
- 客户端通过调用DistributedFileSystem的create()方法创建新文件;
- DistributedFileSystem通过RPC调用NameNode去创建一个没有Blocks关联的新文件,创建前NameNode会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode会为创建新文件记录一条记录,否则就会抛出IO异常;
- 前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调NameNode和Datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
- DataStreamer会去处理接受Data Queue,它先问询NameNode这个新的Block最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的DataNode,把他们排成一个pip
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









